第1章 Forthの哲学¶
Forthは言語とオペレーティングシステムです。しかしそれだけではありません。 それは哲学の具現化でもあります。Forthと哲学は不可分の存在です。 Forth以前にはこのようなことはありませんでした。 かつてこのような議論が行われたのはForthのみです。
哲学とは一体何でしょうか? ソフトウェアの問題を解決するためにそれをどのように適用できるのでしょうか?
これらの質問に答える前に、ちょっと寄り道して、 コンピュータ科学者によって長年研究されてきた主要な哲学の幾つかを調べてみましょう。 これらの進歩の軌跡を辿ったあと、 これら最先端のプログラミング原則とForthを比較対照します。
ソフトウェアの優雅さ昔話¶
むかしむかし、プログラミング原始時代、コンピュータが恐竜であったとき、幾人かの天才があるプログラムを正しく走らせる事ができるという稀有な事例は、大いなる驚きをもって迎えられました。コンピュータが文明化するにつれて驚きは薄れ、経営陣はプログラマと、プログラマの作ったプログラムにより多くを求めるようになりました。
ハードウェアのコストが着実に低下するにつれて、ソフトウェアのコストは急上昇しました。 もはやプログラムが正しく実行されるに十分なコストが賄えなくなりました。 ソフトウェアを迅速に開発し容易に維持しなければなりませんでした。 新しい需要は正確さにスポットライトを当てはじめました。 欠けている品質は「優雅さ」と呼ばれました。
この節では、より優雅なプログラムを書くための、 道具とテクニックの歴史についておおまかに紹介します。
おぼえやすさ¶
最初のコンピュータプログラムは以下のようなものでした。
00110101
11010011
11011001
プログラマは一連のスイッチをセットすることによってこれらのプログラムを入力しました。 数字が「1」の場合は「スイッチオン」、「0」の場合は「スイッチオフ」です。 これらの数値はコンピュータのための「機械語」で、そしてそれがコンピュータに 「内容またはレジスタBをレジスタAに移動しろ」とか 「レジスタCの内容をレジスタAの内容に追加しろ」とかの ありふれた操作を実行させました。
これは少々退屈です。
そして退屈は発明の継母です。幾人かの賢いプログラマはコンピュータ自体に その助けさせることができる事に気づきました。 そこで、彼らは覚えやすい略語を 覚えにくいビットパターンに翻訳するプログラムを書きました。 その新しい言語は以下のようになりました。
MOV B,A
ADD C,A
JMC REC1
翻訳プログラムは「アセンブラ」と呼ばれ、 その新しい言語は「アセンブリ言語」と呼ばれました。 各命令はその命令にふさわしいビットパターンをアセンブリ命令と機械命令との間で 1対1の対応で「組み立て(assembled)」ました。 ビットパターンと違って名前ならプログラマにとって覚えやすい。 このためアセンブリ命令は「ニーモニック(記憶術)」と呼ばれていました。
パワー¶
アセンブリ言語プログラミングは、 プログラマが入力する各命令と プロセッサが実行する各命令が1対1で対応しているのが特徴です。
実際には、プログラマはプログラムの様々な部分で、 同じ事をするために同じ「シーケンス(連なり)」の命令群を しばしば繰り返し使いました。 同じ事をする同じシーケンスには名前を付けると素敵な気がします。
この要望は、通常の命令だけでなく特別な名前(「マクロ」)も認識できる、 より複雑なアセンブラである「マクロアセンブラ」によって満たされました。 マクロアセンブラは名前があるたびに、 まるでプログラマが書き込んだかのように名前で表される複数の機械命令を組み立てます。

図 1 GOTO 500って打ち込んだら、ここに来ちゃったんだ!
抽象化¶
大きな進歩は「高級言語」の発明でした。これもまた翻訳プログラムですが、 より強力なものでした。 高級言語ではプログラマ以下のようなコードを書くことができます。
X = Y (456/A) - 2
まるで算数のようです。高級言語のおかげで、 ビット野郎だけでなく技術者もプログラムを書けるようになりました。 高級言語の例としてはBASICやFORTRANがあります。
高級言語は、各命令が数十の機械語命令をコンパイルするという意味で、アセンブリ言語より明らかに「強力」です。 しかしさらに重要なことに、高級言語はソースコードと結果として得られる機械語命令との間の直線形な対応を取り除きます。
実際の命令はソースコード全体の中にある各「ステートメント」に依存します。 + や = のような演算子はそれ自身では意味を持ちません。これらは構文と、ステートメントの演算子の位置によって意味が異なる複雑な記号の一部に過ぎません。
ソースコードとオブジェクトコードとの間の、直線形でない対応は、プログラミング技術論の進歩における非常に貴重なステップであると考えられています。しかし、よく目にするように、このアプローチは結局はその自由よりも多くの制約をもたらします。
管理しやすさ¶
ほとんどのコンピュータプログラムは、単に最初から最後まで作業するための命令のリスト以上のものが含まれています。 また、さまざまな条件をテストしてから、結果に応じてコードの適切な部分に「分岐」します。 また、コードの同じ区間を繰り返し「ループ」し、通常はループから抜ける瞬間をテストします。
アセンブラと高級言語の両方とも分岐機能とループ機能を提供しています。 アセンブリ言語では「ジャンプ命令」を使いますが、高級言語では「GO TO」命令を使います。 これらの機能を力づくで使うと、プログラムは 図 2 のようにこんがらがります。
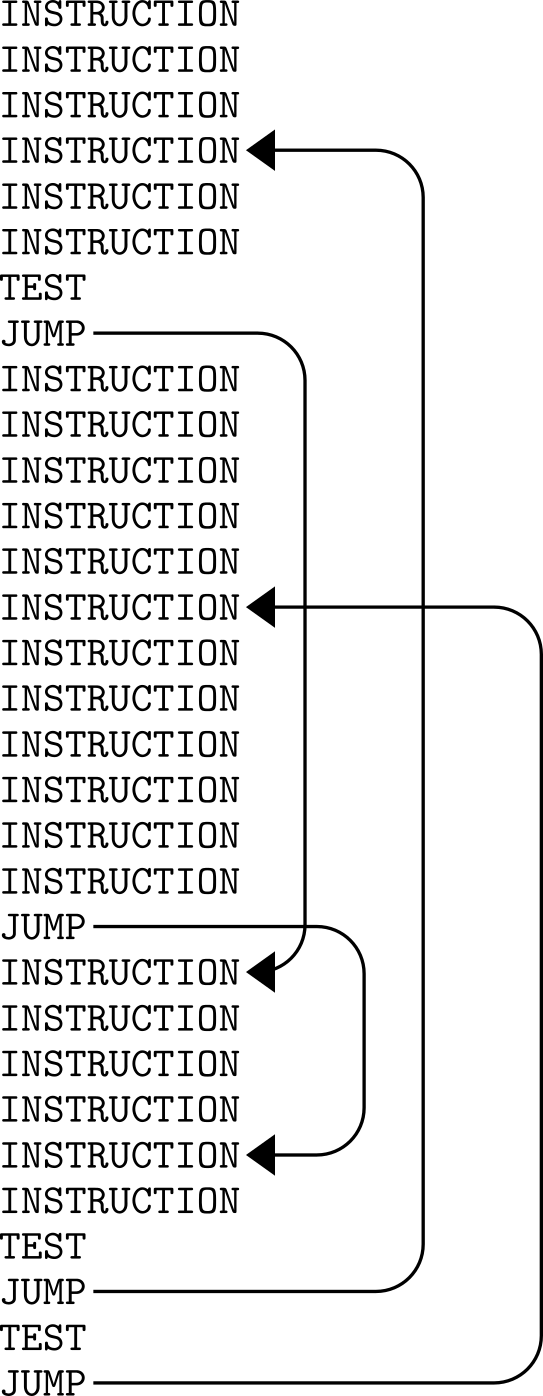
図 2 ジャンプや「GOTO」を使用した非構造化コード
FORTRANやBASICのような言語で未だに広く使われているこのアプローチは、書くのが難しく、修正が必要な場合には変更が難しいという難点があります。 「スパゲッティ」プログラミング教室では、コードの一部を検査したり、実行されるはずのない何かが実行されている様子を把握することは不可能です。
スパゲッティプログラムの難しさは「フローチャート」の発見につながりました。これらは書かれているコードを理解するのを助けるために、プログラマによって使用される、実行の「フロー(流れ)」を表すペンとインクで描かれた図面でした。 残念ながら、プログラマはコードからフローチャートへ手作業による翻訳を行わなければなりませんでした。 多くのプログラマは、古くさいフローチャートをあまり役に立たないと感じました。
モジュール性¶
大きな問題は小さな問題の集まりとして扱うと、より簡単に解決できるという観察に基づく方法論である「構造化プログラミング」の発明によって、大きな進歩が生まれました。 [dahl72] それぞれの部分は「モジュール」と呼ばれます。 プログラムはモジュール内のモジュールで構成されています。
構造化プログラミングは、制御フローをモジュール内で完結させることでスパゲッティコーディングを排除します。 あるモジュールの途中から別のモジュールの途中にジャンプすることはできません。
例えば、 図 3 は4つのサブモジュールからなる「Make Breakfast」モジュールの構造図を示します。 各サブモジュール内には、このレベルでは表示する必要のないまったく新しいレベルの複雑さがあります。
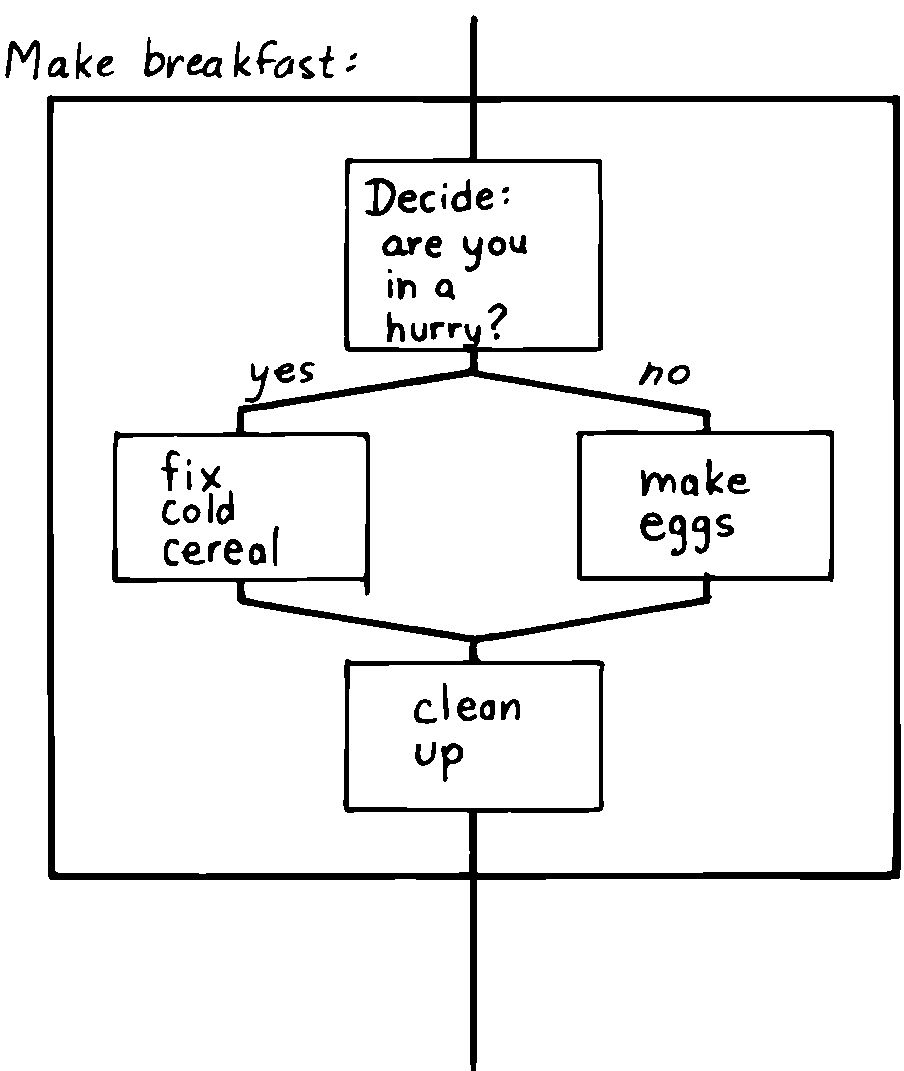
図 3 構造化プログラムの設計
このモジュールでは、「cold cereal」モジュールと「eggs」モジュールのどちらかを選択する分岐決定が行われますが、制御フローは外側のモジュール内にあります。
構造化プログラミングには3つの前提があります。
- すべてのプログラムは「モジュール」と呼ばれる自己完結型関数の直線形シーケンスとして記述されています。 モジュールにはそれぞれ1つの入り口と1つの出口があります。
- 各モジュールは1つ以上の関数で構成され、各関数はそれぞれ1つの入り口と1つの出口を持ち、それ自体モジュールとして記述できます。
- モジュールは以下のものを含む事ができます。
- 演算子や他のモジュール
- 判断構造(
IFやTHEN文) - ループ構造
「入り口1つ出口1つ」モジュールのアイディアは、他のプログラムとの接続を台無しにしなくても、それらを取り外し、内部を変更し、再び差し込むことができるということです。 これは、あなたがそれぞれの部品を単独でテストできることを意味します。 単独のテストは、モジュールを起動したときにどういう状態なのか、そしてモジュールから去った時にどういう状態なのかを正確に知っている場合のみ可能です。
「Make Breakfast」では、シリアル(cereal)を盛るか玉子料理(eggs)を作るかのどちらかを行います。 そして、あなたはいつも片付けるでしょう(私が知っているプログラマの中には、3か月ごとに新しいアパートを借りることによってこの最後のモジュールを行わずに済ませる人もいますが)。
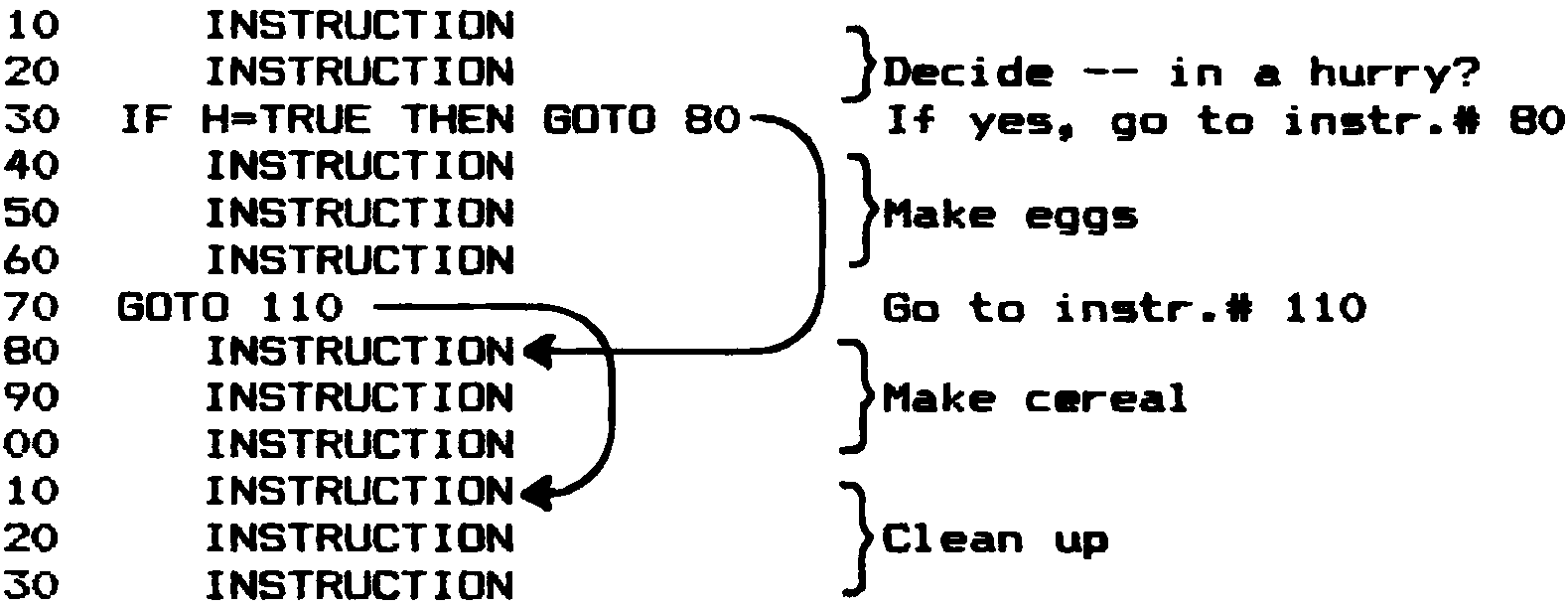
図 4 非構造化言語での構造化プログラミング
構造化プログラミングは、もともと設計アプローチとして考えられていました。 モジュールは、実際のソースコードのユニットではなく、プログラマまたは設計者の頭の中に存在する架空のユニットです。 構造化プログラミング設計技法をBASICのような非構造化言語に適用すると、 図 4 のような結果になります。
書きやすさ¶
さらに別の突破口が構造化プログラムの使用を促進しました。すなわち構造化プログラミング言語です。これらの言語では、命令セットが制御構造を含んでいるので、よりモジュール化した身なりのプログラムを書くことができます。Pascalはそのような言語で、構造化プログラミングの原則を学生に教えるためにNiklaus Wirthによって考案されました。

図 5 構造化言語の使用
図 5 はこのタイプの言語で書いた「Make Breakfast」です。
構造化プログラミング言語は、制御フローのモジュール性を確保するために、 IF や THEN のような制御構造演算子を含みます。 ご覧のとおり、インデント(字下げ)は読みやすくするのに重要です。 なぜなら、各モジュール内の命令群は1つの名前で参照されるのではなく、ただつらつらと書き連ねられているからです(たとえば、右の波括弧「MAKE-CEREAL」の部分)。完成したプログラムは5ページ目に ELSE を付けて、10ページに渡るものになるかもしれません。
頂上からの設計作業¶
これらのモジュールをどのように設計すればいいでしょうか? 「トップダウン設計」と呼ばれる方法論は、頂上(トップ)の最も一般的で全体的なモジュールから始めて、そこから下り、核心のモジュールに至るまで設計する必要があるとしています。
トップダウン設計の支持者は、計画不足のために恥ずべき時間の浪費を目撃しています。 彼らは苦しい経験から、プログラムの作成後にプログラムを修正しようとすること(「パッチあて」として知られる方法)は、馬が暴れて逃げ出した後に納屋の扉を施錠するようなものだと学びました。
そこで彼らは、対策として以下のトップダウンプログラミング公式規則を提案します。
最後の詳細をすべて計画するまでコードを書かないでください。
プログラムは一度書いてしまうと変更するのが難しいので、実際のコードレベルのモジュールを作成する前に、事前計画段階での設計もれはすべて明らかにしておく必要があります。 トップダウン設計によれば、そうでなければ、使用できないゴミなコードを書くのに多大な人月が浪費される可能性があります。

図 6 ソフトウェアパッチは醜く、構造的な弱点を含んでいます。
サブルーチン¶
私たちは抽象的なモジュールとして「モジュール」を議論してきました。 しかし、すべての高級言語には、設計のモジュールをコードのモジュール、つまり名前を付けて他のコードから「呼び出す」ことができるコード・モジュールとしてコーディングできるようにする技法が組み込まれています。 これらのユニットは、特定の高級言語および実装方法に応じて、サブルーチン(subroutine)、プロシージャ(procedure)、または関数(function)と呼ばれます。
サブルーチンとして「MAKE-CEREAL」を書くと以下のようになります。
procedure make-cereal
get clean bowl
open cereal box
pour cereal
open milk
pour milk
get spoon
end
サブルーチンとして MAKE-EGGS や CLEANUP を書くこともできます。他方、 MAKE-BREAKFAST は、単一のルーチンとして定義することもできますし、これらのサブルーチンを呼び出すこともできます。
procedure make-breakfast
var h: boolean (indicates hurried)
&textit{test for hurried}
if h = true then
&textbf{call make-cereal}
else
&textbf{call make-eggs}
end
&textbf{call cleanup}
end
「call make-cereal」というフレーズは「make-cereal」という名前のサブルーチンを実行します。サブルーチンの実行が完了すると制御が戻ってきて「call make-cereal」の次の行の実行を開始します。サブルーチンは構造化プログラミングの規則に従います。
ご覧のとおり、サブルーチン呼び出しの効果は、サブルーチンコードが呼び出し元のモジュール内で完全に書き込まれたかのようです。 しかし、マクロアセンブラによって生成されたコードとは異なり、サブルーチンはメモリ内の他の場所でコンパイルされ、参照されるだけのことがあります。 必ずしもメインプログラムのオブジェクトコード内でコンパイルされる必要はありません。( 図 7 )
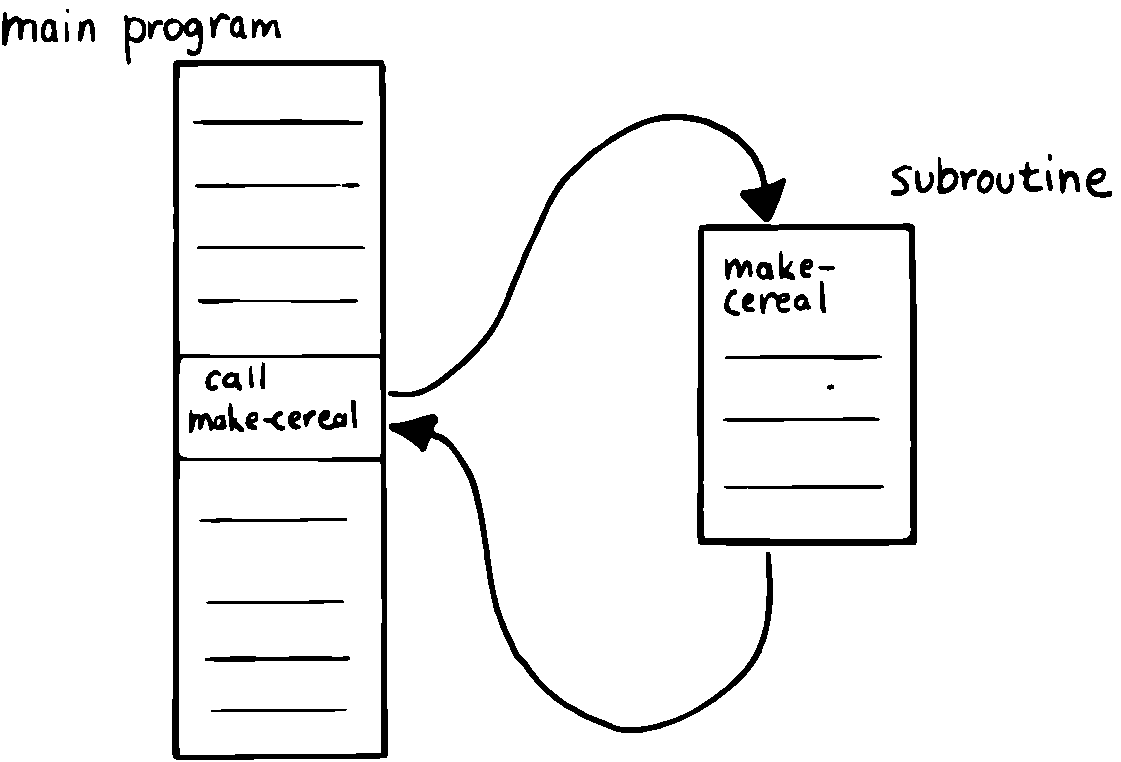
図 7 メモリ内のメインプログラムとサブルーチン
何年にもわたって、コンピュータ科学者は、長くはてしないプログラムよりも、多くの小さなサブルーチンの使用を強く推奨しています。 サブルーチンは独立して書いてテストすることができます。 これにより、以前に作成したプログラムの一部を再利用しやすくなり、プログラムのさまざまな部分をさまざまなプログラマに割り振るのが容易になります。 コードが小さいほど、考えるのが簡単になり、正確さを検証するのが容易になります。
サブルーチンがメモリの別の部分でコンパイルされて参照されると、繰り返されるオブジェクトコードがスペースを無駄にすることなく、プログラム全体を通して同じサブルーチンを何度も呼び出すことができます。 したがって、サブルーチンを思慮深く使用すると、プログラムサイズも小さくなります。
残念ながら、サブルーチンを使用すると実行速度が低下します。 1つの問題は、サブルーチンにジャンプして後でそれらを復元する前にレジスタを保存する際のオーバーヘッドです。 さらに時間がかかるのは、サブルーチンとの間でパラメータをやり取りするのに必要な、目に見えないが重要なコードです。
サブルーチンは、どのようにしてそれらを呼び出すのか、特にどのようにしてそれらとの間でデータをやり取りするのかについては神経質です。 それらを独立してテストするには、それらを呼び出すための特別なテストプログラムを書く必要があります。
これらの理由から、コンピュータ科学者は適度の数の使用を推奨します。 実際は、サブルーチンの長さは大きめで、半ページから1ページの長さになります。
継続的改良¶
サブルーチンに大きく依存しているこのアプローチは「継続的改良」と呼ばれています。 [wirth71] そのアイデアでは、データ構造の手続きのために自然な名前を使った骨格バージョンの記述から始めます。次に、名前付き手続きのそれぞれの説明を書きます。 手続きがコンピュータ言語自体でしか記述できなくなるまで、この処理を詳細レベルまで続けます。
各ステップで、プログラマは使用するアルゴリズムと、それに伴うデータ構造について決定を下さなければなりません。 アルゴリズムと関連するデータ構造に関する決定は、並行して行われるべきです。
アプローチがうまくいかない場合は、プログラマは必要な範囲で後戻りしてやり直すことをお勧めします。
継続的改良は、最低レベルのコンポーネントが作成されるまで、プログラムのどの部分も実際には実行できないことに注意してください。 通常、これは完全に設計が完了するまでプログラムをテストできないことを意味しています。
継続的改良は、次の、より詳細なレベル進む前に各レベルでの制御構造の詳細を全て解決しなければならない事にも注意して下さい。
図 8 トビアス、このモジュールの継続的改良はそのぐらいでいいんじゃないか?
構造化設計¶
コンピュータ業界は70年代後半までに、いままで説明した概念を全て試していましたが、それでもまだ不幸でした。ソフトウェアを維持し、変化に直面しても機能するように維持するためのコストは、ソフトウェアの総コストの半分以上を占めていました。なんと、幾つかの見積もりではそれは90%に達しました。
これら無残な状況は、一般に、プログラムの分析が不完全だったか、よく考えられてない設計が原因と考えられると言うことに、誰もが同意したものです。構造化プログラミング「それ自体」には何か問題があったわけではありませんが、プロジェクトの遅延や不完全や不正確に際しては、設計者は思いもかけず責任を取るはめになりました。
学者たちは当然、設計にもっと重点を置くべきだと答えました。「次回はもっとよく考えましょう」と。
この頃、「構造化設計」 [stevens74-1] という記事で説明されている、新しい原則ができました。 その原則の1つがこれです。
シンプルさは、デバッグおよび変更時間の短縮と比較して代替設計を評価するために推奨される主要な尺度です。システムの他の部分に最小限の考慮で済むかあるいは全く影響を与えることなく、部分を考え、実装し、修正し、変更することができるようにシステムを別々の部分に分割することによって、シンプルさを高める事ができます。
問題をシンプルなモジュールに分割することによって、プログラムは書きやすく、変更しやすく、そして理解しやすくなると期待されました。
しかし、モジュールとは一体何でしょうか? どのような基準で分割するのでしょうか? 「構造化設計」ではモジュール設計の3つの要因について概説します。
機能的強度¶
1つ目の要因は「機能強度」と呼ばれるもので、これはモジュール内のすべての文の目的の統一度という尺度です。 モジュール内のすべての文をまとめて1つのタスクを実行すると見なすことができる場合、それらは機能的に結合されています。
一般に、モジュール内の文が機能的に結合されているかどうかは、以下の質問をすることでわかります。 まず最初に、その目的を一文で説明できますか。 そうでなければ、モジュールはおそらく機能的に結合されていません。 次に、モジュールについて次の4つの質問をします(訳注:もちろん英語での話)。
- 説明文は複合文である必要はありますか?
- 「最初(first)」、「次(next)」、「それから(then)」など、時間を伴う言葉を使用していますか?
- 動詞(verb)の後に一般の目的語(general object)や間接目的語(nonspecific object)を使用しますか?
- 同時に多くの異なる機能が実行されることを意味する、「初期化(initialize)」のような言葉が使われていませんか?
これら4つの質問の答えのいずれかが「はい」の場合、あなたの目の前にあるのは機能的な結合よりも結合度が少ないタイプの結合です。これら弱い結合形式は以下のとおりです。
- 偶然の結合
- (これらの文はなぜか知らないが、たまたま同じモジュールにある)
- ロジック結合
- (モジュールにはいくつかの関連する機能があり、どの機能を実行するかを決定するためにフラグまたはパラメーターが必要です)
- テンポラリ結合
- (モジュールには、初期化のような、同時に発生するという以外の関係が無い複数の文が含まれています)
- コミュニケーション結合
- (このモジュールには、同じデータセットを参照する複数の文が含まれています)
- シーケンシャル結合
- (ある文の出力が次の文の入力として機能する場合)
MAKE-CEREAL モジュールは、それがいくつかの従属タスクで構成されているとしても、一つのことをすると考えることができるので、機能的な結合が成り立っていると言えます。
連結¶
構造化設計のもう1つの原則は、「連結」に関するものです。これは、モジュールが他のモジュールの動作にどのように影響するかを示す尺度です。 強い結合は悪い形式と見なされます。 最悪の場合は、あるモジュールが実際に別のモジュール内のコードを変更したときです。 機能を制御する目的で他のモジュールに制御フラグを渡すことさえ危険です。
許容される連結形態は「データ連結」です。これはあるモジュールから別のモジュールへ(制御情報ではなく)データを渡すことを含みます。 それでも、モジュール間のデータインタフェースが可能な限りシンプルな場合、システムの構築と保守は容易です。
データが多くのモジュールからアクセスできる場合(グローバル変数など)は、モジュール間の連結が強くなります。 プログラマが1つのモジュールだけ変更する場合でも、他のモジュールが「副作用」を示すという大きな危険があります。
最も安全な種類のデータ連結は、あるモジュールから別のモジュールへパラメータとしてローカル変数を渡すことです。 呼び出し側のモジュールは、サブルーチンモジュールにこう言います「私がXとYという名前の変数に入れたデータをあなたに使用してもらいたいのです。そして処理が完了したら、あなたが答えをZという名前の変数に答えを入れることを期待します。他の誰もこれらの変数は使いません」。
前述したように、サブルーチンをサポートする従来の言語には、あるモジュールから別のモジュールに引数を渡すための精巧な方法が含まれています。
階層型 入力・処理・出力 設計¶
構造化設計の3番目の教えは設計プロセスに関するものです。 設計者はトップダウンアプローチを使用することをお勧めしますが、最初は制御構造に注意を払わないようにします。 「判断設計」は、後のモジュールの詳細設計まで待つことができます。 代わりに、初期の設計では、プログラムの階層(どのモジュールがどのモジュールを呼び出すのか)と、あるモジュールから別のモジュールへのデータの受け渡しに焦点を当てる必要があります。
設計者がこれらの新しい線に沿って考えるのを助けるために、「構造化チャート」と呼ばれる図法が発明されました(階層型 入力-処理-出力(Hierarchical Input-Process-Output)を表すHIPO図と呼ばれる)。 構造化チャートは、階層図と入出力図の2つの部品を含んでいます。
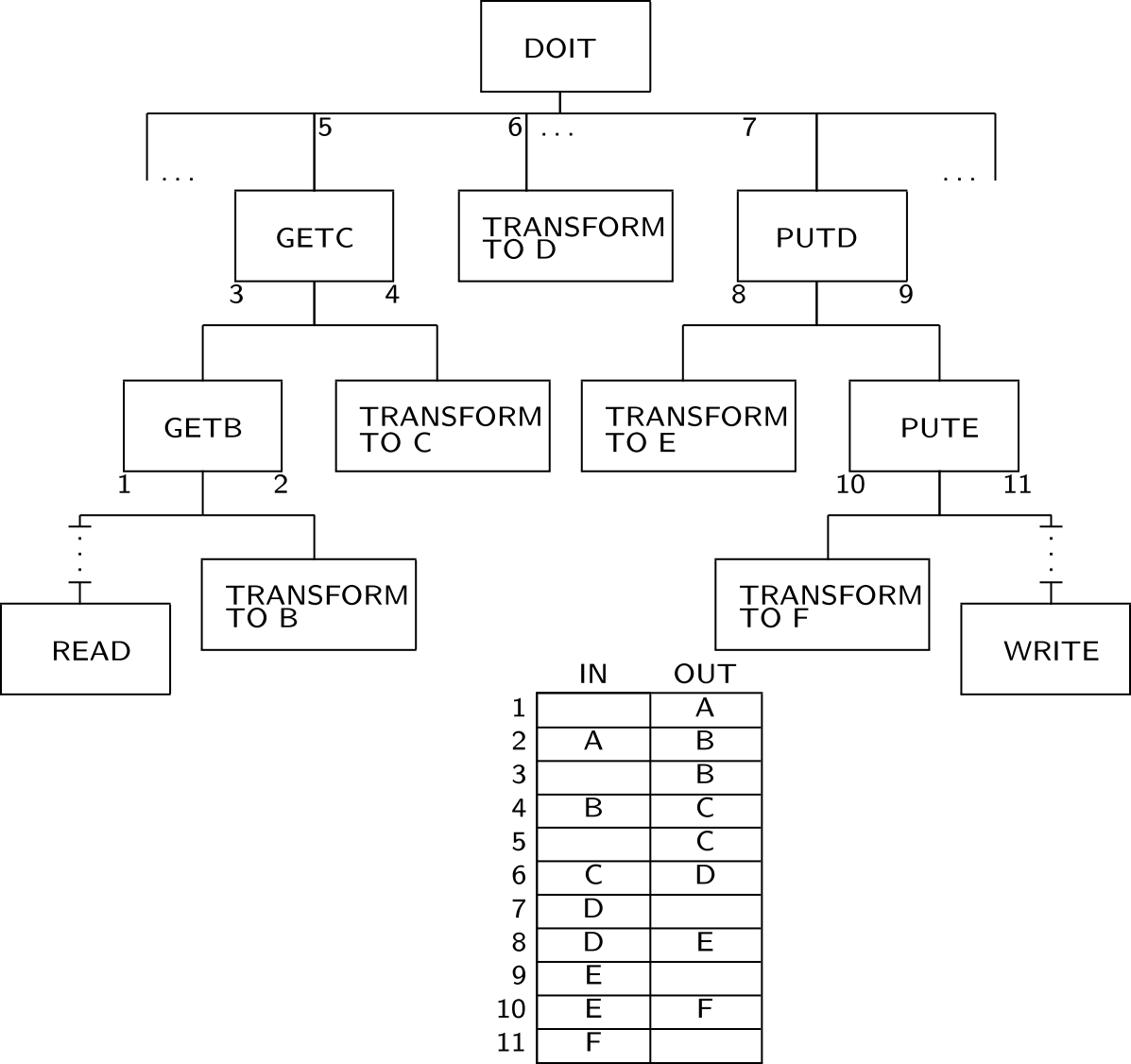
図 9 構造化チャート様式(「構造化デザイン」IBMシステムジャーナル より)
図 9 はこれら二つの部分を示しています。 DOITと呼ばれるメインプログラムは、3つのサブルーチンジュールから構成されています。これらのサブルーチンモジュールは、その下に表示されている他のモジュールを呼び出します。 ご覧のとおり、設計は入力から出力への変換を強調しています。
階層図の小さな番号は、入出力図の行を表します。 ポイント1(モジュールREAD)では、出力は値Aです。ポイント2(モジュールTRANSFORM-TO-B)では、入力はA、出力はBです。
おそらくこのアプローチの最大の貢献は、制御フローに関する決定が設計の重点ではないと認識していることです。 見ての通り、制御フローは問題の表面的な側面です。 要求を少し変更するだけで、プログラムの制御構造が大幅に変わったり、何年にも渡る作業を葬るはめになる可能性があります。 しかし、プログラムがデータの流れなどの他の問題を考慮して設計されている場合、計画の変更はそれほど悲惨な結果にはなりません。
情報隠蔽¶
1972年に出版された論文 [parnas72] で、David L. Parnas博士は次のように述べています。モジュールを分割するための基準は、プロセスのステップであってはなりません。むしろ変更する可能性がある情報の断片であるべきです。モジュールはそのような情報を隠すために使われるべきです。
「情報隠蔽」というこの重要な考え方を見てみましょう。あなたが会社で手順書を書いているとしましょう。 以下はその一部です。
営業部が受注経理部に青いカーボンコピーを送るオレンジ色のカーボンコピーは配送部へジェイは机の上にある赤いバインダーにオレンジ色のカーボンコピーの内容を記録し、梱包票を完成させます
そして、皆がこの手順が正しいことに同意し、あなたが書いた手順書は社内の全員に配布されます。
それからジェイが辞職し、マリリンが引き継ぎました。新しい伝票用紙には青とオレンジではなく緑と黄色の複写があります。赤いバインダーが満杯になったので黒いバインダーに置き換えました。
あなたの手順書はまるごとゴミになってしまいました。「ジェイ」という名前の代わりに「配送係」という用語、「青」や「オレンジ」の代わりに「経理部用コピー」および「配送部用コピー」などの用語を使用することで、陳腐化を回避できた可能性があります。
この例は、変化する環境に直面しても正確性を維持するために、恣意的な詳細を手順から除外するべきであることを示しています。詳細は必要に応じて他の場所に記録することができます。たとえば、都度人事部門が従業員とその役職のリストを発行するなら、配送担当者が誰であるかを知る必要がある人なら誰でもこの単一の情報源で調べることができます。人員が変わると、このリストも変わります。
このテクニックはソフトウェアを書く上で非常に重要です。プログラムが既に実行できているのに、なぜプログラムを変更する必要があるのでしょうか? でも、プログラムを変更する理由は無数にあります。あなたは新しい機器で古いプログラムを走らせたいと思うかもしれません。プログラムを新しいハードウェアに対応させるため変更する必要があるかもしれません。プログラムは充分速くないかもしれません。充分強力ではないかもしれません。それを使用している人々に合わないかもしれません。ほとんどのソフトウェアグループは、自分たちがプログラムの「ファミリー」を書いていることに気づいています。つまり、特定のアプリケーション分野における関連プログラムの多くのバージョンは、それぞれ、それ以前のプログラムの変形です。
情報隠蔽の原則をソフトウェアに適用するには、プログラムの特定の詳細を単一の場所に限定し、有用な情報を一度だけ表現する必要があります。この格言を無視するプログラムは冗長性の罪を犯します。 ハードウェアの冗長性(バックアップコンピュータなど)はシステムをより安全にすることができますが、情報の冗長性は危険です。
知識のあるプログラマなら誰でも言うように、将来のバージョンのプログラムではおそらく変わるかもしれない数は「定数」にして、値ではなく名前でプログラム全体を通して参照する必要があります。 たとえば、コンピュータの用紙の幅を表す列の数は定数として表す必要があります。 アセンブリ言語でも、アドレスやビットパターンなどの値を名前に関連付けるための「EQU」およびラベルを提供しています。
優れたプログラマであれば、情報隠蔽の概念をサブルーチンの開発にも適用して、各モジュールが他のモジュールの内部について可能な限り少ない知識しか持たないようにします。 C、Modula 2、Edisonなどの最新のプログラミング言語は、この概念をプロシージャのアーキテクチャに適用します。
しかし、Parnas博士その考えをもっと先に進めています。 彼はその概念をアルゴリズムとデータ構造に拡張するべきだと提案しています。 実際、意思決定構造や呼び出し階層ではなく、情報を隠すことが設計の主な基盤となるはずです。
構造の表層¶
Parnas博士は分解のための2つの基準を提案します。
- (今現在計画されてないとしても)再利用可能であること。
- (今現在計画されてないとしても)変更可能であること。
この「モジュール」の新しい見方は、従来の見方とは異なります。 この「モジュール」は、通常は非常に小さいルーチンの集まりで、問題のとある面に関する情報をまとめて隠します。
他の2人の作家は、「データ抽象化」 [liskov75] という用語を使用して、同じ考え方を異なる方法で説明しています。 彼らの例はプッシュダウンスタックです。 スタック「モジュール」は、スタックを初期化し、スタックに値をプッシュし、スタックから値をポップし、スタックが空かどうかを判断するためのルーチンで構成されています。 この「マルチプロシージャモジュール」は、スタックがどのように構成されているかの情報をアプリケーションの他の部分から隠します。 これらの手順は相互依存しているため、単一のモジュールと見なされます。 値をポップする方法も変更せずに、値をプッシュする方法を変更することはできません。
この概念では、「使用」という言葉が重要な役割を果たします。 Parnas博士は論文で次のように書いています。 [parnas79]
一定の優雅さを達成したシステム。それはシステムの部品として他の部品を使うことで達成されます。
そのような階層的な順序付けが存在する場合、各レベルではテスト可能で使用可能なシステムのサブセットを提供します。
「使用」階層の設計は、設計作業における主要なマイルストーンの1つです。 システムを独立して呼び出し可能なサブプログラムに分割することは、「使用」に関する決定と並行して行わなければなりません。それらは互いに影響を与えるからです。
モジュールが制御フローまたはシーケンスに従ってグループ化されている設計では設計変更は容易にはできません。 構造は、制御フロー階層では、ある意味表層的なものです。
変更される可能性のあるものに従ってモジュールがグループ化されている設計は、容易に変更に対応することができます。
一方、Forthでは...¶
本節ではForthの基本機能を概説します。そしてそれらを従来の方法論と関連付けます。
以下にForthコードの例があります。
: BREAKFAST
HURRIED? IF CEREAL ELSE EGGS THEN CLEAN ;
これは 図 5 の MAKE-BREAKFAST 手続きと構造的に同じです(Forthを初めて使用する場合は、 付録 A 参照)。 HURRIED? , CEREAL , EGGS , CLEAN というワードも(おそらく)コロン定義として定義されています。
ある程度までは、Forthは私たちが勉強してきたすべての特性をもっています。ニーモニック値、抽象化、パワー、構造化制御演算子、強力な機能結合、限定的な連結、モジュール性。しかし、モジュール性に関してはForthの最も重要な突破口となる可能性があります。
Forthプログラムの最小単位はモジュールでもサブルーチンでもプロシージャでもなく「ワード(word)」です。
更に、サブルーチンやメインプログラムやユーティリティや管理プログラムのメニューはありません。それぞれを別に起動する必要があります。Forthでは全てが「ワード(word)」です。
ワードベースの環境の重要性を探る前に、まずそれを可能にするForthの2つの発明について学習しましょう。
暗黙の呼び出し¶
最初に、呼び出しは暗黙に行います。あなたは CALL CEREAL と書く必要はありません。シンプルに CEREAL でいいです。Forthでは CEREAL の定義は、自身がどんな種類のワードであるか、そして自身を呼び出すためにどのような手続きを使うべきかを「知って」います。
よって、変数や定数やシステム関数やユーティリティ及びユーザ定義のコマンドやデータ構造は全て、シンプルに「名前」で「呼び出す」ことができます。
暗黙のデータ渡し¶
次に、データ渡しは暗黙に行われます。この効果を生み出すメカニズムがForthのデータスタックです。Forthは自動的に数字をスタックにプッシュます。入力として数を必要とするワードは、自動的にそれらをスタックからポップします。出力として数字を生成するワードは自動的にそれらをスタックにプッシュします。 PUSH と POP というワードは高レベルのForthには存在しません。
よって次のように書くことができます。
: DOIT
GETC TRANSFORM-TO-D PUT-D ;
GETC が 'C' を取得し、それをスタックに残して去ると確信しています。そして TRANSFORM-TO-D はスタックから 'C' を取り出し変換して 'D' をスタックに残して去ります。最後に、 PUT-D はスタックから 'D' を取り出しそれを書き込みます。 Forthはコードからデータ渡しの操作を取り除き、データ変換(transform)の機能的なステップに集中できるようにします。
Forthはデータ渡しのためにスタックを使うので、ワードはワードの中に入れ子にすることができます。どんなワードでも、より高いレベルでワード間のデータの流れを混乱させることなく、スタックに数字を入れたり取り除いたりすることができます(もちろん、ワードが予想外の値を消費したり残したりしないことが条件です)。したがって、スタックは、構造化されたモジュール式プログラミングをサポートしながら、ローカル引数を渡す為のシンプルなメカニズムを提供します。
Forthはプログラムから「どのように」ワードが呼び出されるか、「どのように」データが渡されるかの委細を取り除きます。 あるのは問題を説明する「言葉(ワード)」だけです。
言い換えれば、Parnas博士の推奨のとおり、変更される可能性のあるものに従って問題を分解し、それぞれの「モジュール」を、そのモジュールに関する情報を隠すために必要なだけ、多くの小さな機能で構成することができます。Forthではそれがどれほどシンプルであっても必要なだけワードを書くことができます。
典型的なForthアプリケーションの1行はこんなのです。
20 ROTATE LEFT TURRET
他の言語では、単に修飾子として LEFT というサブルーチンを使ったり、単にハードウェアの一部に名前を付けるために TURRET というサブルーチンを使ったりすることを推奨することはまずありません。
Forthのワードはサブルーチンよりも呼び出しが簡単(呼び出すのではなくて単に名前を書くだけ)なので、Forthプログラムは、従来のプログラムをサブルーチンに分割するよりも多くのワードに分割される可能性があります。
コンポーネントプログラミング¶
よりシンプルなワードをたくさん使うことで「コンポーネントプログラミング」という手法を容易に利用できるようになります。詳しく解説するために、まず「変更される可能性のあるもの」として漠然と述べたコレクションについて再検討しましょう。典型的なシステムでは、ターミナルやプリンタなどのI/Oデバイス、UARTチップなどとのインターフェイス、オペレーティングシステム、データ構造やデータ表現、アルゴリズムなどなど、ほとんど全てが変更される可能性があります。
では、そのような変更の影響を最小限に抑えるにはどうすればいいでしょうか? そのようなものと一緒に変更しなければならない他のものとの最小の組み合わせはどれでしょうか?
その答えは「それらがひとまとめに機能する方法についての知識を共有する、相互作用するデータ構造及びアルゴリズムの最小の組み合わせ」です。私たちはこのユニットを「コンポーネント」と呼びます。
コンポーネントは資源です。それはUARTチップやハードウェアスタックなどのハードウェアの一部です。あるいは、コンポーネントは、キュー、辞書、ソフトウェアスタック等のソフトウェア資源です。
すべてのコンポーネントはデータオブジェクトとアルゴリズムを含みます。 データオブジェクトが物理的(ハードウェアレジスタなど)であるか、抽象的(スタックの場所やデータベース内のフィールドなど)であるかは関係ありません。 アルゴリズムが機械語で記述されているか、あるいは CEREAL や EGGS のような問題指向のワードで記述されているかは関係ありません。
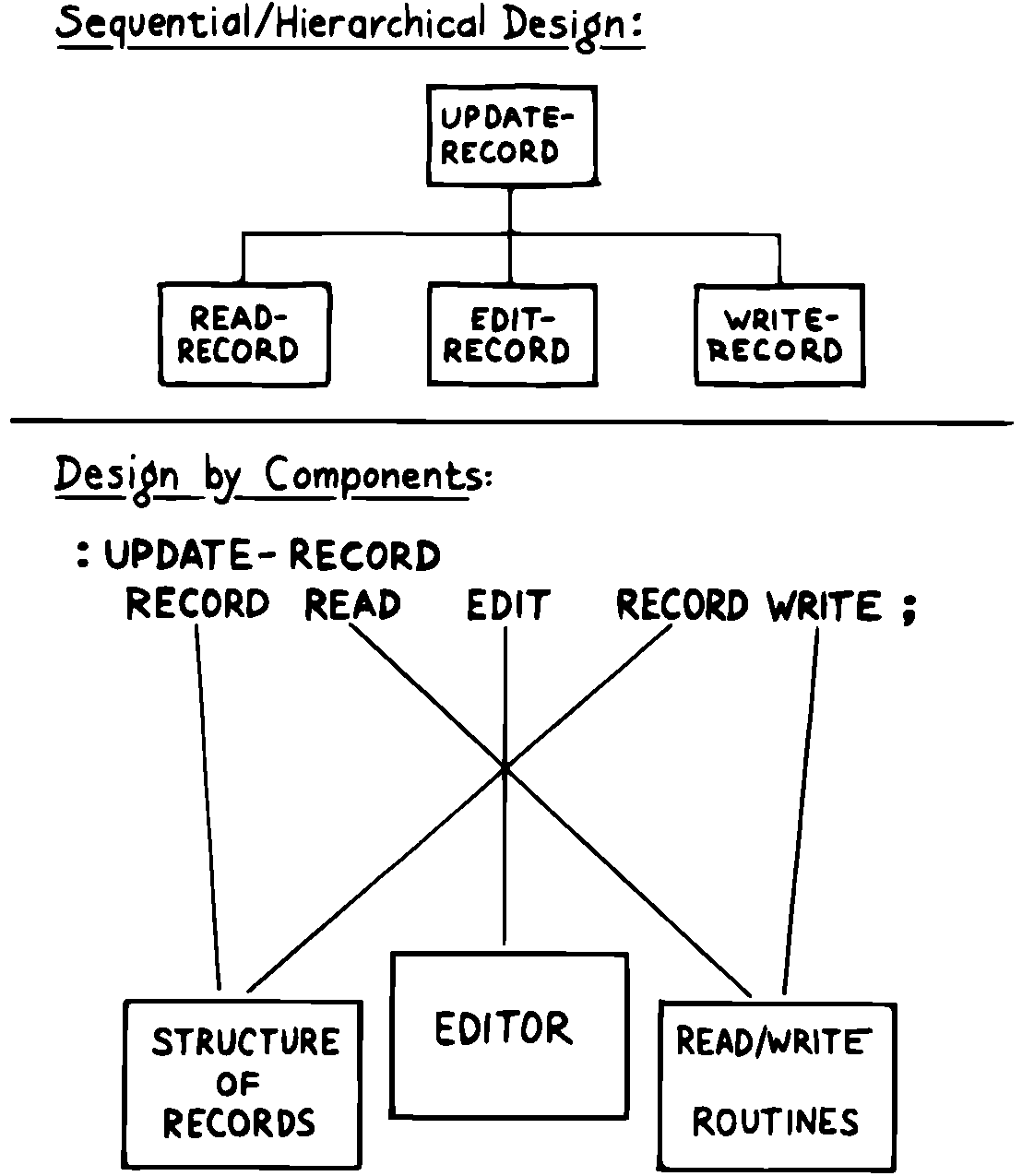
図 10 構造化設計 対 コンポーネント設計
図 10 は構造化設計の結果とコンポーネント設計の結果を対比しています。私たちは READ-RECORD , EDIT-RECORD , WRITE-RECORD と呼ばれる「モジュール」の代わりに、レコードの構造を記述し、エディタコマンドのセットを提供し、ストレージへの読み書きルーチンを提供する、「コンポーネント」に関心があります。
私たちは何をやらかしたのでしょうか? つまり、開発プロセスに新しいステージを追加挿入しました。「設計」でコンポーネントに分解し、それから「実装」でシーケンスと階層と入力・処理・出力について説明しました。はい、たしかにこれは余分なステップですが、スライスだけでなく、さいの目切りするために分解の追加のステージあります。
プログラムが書かれた後に、レコード構造を変更する必要があるとします。 階層設計では、この変更は3つのモジュールすべてに影響します。 コンポーネントによる設計では、変更はレコード構造コンポーネントに限定されます。 このコンポーネントを使用するコードは、変更を知る必要がありません。
この方式の保守以外の利点は、チームのプログラマ同士で相互依存性を少なくして、コンポーネントを個別に割り当てることができることです。 コンポーネントプログラミングの原則は、チーム設計とソフトウェア設計に適用されます。
コンポーネントを説明する単語の集まりを「用語集(lexicon)」と呼びます(用語集の意味は、「特定の分野に関連する単語の集まり」です)。用語集は、コンポーネントと外部とのインターフェイスです( 図 11 )。
この本では、「用語集」という用語は、コンポーネントの外側で名前によって使用されているコンポーネントのワードのみを指します。 コンポーネントは、外部から見える用語集をサポートするためだけに書かれた定義も含むことができます。 このサポートするためだけの定義を「内部ワード」と呼びます。
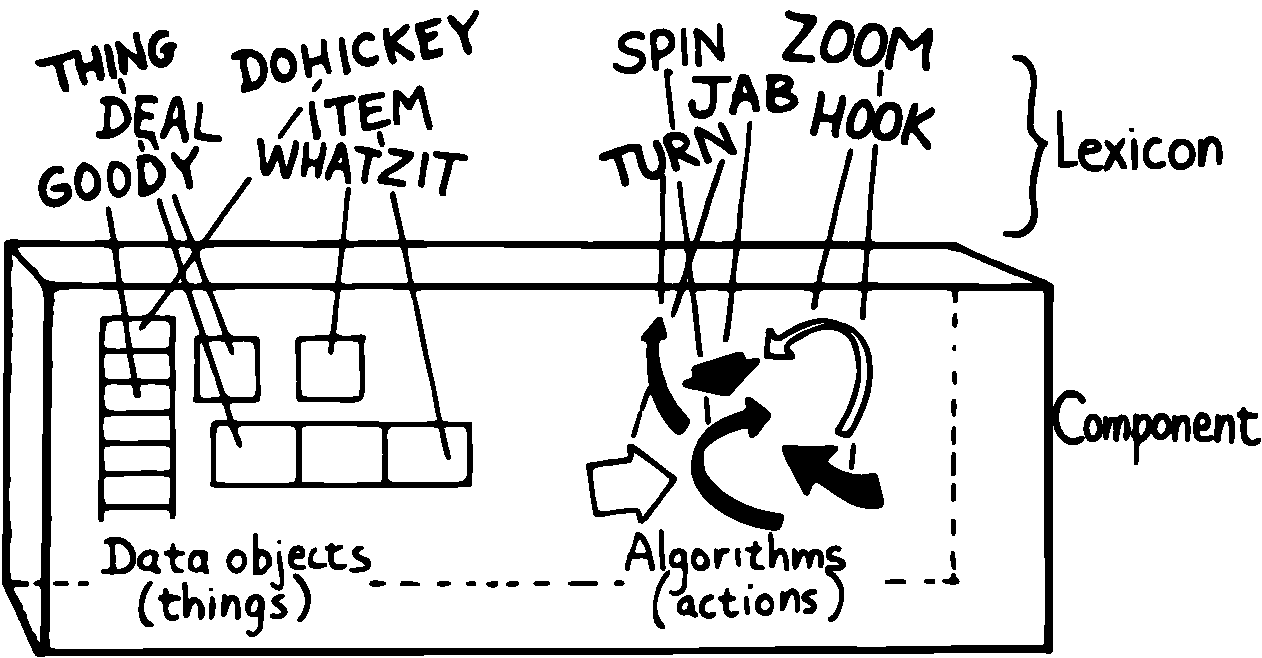
図 11 用語集はコンポーネントを説明する
用語集は、データオブジェクトおよびアルゴリズムと論理的に等価なものを名前で提供します。 用語集は、コンポーネントのデータ構造とアルゴリズム、つまり「どのように動くか」を明らかにしています。それはシンプルなワードで表現されたコンポーネントの「概念モデル」、つまり「動作するもの」のみをコンポーネントの外界に提示します。
これらのワードは、より高いレベルで書かれたコンポーネントのデータ構造とアルゴリズムを記述するための言語になります。 1つのコンポーネントの「何か(what)」は、上位コンポーネントの「どのように(how)」になります。
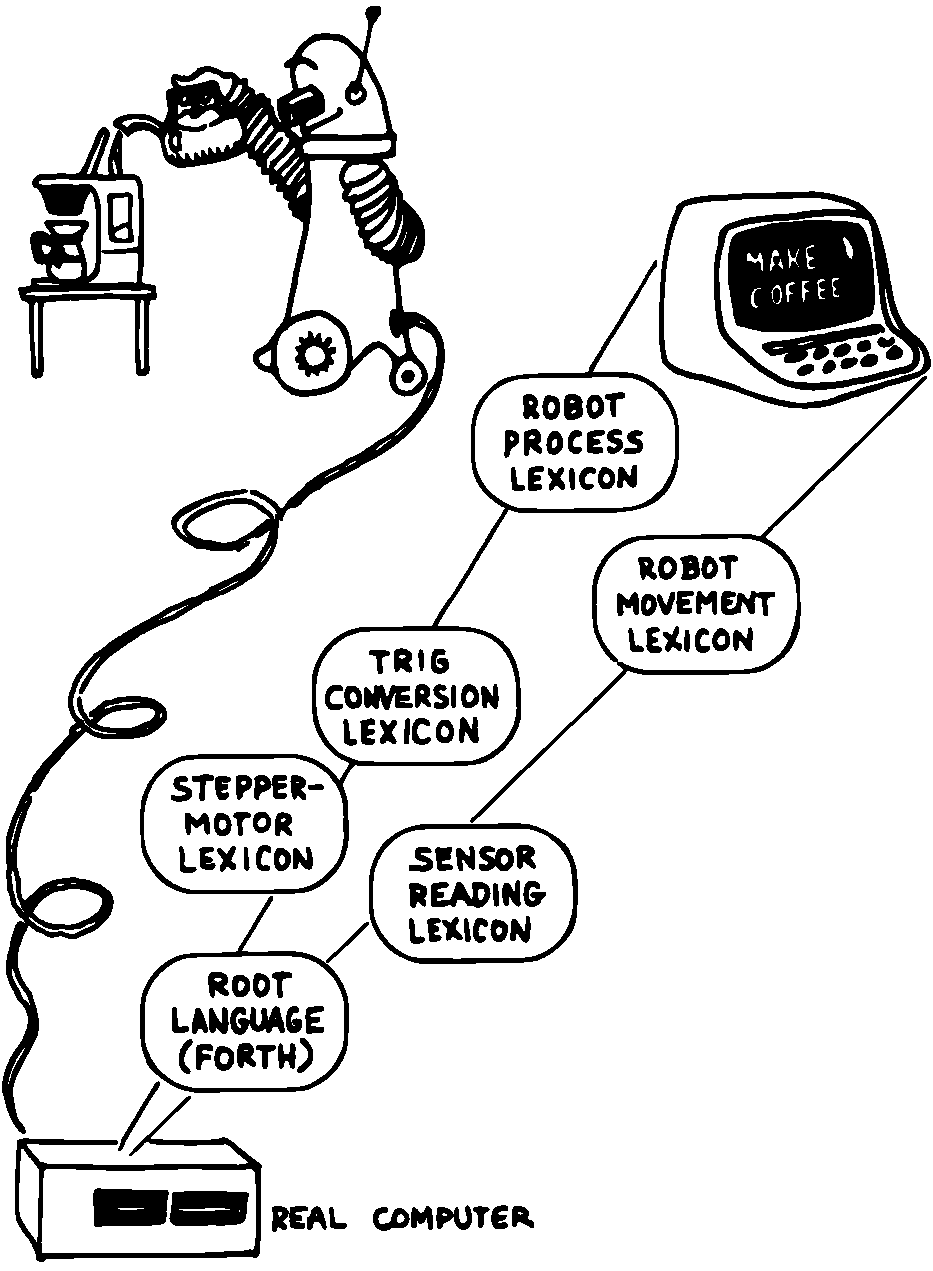
図 12 アプリケーションはコンポーネントで構成されている
Forthで書かれているアプリケーションはコンポーネント以外何も含んでいません。 ロボット工学アプリケーションは 図 12 のように分割されるかもしれません。
各用語集は、高レベルのアプリケーションコードを最も効率的で信頼性の高い方法でサポートすることのみを目的として書かれた、特殊目的のコンパイラであると言えるかもしれません。
ところで、Forth自体はコンポーネントをサポートしていません。 その必要はありません。 コンポーネントはプログラム設計者の分解の産物です(Forthには「スクリーン」があります。ソースコードを保存するための、大容量記憶装置の小さく区分けされた部分です。通常、1つまたは2つのForthスクリーンにコンポーネントを記述します)。(訳注:大容量記録装置=フロッピーディスクに1スクリーン当たり1024バイト(64桁16行)として容量の許す限り記録できる。)
用語集は、あらゆるレベルのコンポーネントで使用できることを理解することが重要です。 設計への階層的なアプローチではよくあることですが、連続する各コンポーネントは、そこにサポートコンポーネントを埋め込むことはしません。 代わりに、各用語集はその中にあるすべてのコマンドを自由に使用できます。 robot-movementコマンドは、他のコンポーネントと同様に、その言語、変数、定数、スタック演算子、数学演算子などとともに、大元の言語に依存しています。
このアプローチの重要な結果は、アプリケーション全体が単一の構文を使用することです。これにより、習得および保守が容易になります。 「言語」ではなく「用語集」という用語を使用するのはこのためです。言語には言語独自の構文があります。
コマンドがこのように利用可能であることは、テストとデバッグのプロセスを非常に簡単にします。 Forthは対話式なので、プログラマは次のような基本コマンドを入力してテストすることができます。
RIGHT SHOULDER 20 PIVOT
外部からと同じぐらい簡単に、更に強力なこれとか。
LIFT COFFEE-POT
同時に、アプリケーションが完成した時点で、プログラマは(そう望むのなら)、Forth自体を含むすべてのコマンドが意図的にエンドユーザーからアクセスされるのを封印するとができます。
これでForthの方法論が明らかになりました。 Forthプログラミングは、根源的な言語をアプリケーションに拡張し、直面する問題を説明するのに使用できる新しいコマンドを提供することで構成されています。
ロボット工学、在庫管理、統計などの特定のアプリケーション用に特別に設計されたプログラミング言語は「アプリケーション指向言語」として知られています。Forthはアプリケーション指向言語を「作成」するためのプログラミング環境です(このの最後の文はあなたが見つけることができるForthの最も簡潔な説明かもしれませ)。
実際、素のForthで直接、本気のアプリケーションを書くべきではありません。 素のForthは言語としては十分強力とは言えません。あなたがすべきことは、 あなたの問題への理解をForth(の用語集)として、あなた専用の言語を書くことです。 そうすれば問題の解決策をあなた専用の言語で優雅に記述することができます。
誰から隠す?¶
現在主流となっている言語では、「情報隠蔽」という言葉の意味が若干異なりますので、明確にしておく必要があります。 何から、または誰から情報を隠していますか?
(Modula2のような)伝統的な言語の最新版は、モジュールがその内部ルーチンやデータ構造を他のモジュールから確実に隠すことに後ろ向きです。目標はモジュールの独立性(最小連結)を達成することです。モジュールがエイリアン抗体のようにお互いを攻撃しようとしているのは恐怖です。そうでなければ、悪意のあるモジュールが尊いデータ構造のファミリーを破壊します。
これは私たちが心配していることではありません。 情報を非表示にする目的は、各コンポーネント内で変化する可能性があるものを局限することによって、設計変更による影響の可能性を最小限に抑えることです。
Forthプログラマは、一般に、データ構造を物理的に隠す手法を使用せず、プログラムを自分の管理下に置くことを好みます(にもかかわらず、Dewey Val ShorreによってModulaタイプのモジュールを追加する為の見事でシンプルなテクニックがわずか3行のコードで実装されています [shorre71] )。
データ構造構築の隠蔽¶
私たちが説明した方法論を可能にする、暗黙の呼び出しと暗黙のデータ渡しという、Forthの2つの発明について着目してきました。 3番目の特徴として、以前に定義済のコンポーネントに対して、コンポーネント内のデータ構造を記述することを可能にします。この機能は直接、メモリにアクセスします。
このように、 APPLES という変数を定義したとします。
VARIABLE APPLES
このように、この変数に数値を格納して、現在りんごが幾つあるか保持する事ができます。
20 APPLES !
以下のように変数の内容を表示することができます(APPLES ? [ Enter ] と入力)
APPLES ? 20 ok
以下のようにして1カウントアップできます。
1 APPLES +!
(入門者は、これらのフレーズの仕組みについては、 付録 A 参照)。
APPLES というワードには1つの機能しかありません。それはりんごの集計が保存されているメモリ位置のアドレスをスタックに積むことです。集計は「もの」としてとらえることができ、集計をセットする、集計を読む、集計を増やすワードは「行動(action)」と見なすことができます。
Forthは、データ構造のアドレスをスタックに渡すのを許可し、「読み込み(fetch)」と「格納(store)」コマンドを提供することで、 「もの」と「アクション」を都合よく分離しています。
変化する可能性があるものを中心に設計することの重要性について説明しました。 この変数 APPLES を使ってその後たくさんのコードを書いたとしましょう。 そして今、赤と緑の2種類のリンゴを追跡しなければならないことがわかりました。
私たちは固唾を飲む必要はありません。 APPLES の機能を思い出してください。それはアドレスを提供することです。2つの別々の集計が必要なら、 APPLES はりんごの種類に応じて2つの異なるアドレスを提供できます。ですから私たちは以下のように APPLES のより複雑なバージョンを定義します。
VARIABLE COLOR ( pointer to current tally)
VARIABLE REDS ( tally of red apples)
VARIABLE GREENS ( tally of green apples)
: RED ( set apple-type to RED) REDS COLOR ! ;
: GREEN ( set apple-type to GREEN) GREENS COLOR ! ;
: APPLES ( -- adr of current apple tally) COLOR @ ;
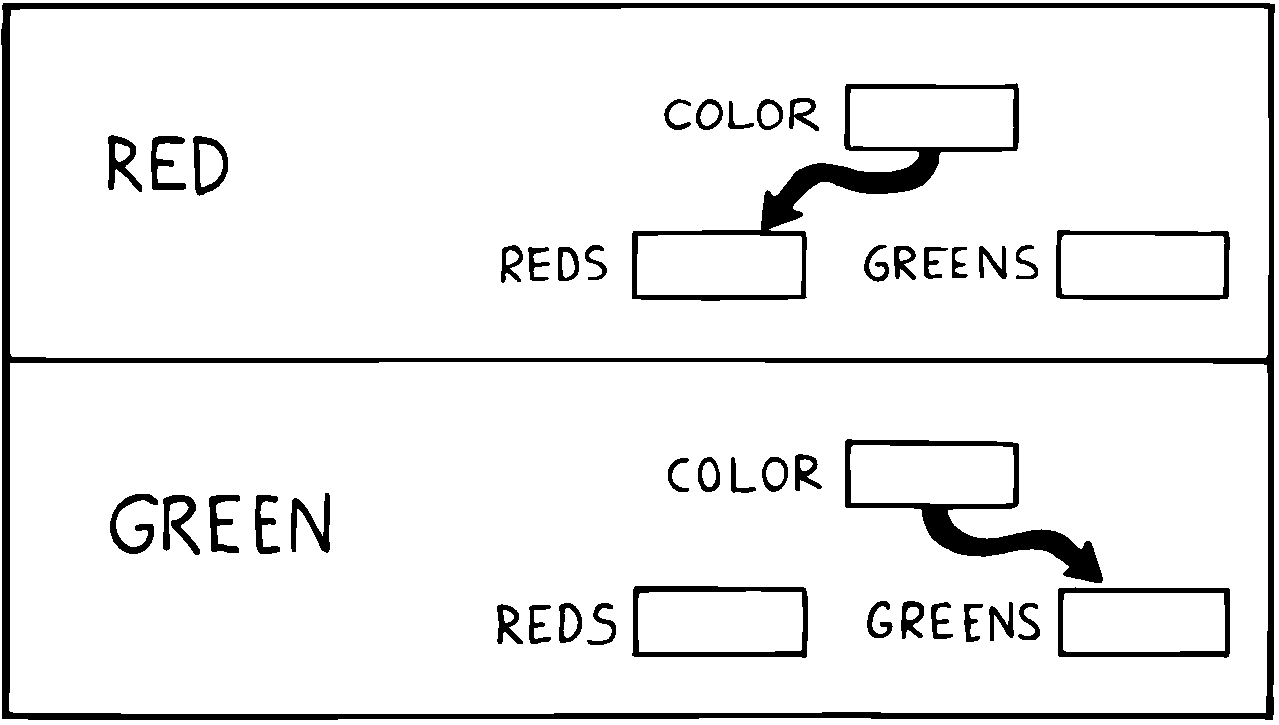
図 13 間接ポインタの変更
ここで、 APPLES は再定義されました。これで COLOR という変数の内容を取得します。 COLOR は、変数 REDS か、変数 GREENS を指すポインタです。REDS と GREENS は実際に集計を格納する変数です。
最初に RED と言えば、 APPLES を赤いりんごを参照するために使うことができます。もし GREEN と言えば、緑のりんごを参照するために使う事ができます( 図 13 )。
APPLES を使う既存のコードの構文を変更する必要はありませんでした。私たちは依然として、
20 APPLES !
や、
1 APPLES +!
と書く事ができます。
私たちがやったことをもう一度見返してください。私たちは、使い方に影響を与えること無く APPLES の定義を変数からコロン定義に変更しました。Forthでは、 APPLES の定義方法の詳細を、 それを使用するコードから隠すことができます。元のコードからは「もの」として見えているものは、実際にはコンポーネント内では「アクション」(コロン定義)として定義されています。
Forthは、データ構造を低レベルのコンポーネントの観点から定義できるようにすることで、抽象データ型の使用を推奨しています。手続きからCALLを排除し、アドレスとデータを暗黙的にスタック経由で渡し、 @ や ! を使ってメモリ位置に直接アクセスできるForthだけが、このレベルの情報隠蔽を提供できます。
Forthは何かがデータ構造なのかアルゴリズムなのかにはほとんど注意を払いません。 この無関心はアプリケーションを記述するのに必要な部品を作成する際に、信じられないほどの自由をプログラマに許します
私は、どのように定義されているかに関わらず、 APPLES のようなアドレスを返すワードを「名詞」と考える傾向があります。明白なアクションをとるワードは「動詞」です。
この例の RED や GREEN のようなワードは、 APPLES の機能を変更するため、「形容詞」としか呼ぶことができません。次のフレーズ、
RED APPLES ?
は、当然、以下とは違うのです。
GREEN APPLES ?
Forthのワードは副詞や前置詞としても使用できます。 Forthはとにかく気にしないので、特定のワードがどの品詞であるか判断するのはほとんど意味がありません。 アプリケーションを自然な言葉で説明することの容易さをただただ楽しんでください。
でもそれって高級言語なの?¶
短い技術概要では、伝統的な高級言語は、コマンドと機械操作の間の「1対1」の対応だけでなく、「直線形」な対応も排除することによってアセンブリ言語からへだたっていることに注目しました。明らかにForthは「1対1」の対応ではありません。しかし、「直線形」な対応に関しては、定義で使用するワードの順序はそれらのコマンドがコンパイルされる順序です。
Forthは高級言語水準に達してないのでしょうか? 答える前に、Forthアプローチの利点を探検してみましょう。

図 14 2つの視点
- Forthの発明者である チャールズ・ムーア は以下のように述べています:
あなたは各ワードを定義して、コンピュータがその意味を理解できるようにします。それが知っている方法は、それが呼び出されたら何らかのコードを実行するということです。コンピュータは全てのワードに対してアクションします。コンピュータはそのワードから去り、そのワードを保存することもせず、心にも留めません。
哲学的な意味で、これはコンピュータがワードを「理解する」ことを意味していると思います。コンピュータは、おそらくあなたよりももっと深く
DUPというワードを理解しています。なぜならDUPの意味について何の疑問も持っていないからです。あなたにとって意味のあるワードとコンピュータにとって意味のあるワードとの間のつながりは深遠なものです。 コンピュータは、人間と概念の間のコミュニケーションの手段となります。
ソースコードと機械実行の間の対応の1つの利点は、コンパイラとインタプリタが非常に単純化されていることです。 後の節で説明するように、この単純化によっていくつかの点で性能が向上します。
プログラミング方法論の観点からは、Forthアプローチの利点は「新しい」ワードと「新しい」構文を簡単に追加できることです。 Forthはワードを「見つける」とは言えません。ワードを探し出して実行します。 新しいワードを追加すると、Forthはそれらも探し出して実行します。 既存のワードと追加したワードに違いはありません。
さらに、この「拡張性」は、アクション型の機能だけでなく、あらゆる種類のワードに適用されます。 例えば、Forthでは、構造化された制御フローを提供する IF や THEN のような新しい「コンパイル」ワードを追加することができます。必要に応じてcase文や複数出口ループを簡単に追加できます。あるいは、必要でなければそれらを削除することもできます。
[それとは対照的に、文を理解するために語順に依存するすべての言語は、すべての有効な単語およびすべての有効な組み合わせを「知っている」必要があります。 あなたが望むすべての構成が含まれている可能性はほとんどありません。 製造元によって決め打ちされた言語が存在するだけです。あなたはその言語の知識を拡張することはできません。
実験室の研究者は、研究環境におけるForthの最も重要な利点の1つとして、 柔軟性と拡張性を挙げています。 コンピュータに接続されている さまざまなテスト機器に関する情報を隠すために、用語集を開発することができます。 この作業がより経験豊富なプログラマによって行われると、 研究者は実験用の簡単なプログラムを書くために少数のワードによる 「ソフトウェアツールボックス」を自由に使用することができます。 新しい機器が登場すると、新しい用語集が追加されます。
Mark Bernsteinは、研究室で既製の特殊目的手続きライブラリを使用することの問題を説明しています( [bern83] )。曰く、「ユーザーではなく、コンピュータが実験を支配します」。しかしForthでは、彼曰く、「コンピュータは実際、研究者自身が、ソフトウェアを変更、修復、改良し、彼らの機器で実験し特性を測るのを励ましてくれます。再び研究者が主導権を握ります」。
図 15 セキュリティ問題の2つの解決策
Forthが高級言語と呼ばれるのに適していないと信じる純粋主義者にとって、Forthは問題をさらに悪化させます。強力な構文チェックとデータ型指定が現代のプログラミング言語の主要な推進力の1つになりつつありますが、Forthはほとんど構文チェックをしません。 説明した自由度と柔軟性の種類を説明するために、 APPLES RED の代わりに RED APPLES とタイプするつもりだったと言うことはできません。たった今、あなたは構文を発明したばかりなのですから。
それでも、Forthでは各定義を一度に一つづつ、秒単位のターンアラウンドでコンパイルさせることで、その抜け漏れを補う以上の効果があります。定義がうまくいかないときにはすぐに間違いを発見するでしょう。さらに必要に応じて、定義に適切な構文チェックを追加できます。
画家の絵筆は、画家に間違いを通知したりはしません。画家がそれを判断します。シェフのフライパンや作曲家のピアノはシンプルで柔軟なままです。なぜあなたはプログラミング言語に考えさせようとするのでしょうか?
では、Forthは高級言語なのでしょうか? 構文チェックの問題ではそれは際立っています。抽象化とパワーの問題ではそれは「無限大」レベルのように思えます。出力ポートでのビット操作からビジネスアプリケーションまで全てをサポートします。
あなたが決めるのです(Forthは気にしません)。
設計言語¶
Forthは設計言語です。伝統的なコンピュータ科学の学生にとって、この言葉は矛盾しています。「言語で設計するのではなく、言語で実装するのです。設計は実装よりも優先されます」。
ベテランのForthプログラマはこれに同意しません。 Forthでは抽象的な設計レベルのコードを書くことができ、 用語集への分解を徹底することで、それをいつでもテストする事が可能です。 開発が進むにつれて、 抽象的な設計レベルのコードを使用するコンポーネントの下にあるコンポーネントは 簡単に書き換えることができます。 最初はコンポーネント内のワードがステッピングモーターを制御する代わりに あなたの端末に数字を出力するかもしれません。 自身の実行を通知するために自身の名前を出力するかもしれません。 それらは何もしないかもしれません。
この哲学を利用して、あなたのアプリケーションの、シンプルだがテスト可能なバージョンを書き、目標に到達するまで連続的に変更し洗練させることができます。
コードでの設計を可能にするもう1つの要因は、Forthが、いくつかの新しい言語のように、「バッチ-コンパイル」開発シーケンス(編集-コンパイル-テスト-編集-コンパイル-テスト...)を排除することです。 フィードバックは瞬時に行われるため、この媒体はクリエイティブプロセスのパートナーになります。 バッチコンパイラ言語を使用しているプログラマは、クリエイティブな流れが妨げなく流れるときにアーティストが到達する生産的な気分になることはめったにありません。
これらの理由から、Forthのプログラマは、計画することが正しいと感じる古臭い人たちよりも計画に費やす時間が少なくてすみます。彼らにとって、計画していないのは無謀で無責任な事です。 伝統的なプログラミング言語は変化に容易に対応できないため、伝統的な環境はプログラマに計画することを強いるのです。
残念なことに、人間の先見の明は最良の条件下でも限定されたものです。計画が多すぎると逆効果になります。
もちろんForthは計画を排除している訳ではありません。試作を許しています。試作することは、電子工作でのブレッドボード(訳注:ハンダ付け不要で回路を試作できる板)と同様に、計画するためのより洗練された方法です。
次章にあるように、実験は計画の当て推量よりも、真実にたどり着くために、より信頼できることを証明します。
性能の言語¶
性能はこの本の主な話題ではりませんが、Forthの初心者は、Forthの利点が純粋に哲学的なものだけではないことに安心して下さい。全体的に、Forthは他の全ての高級言語を、スピード・機能・コンパクトさで上回っています。
スピード¶
Forthはインタプリタ言語ですが、コンパイルされたコードを実行します。したがって、インタプリタBASICよりも10倍高速に実行されます。
Forthは、 「スレッド化コード」として知られている手法によって、ワードの実行に最適化されています( [bell72] 、 [dewar] 、 [kogge82] )。非常に小さなコードにモジュール化することによるペナルティは比較的わずかです。
内部インタプリタ(各コロン定義を構成するアドレスのリストを解釈する)は、 プロセッサによっては、 プリミティブワードの実行時間の最大50%を消費する可能性があるため、 アセンブラコードほど速くは実行されません。
しかし、大規模なアプリケーションでは、Forthはアセンブラの速度に非常に近くなります。 これには3つの理由があります。
最初にして傑出していることは、Forthはシンプルです。Forthがデータスタックを使用することで、あるワードの引数を別のワードへ渡すことによるパフォーマンスコストが大幅に削減されます。 ほとんどの言語では、サブルーチンを利用するときにモジュール間で引数を渡すことがパフォーマンスが低下する主な理由の1つになっています。
第二に、 Forthはあなたが高級言語でも機械語でもワードを定義することを可能にします。 どちらの方法でも、特別な呼び出しシーケンスは必要ありません。 新しい定義を高レベルで記述し、それが正しいことを確認したら、 それを使用するコードを変更することなくアセンブラーでそれを書き直す ことができます。 典型的なアプリケーションでは、 おそらくコードの20%が実行時間の80%を占めるでしょう。 マシンコード化する必要があるのは、 最も頻繁に使用されるタイムクリティカルなルーチンだけです。 Forthシステム自体は大部分がマシンコード定義で実装されているので、 アセンブラでコーディングする必要がある アプリケーションワードはほとんどありません。

図 16 ベストなおしゃべりのトップダウン設計と若者
第三に、Forthアプリケーションは完全にアセンブラで書かれたものよりも よい設計になる傾向があります。 Forthプログラマは、言語の試作機能を 利用して、いくつかのアルゴリズムを試してから、自分のニーズに最も 適したものを選びます。 Forthは変更を奨励するため、 最適化の言語とも呼ばれます。
Forthは高速アプリケーションを保証しません。 それはプログラマに速いアプリケーションを設計するための創造的な環境を与えます。
可能性¶
Forthは他の言語でできることなら何でもできます。通常はもっと簡単にできます。
ローエンドでは、ほとんどすべてのForthシステムにアセンブラが含まれています。 これらは、構造化プログラミング技法を使用して条件文とループを書くための制御構造演算子をサポートします。 通常は割り込みを書くことができます。必要に応じて割り込みコードを高レベルで書くこともできます。
いくつかのForthシステムはマルチタスクで、あなたが望むだけ多くのフォアグラウンドまたはバックグラウンドタスクを追加することを可能にします。
Forthは、RT-11、CP/M、またはMS-DOSなどの任意のオペレーティングシステム上で実行するように書くことができます。または、Forthは自身の端末ドライバやディスクドライバを含む自給自足オペレーティングシステムとして書くことができます。
Forthクロスコンパイラまたはターゲットコンパイラでは、Forthを使用して、同じコンピュータ用または異なるコンピュータ用に新しいForthシステムを再作成できます。 ForthはForthで書かれているので、あなたはアプリケーションの必要性に従ってオペレーティングシステムを書き直すという、他では考えられないチャンスがあります。あるいは、最適化したバージョンのアプリケーションを組み込みシステムに転送することもできます。
サイズ¶
ここで考慮すべき点が2つあります。根元のForthシステムのサイズとコンパイル済みForthアプリケーションのサイズです。
Forthの核は非常に柔軟です。 組み込みアプリケーションでは、アプリケーションを実行するために必要なForthの部分は、わずか1Kに収まります。 完全な開発環境では、インタプリタ、コンパイラ、アセンブラ、エディタ、オペレーティングシステム、およびその他すべてのサポートユーティリティを含むマルチタスクForthシステムは平均16Kです。 ですからアプリケーションのための十分な余地が残っています(そして、新しいプロセッサ用Forthの中には、32ビットアドレッシングを処理するので、想像を絶するほど大きなプログラムを可能にするものもあります)。
同様に、Forthでコンパイルされたアプリケーションは非常に小さい傾向があります。通常、同等のアセンブリ言語プログラムよりも小さいです。 その理由もまた、スレッド化コードです。 定義済のワードへの各参照は、どんなに強力であっても、2バイトしか使用しません。
Forthにとって最もエキサイティングな新しい領域の1つは、ロックウェル R65F11 ForthベースのマイクロプロセッサなどのForthチップの製造です。 [dumse] このチップには、ハードウェア機能だけでなく、Forth言語のランタイム部分および専用アプリケーション用のオペレーティングシステムも含まれています。 ForthのアーキテクチャとコンパクトさだけがForthベースのマイクロ化を可能にします。
要約¶
Forthは構造や哲学の点で他の一般的な言語とは全く違って、しばしば奇妙なものとして特徴付けられてきました。 そうではなく、Forthは現在最も現代的な言語が自慢している多くの原則を組み込んでいます。 構造化設計・モジュール性・情報隠蔽は、今時の流行語です。
新しい言語の中には、Forthの精神にさらに近づくものがあります。 たとえば、C言語では、Forthと同様に、プログラマがCまたはアセンブリ言語のいずれかで新しい機能を定義できます。 そしてForthと同様に、Cの大部分は機能に関して定義されています。
しかし、Forthはモジュール性と情報隠蔽の概念を他の現代言語よりもさらに拡張しています。 Forthはワードが呼び出される方法やローカル引数が渡される方法を隠しさえします。
結果のコードはワードの集中的な相互作用、抽象的な思考の最も純粋な表現になります。 その結果、Forthプログラマはより生産的になり、より短く、より効率的に、そしてより保守しやすいコードを書くようになります。
Forthは究極の言語ではないかもしれません。 しかし、そのようなものがもしあれば、私は究極の言語は他の現代の言語よりもForthによく似ていると思います。
参考文献¶
| [dahl72] | 邦訳;構造化プログラミング;サイエンスライブラリ情報電算機 32;E.W.ダイクストラ, C.A.R.ホーア, O.-J.ダール共著;野下浩平, 川合慧, 武市正人共訳;サイエンス社;1975.5;ISBN-13:9784781902760;ISBN-10:4781902766(O. J. Dahl, E. W. Dijkstra, and C. A. R. Hoare, Structured Programming, London, Academic Press, 1972.) |
| [wirth71] | Niklaus Wirth, "Program Development by StepwiseRefinement," Communications of ACM, 14, No. 4 (1971), 221-27. |
| [stevens74-1] | W\. P. Stevens, G. J. Myers, and L. L. Constantine,"Structured Design," IBM Systems Journal, Vol. 13, No. 2, 1974. |
| [parnas72] | David L. Parnas, "On the Criteria To Be Used inDecomposing Systems into Modules," Communications of the ACM, December 1972. |
| [liskov75] | Barbara H. Liskov and Stephen N. Zilles,"Specification Techniques for Data Abstractions," IEEE Transactions on Software Engineering, March 1975. |
| [parnas79] | David L. Parnas, "Designing Software for Ease ofExtension and Contraction," IEEE Transactions on SoftwareEngineering, March 1979. |
| [shorre71] | Dewey Val Shorre, "Adding Modules to Forth,"1980 FORML Proceedings, p. 71. |
| [bern83] | Mark Bernstein, "Programming in the Laboratory," unpublished paper, 1983. |
| [bell72] | James R. Bell, "Threaded Code," Communicationsof ACM, Vol. 16, No. 6, 370-72. |
| [dewar] | Robert B. K. DeWar, "Indirect Threaded Code," Communications of ACM, Vol. 18, No. 6, 331. |
| [kogge82] | Peter M. Kogge, "An Architectural Trail toThreaded-Code Systems," Computer, March, 1982. |
| [dumse] | Randy Dumse, "The R65F11 Forth Chip," ForthDimensions, Vol. 5, No. 2, p. 25. |