第4章 詳細設計と問題解決¶
些細なこと これをどうすればいいかはわかる。どのくらいの期間かかるか全くわからない。重大なこと どうすりゃいいのか手がかりが無い。― 研究所で開発された運営哲学ヴァージニア工科大学化学部自動化・計測設計グループ
アプリケーションのコンポーネントを決定したら、次のステップはそれらのコンポーネントを設計することです。 この章では、問題解決の手法をForthアプリケーションの詳細設計に適用します。 これは純粋な発明のためのひとときです。私たちの多くが最も楽しいと思う部分です。 明白でない問題のもつれに立ち向かい、勝利した人には特別な満足感があります。
文章では、アイデアを表現するために使用される単語からアイデアを分離することは困難です。 Forthアプリケーションを書く際には、詳細な設計段階を実装から切り離すことは困難です。なぜなら、私たちはForthで設計する傾向があるからです。 このため、この章では、問題を提示するだけでなく、それに対する解決策を設計することによって、コード化された実装に至るまで、少しずつ歩んでいきます。
問題解決技法¶
問題解決技法に意識的な思考を注がなくても、初心者でも、プログラミングの問題を解決はできます。 では、問題解決技法を学習するメリットとは何でしょうか?それは問題解決の速度を上げられることです。 問題自体とは別に、問題を解決するための「方法」を考えることによって、私たちは自分の技法の引き出しを増やします。
ジョージ・ポリアは、問題解決、特に数学的問題に関する本をいくつか書いています。 これらのうち最も入手しやすいのは「How to Solve It」 [polya] です(邦題:いかにして問題をとくか 丸善出版 1975年4月)。 数学的な問題を解くことは、ソフトウェアの問題を解くこととまったく同じではありませんが、そこにはいくつかの有益な提案があります。
次の一連のヒントは、問題解決の科学で推奨されているいくつかの手法をまとめたものです。
ヒント
目標を決める。
あなたが達成しようとしていることを知ろうとする。あなたが 第2章 で見たように、このステップはさらに詳細になります。
データインターフェースを決定します。目標を達成するためにどのデータが必要かを知り、それらのデータが利用可能であることを確認します(入力)。 その機能がどのデータを生成(出力)することを期待されているかを知る。 単一の定義では、これはスタック効果のコメントを書くことを意味します。
規則を決めます。 あなたが知っているすべての事実を確認してください。 第2章 では、電話料金計算と料金を適用するための規則を説明しました。
ヒント
全体として問題を描きます。
「分析」フェイズでは、各部分の理解を明確にするために、問題を部分に分けました。 私たちは今や「合成」フェイズに入っています。 問題全体を視覚化する必要があります。
できるだけ多くの問題についての情報を頭に入れておくようにしてください。 一目で最大限の情報を確認するのに役立つように、単語、フレーズ、図、表、またはデータや規則の任意の種類のグラフィック表現を使用してください。 あなたが息を大きく吸い込んで止めた時のように、解決する必要がある問題の要件を頭の中に詰め込んで、そして一気にはき出すようにアイデアの奔流を生み出して下さい。
この、思考的に「大きく吸って息を止める」方法を会得してください。
そうすると、次の2つのうちのいずれかが起こります。
あなたは洞察力のひらめきで解決策を見るかもしれません。 すばらしい! 安心のため息を吐き出し、すぐに実施に進む。 または…、問題は解決するには複雑すぎる、またはなじみのないものです。 この場合は、類推と部分的な解決策に注意を向ける必要があります。 あなたがそうするとき、あなたがすでに問題の必要条件に一度に集中していて、あなたの精神的な網膜の上にこれらの必要条件を刻むことは重要です。
ヒント
計画を開発する
解決策が一目でわからない場合は、次のステップはあなたがそれを解決するために取るアプローチを決定することです。 行動のためのコースを設定し、無意識のうちにぶつかることの罠を避けてください。
以下のヒントは、検討に値するいいくつかのアプローチを提案します。
ヒント
同様の問題を考えてください。
この問題は既におなじみのものでしょうか。 あなたは以前に同様の定義を書きましたか? 問題のどの部分がよく知られているのか、またこの問題がどのように異なるのかを理解します。 以前にそれをどのように解決しようと試みたか、またはどのようにしてそれを解決したかを覚えておくようにしてください。
ヒント
処理の流れに沿って前進して下さい。
問題を攻撃するための通常の明白な方法は、既知のものから始めて未知のものに進むことです。 どの馬に賭けるかを決める際には、最近の歴史や現在の健康状態などから始めて、これらのさまざまな要因に重みを付けてお気に入りに到達します。
ヒント
処理の結果から逆方向にさかのぼって下さい。
より複雑な問題は、入ってくるデータを処理するための多くの可能な方法を提示します。 どのルートで進めば解決策に近づくことがでるでしょうか?いいえ進みません。この種の問題は結果から後ろ向きにさかのぼることで最もよく解決されます( 図 40 )。
図 40 処理に沿って進むより結果かさかのぼる方ががより簡単な問題。
ヒント
信じ込んで下さい。
信じ込む事は、結果からさかのぼるために必要な要素です。 私たちは有名な数学的問題で説明します。 2つのバケツがあるとします。 バケツには目盛りはありませんが、一方は9リットル入りで、もう一方には4リットル入りです。 私たちの仕事は、小川から正確に6リットルの水を汲み上げることです( 図 41 )。

図 41 2つのバケツ
さらに読み進む前に、これを自分で解決してみてください。
どのようにして、「9」と「4」から「6」を得ることができますか? 私たちは、バケツから別のバケツへと水を移すことを想像することによって、処理を進め始めることができます。 たとえば、小さなバケツ(4リットル)で大きなバケツ(9リットル)に2回注ぐと、8リットルが得られます。 大きなバケツ(9リットル)をいっぱいにしてから、小さなバケツ(4リトル)を満たすと、大きなバケツ(9リットル)には正確に5リットルが余ります。
これらのアイディアは興味深いですが、私たちはまだ6リットルを手に入れてません。そしてどのように6リットルにするのか明らかではありません。
結果からさかのぼってみましょう。 私たちは6リットルの水を測定したと仮定します、そしてそれは大きなバケツ(9)の中に入っています(それは小さなバケツ(9)には収まりません!) さて、どうやってそこに至りましたか? 一歩前の私たちのバケツの状態はどうでしたか?
2つの可能性があります( 図 42 )。
- 小さなバケツ(4)満杯の水を大きなバケツ(9)に入れたとすると、その前に大きなバケツ(9)にはすでに2リットル入っていた事になります。あるいは、
- 大きなバケツ(9)を満杯にして、そこから、1リットルだけすでに入っていた小さなバケツ(4)に注ごうとしているところです。
どちらを選びますか?推測しましょう。VERSON Aは2リットルの測定を必要とし、VEERSON Bは3リットルの測定を必要とします。 最初の試行では、この2つの結果はありませんでした。 しかし、1リットル差のパターンがありました。4引く1は3です。 ということで、VERSION Bから始めるとしましょう。
ここで本物の策を弄します。私たちは、説明した状況にたどり着いたことを疑う余地なく、自分自身に信じ込ませなければなりません。 私達はちょうど3リットルを小さなバケツ(4)に注いだところです。すべての不信を中断して、私たちはそれをどうやったかに集中します。
小さなバケツ4)に3リットルを注ぐにはどうすればよいでしょうか。 小さいバケツにすでに1リットルがあったならば! 突然私たちはハードルを乗り越えました。 簡単な質問は、小さなバケツに1リットルをどうやって入れるかということです。大きなバケツ(9)満杯から、小さなバケツ(4)に2回注ぐと、大きなバケツ(9)には1リットルが残りました。それからその1リットルを小さなバケツ(4)に移しました。
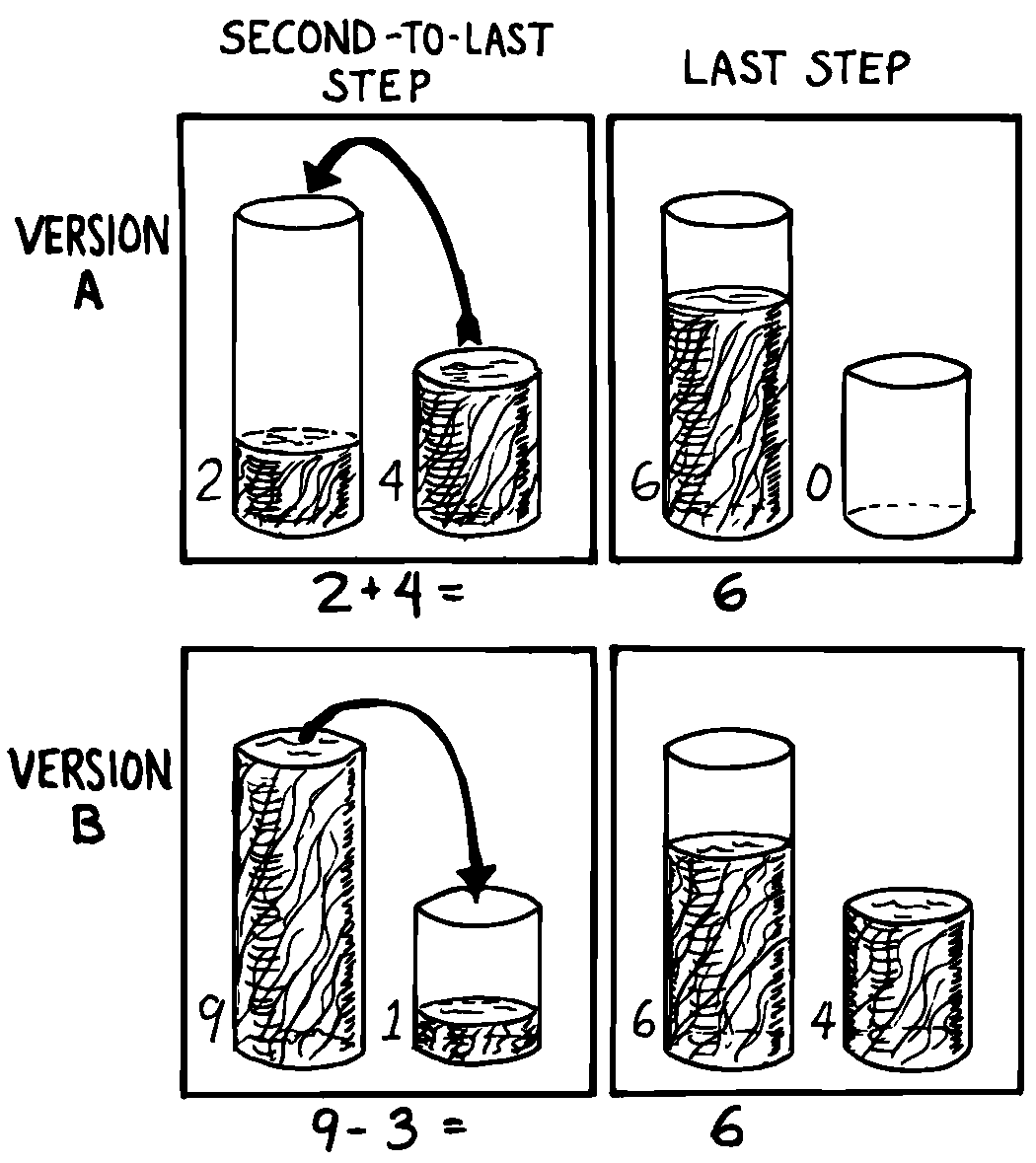
図 42 最終結果を達成する。

図 43 複雑な問題の目的
私たちの最後のステップは、問題を再び処理に沿って進めてみてロジックをチェックすることです。
逆方向に作業することのもう1つの利点は、問題が解決できない場合は、逆方向に作業すると解決策がないことをすぐに証明できます。
ヒント
補助的な問題を認識してください。
問題を解決する前は、どのステップが必要なのか、あるいはいくつのステップが必要なのかという漠然とした概念しかありません。 私たちが問題に慣れてくるにつれて、私たちの問題には、提案している手順の本流とは幾分異なるよう思える複数の副問題が含まれることを認識し始めます。
私たちが今さっき解決した問題では、小さなバケツに1リットル入れ、次に大きなバケツに6リットル入れるという2つの副問題がありました。
「補助問題」と呼ばれることもあるこれらの小さな問題を認識することは、重要な問題解決手法です。副問題を特定することで、それには簡単な解決策があると仮定することができます。 その解決策が何であるかを判断することを放棄せずに、私たちは主な問題とともに先に進みます。
(Forthはこの技法に最適です。これについては後で説明します。)
ヒント
問題から一歩遠ざかってみる
ある特定の解決策に簡単に感情的になってしまうので、私たちは偏見を持たずにいることを忘れてしまいます。
問題解決の文献はしばしば9つの点の例を採用しています。 それは私を困惑させたので、ここに示します。 図 44 のように9つの点が配置されています。 目的は、ペンを紙から持ち上げることなく、9つすべての点に接触または通過する直線を描画することです。 制約は、9つすべての点に4本の線だけで触れる必要があることです。

図 44 9つの点問題
しばらくの間がんばっても、ほぼ正しい 図 45 よりも良くはありません。 あなたが本当に一生懸命集中するならば、あなたは結局問題は引っ掛けであると結論づけるかもしれません。じつは、解決策はありません。
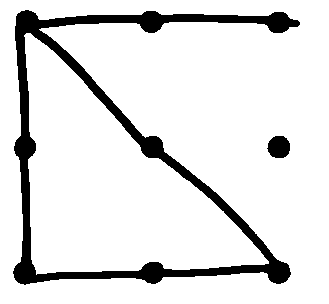
図 45 正解は無い
しかし、あなたは振り返って自分自身にこう尋ねる
「私は、狭義に捉えることによって自分自身をだましていますか?問題で指定されていない制約を想定していますか?それらはどのような制約になる可能性がありますか?」
それなら、9つの点の周囲を超えていくつかの線を延長することを考えるかもしれません。
ヒント
右脳左脳全部使って考えましょう。
問題があなたを困らせ、行き詰まっているように思われるときは、リラックスして、心配するのをやめてください。
創造的な人々は、常に彼らの最高のアイデアはベッドの中やシャワーの中で、はるか彼方から出てくるように見えることに気づいていました。 問題解決に関する多くの本は、本当に困難な問題を潜在意識に頼ることを提案しています。
現代の脳機能理論は、合理的で意識的な思考(シンボルの操作に依存する)と潜在意識的な思考(知覚を以前に保存された情報と相関させ、新しい有用な方法で知識を再結合し再リンクする)の違いを探ります。
Leslie Hart [hart75] は、ロジックによって大きな問題を解くことの難しさを説明しています。
しばらくの間注意領域に持ち込まれることができる脳のその1つの小さな機能に大きな負荷がかかります。 サーカスのように偉業は可能ですが、私たちの栄光ある新皮質の全資源を利用すること...脳の数十億個のニューロンの能力を利用することがより賢明です。
…仕事には、観察、読み取り、データの収集、他の人が達成したことの確認など、脳に生の入力を提供する側面があります。 一度入ったら、「潜在意識」手順が、同時に、自動的に、注意領域の外側を引き継ぎます。
…それは明らかに思えますが…大型コンピュータと同じように、必ずしも継続的ではありませんが、検索はその間に行われています。 私は、検索が分岐し、開始し、停止し、行き止まりになり、そして新たに始まり、最終的には評価された後に意識的な注意を払うように解答を集めるという推測に疑問を感じます。
ヒント
解決策を評価してください。 他の解決策を探してください。
猫の皮を剥ぐ方法を1つ見つけたのかもしれません。 他の方法があるかもしれません、そしてそれらのうちのいくつかはより良いかもしれません。
最初の解決策にばかり傾注せず、セカンドオピニオンを求めて下さい。

図 46 「私はただ眠っているだけじゃありません。大脳新皮質を使ってるんです。」
ソフトウェア新規開発者へのインタビュー¶
- Scientek Instrumentation, Incのオーナー兼社長である Donald A. Burgess は言います。
私は自分自身を柔軟に保つために、何かを設計する上で長年にわたって私が有用だと思ったいくつかのテクニックを持っています。 私の最初の規則は、「不可能なことは何もない」です。 私の2番目の規則は、「忘れないでください、目的は出力することです」です。
まず問題を調べ、2つか3つのアプローチを紙に書きます。 それからそれがはたらくかどうか見るために、最も魅力的なものを試してください。 通して実行してみます。それから、故意に始めまで戻って、最初からやり直します。
最初からやり直すことには2つの価値があります。 まず、それはあなたに新鮮なアプローチを与えます。 あなたはあなたが始めたやり方に引き返すか、あなたが始めたやり方より新しいやり方に引き寄せられます。
第二に、新しいアプローチはあらゆる種類の強力な可能性を示すかもしれません。 今や、あなたは(既に一度試行したことで)基準となるものを持っています。 両方のアプローチを見て、両方の利点を比較することができます。 あなたは判断するのにより良い立場にあります。
身動きできなくなるのは、単一のアプローチに従うのが難しすぎるからです。 「私はこの金柑しぼり器を違うものにしたいのです。伝統的なデザインを面白くないと拒絶しましょう。クレイジーなアイデアを試してみましょう。」
一番いいのは絵を描き始めることです。 私は小さな男を描きます。それが「データ」のように見えないようにして私の思考プロセスをいじくります。類推は思考を活性化させます。状況の中に物事を置くことは、Forthをはじめ、あなたがあらゆる言語の中に閉じ込められるのを防ぎます。
私は集中したいときは小さな紙切れに描きます。私が全体的な流れをとらえるために広い範囲で考えたいときは大きな一枚の紙に描きます。 これらは私が停滞しないようにするために使用するクレイジーなトリックのいくつかです。
私がForthでプログラムをするとき、私はただ夢を見ながら、アイデアをの周りを蹴って一日過ごします。 通常、打ち込みを始める前に、一般的な用語でそれをスケッチします。 手書きのコードはありません、語りだけです。自分へのメモだけです。
それから私は最初のコードの最終行から始めます。 できる限り文章に近いように、自分がやりたいことを説明します。 それから私はエディタを使ってこの定義を画面の下にスライドさせ、そして内部のワードのコーディングを始めます。 それから私はそれがそれをするためのお粗末な方法であることに気づきます。 一番上のワードを2つに分割し、そのうちの1つを以前のブロック(スクリーン)に転送して、それをもっと早く使用できるようにするかもしれません。 ハードウェアがある場合は実行してみます。 それ以外の場合はシミュレートします。
Forthは自己訓練が必要です。 あなたはひたすらキーボードをいじくるのをやめる必要があります。 Forthは私が言うことをやろうとします。私が行こうとしている場所とは無関係のあらゆるばかげたことやろうとします。 その時は私はキーボードから離れなければなりません。
Forthはあなたに遊ばせます。 それで結構です。あなたはそれでいくつかのアイデアを得ることができるでしょう。あなたがForthで遊ぶ習慣はあっても、あなたが自分自身を保つ限り、あなたの頭はコンピュータよりもはるかに優れています。
詳細設計¶
私たちは今、開発サイクルの中で、コンポーネント(または特定のワード)が必要だと決心したところです。 コンポーネントはいくつかのワードで構成され、その一部(用語集を構成するもの)は他のコンポーネントによって使用され、一部(内部のワード)はこのコンポーネント内でのみ使用されます。
次のヒントに従うために必要な数のワードを作成します。
ヒント
各定義は、単純で明確に定義されたタスクを実行する必要があります。
コンポーネントの設計に一般的に含まれる手順は次のとおりです。
- 要求される機能に基づいて、外部定義の名前と構文を決定します(インターフェースを定義します)。
- アルゴリズムとデータ構造を記述して、概念モデルを改良します。
- 補助定義を認識します。
- どのような補助的な定義と技法が、すでに利用可能かを判断します。
- 擬似コードを使用してアルゴリズムを説明します。
- 既存の定義から入力に逆方向に作業することによってそれを実装します。
- 不足している補助定義を実装します。
- 強力な要素を持つ共通の名前が多く含まれている場合は、共通性を内部定義として設計およびコーディングしてから、外部定義を実装します。
私たちは最初の2つのステップについて深く掘り下げます。それから拡張の例として用語集を設計します。
Forth構文¶
開発サイクルのこの時点で、新しい用語集のワードをどのように使用するのかを決定する必要があります。 その際、後続のコンポーネントがその用語集をどのように使用するかを覚えておいてください。
ヒント
コンポーネントを設計する際の目標は、それ以降のコードを読みやすく、保守しやすくする用語集を作成することです。
各コンポーネントはそれを使用するコンポーネントを念頭に置いて設計する必要があります。 ワードが文脈の中で現れるときに意味がわかるように、あなたは用語集の構文を設計しなければなりません。 これまで見てきたように、相互に関連する情報をコンポーネント内に隠すことで、保守性を確保します。
同時に、Forth自身の構文を観察してください。 あなたが親しんでいるという理由で特定の構文を主張するのではなく、Forthが特別な努力をしなくてもサポートできる構文を選択することで、不要なコードをたくさん書く必要がなくなります。
Forthの自然な構文の基本的な規則は次のとおりです。
ヒント
数を名前の前に置く。
数値引数を必要とするワードは、当然その数値をスタック上で見つけることを期待します。 構文としては、数値は名前の前に置きます。 たとえば、 n個の空白を出力する SPACES というワードの構文は、
20 SPACES
です。時々、この規則は(英語圏の)私たちが聞き慣れている順番に違反します。 たとえば、Forthのワード + の前には、以下の通り両方の引数が置かれることを想定しています。
3 4 +
値が演算子に先行するこの順序付けは「後置」と呼ばれます。
Forthは心が広いので、後置記法(訳注:しばしば逆ポーランド記法とも言われる)を無理強いする事はありません。以下のように、入力ストリーム内で数の1つを期待するように + を再定義することもできます。
3 + 4
この定義は以下です。
: + BL WORD NUMBER DROP + ;
(ここで、WORD は79および83標準のワードで、アドレスを返し、そして83標準では非推奨のワード(Forth-83 Appendix B. Uncontorlled Reference Words 参照)である NUMBER は倍長整数を返します)
これはいい。しかし、この定義を他のコロン定義の中で使用したり引数を渡したりすることはできず、それによってForthの大きな利点の1つが無効になります。
多くの場合、「名詞(noun)」タイプのワードは、そのアドレス(または任意のタイプのポインタ)を「動詞(verb)」タイプのワードのスタック引数として渡します。以下がForth流の構文です。
noun verb
これらはスタックを使って普通に実装するのが最も簡単です。

(英語では)場合によっては、この語順は不自然に聞こえます。 たとえば、 INVENTORY というファイルがあるとします。 そのファイルを使ってできることの1つは、 SHOW です。 つまり、情報をきれいな列にフォーマットします。 INVENTORY がそれに作用する SHOW へのポインタを渡すと、構文は以下のようになります。
INVENTORY SHOW
あなたの仕様が英語の語順を要求するならば、Forthはそれを達成する方法を提供します。 しかしほとんどの場合、新しいレベルの複雑さが伴います。 時々、よりよい名前を選ぶ事に最善を尽くしてください。例えばこんなのはどうですか?
INVENTORY REPORT
(ここでは、 INVENTORY を形容詞として扱い、REPORT 名詞として扱いました。)
要件で構文の指定があった場合は以下のようにします。
SHOW INVENTORY
いくつかの選択肢があります。 SHOW はフラグを立て、 INVENTORY はそのフラグに従って動作します。 このようなアプローチには、特に INVENTORY がそれに対して実行される可能性のあるすべてのアクションを認識するのに十分「スマート」でなければならないという欠点があります(これらの問題は、 第7章 と 第8章 で扱っています)。
あるいは、 SHOW は入力ストリームの次のワードを先読みするかもしれません。 この章で後述する「期待を避ける」というヒントで、このアプローチについて説明します。
あるいは、推奨されるアプローチとして、 SHOW は INVENTORY が実行する「ワードへのポインタ」を設定するかもしれません(ベクトル実行については 第7章 で議論します)。
ヒント
テキストは名前の後ろに続けます。
Forthインタプリタが数字でも定義済みのワードでもないテキスト文字列を見つけると、エラーメッセージを出力して中断します。 このため、未定義の文字列の前には定義済みのワードを置かなければなりません。
例としては ." (ドット・クォート)があります。これはその後ろに続く出力するテキストの前に置きます(訳注: ." をワードとして認識させるために、その間に空白を置かねばならない。これが他言語と比べて間違いやすいところ)。もう1つの例は CREATE (そしてすべての定義ワード)です。 現時点ではまだ定義されていない名前の直前に置かれます(訳注:各々ワードとして認識させるために、定義ワードと名前の間に空白を置かねばならない)。
この規則は参照したい定義済ワードにも適用されますが、通常の方法では実行されません。その一つの例として以下の FORGET があります。
FORGET TASK
構文としては FORGET は TASK が実行されないように、 TASK の前に置く必要があります。
ヒント
定義に引数を消費させます。
この構文規則は、Forth的に必要というより、優れたForthプログラミングの規則です。
発射台の番号を必要とし、適切なロケットを発射する LAUNCH というワードを書いているとしましょう。 この定義は、おおよそ次のようになります。
: LAUNCH ( pad#) LOAD AIM FIRE ;
3つの内部定義のそれぞれは、発射台番号という同じ引数が必要です。どこかに2つの DUP が必要です。 問題はどこですか? それらを LOAD と AIM の中に入れると、上の定義のように、それらを LAUNCH から除外することができます。 もしあなたがそれらを LOAD と AIM から除外するならば、あなたは次のように定義しなければなりません。
: LAUNCH ( pad#) DUP LOAD DUP AIM FIRE ;
慣例により、後者の方が望ましいです、なぜなら LOAD と AIM はきれいだからです。 それらはあなたがそれらに期待することをします。 あなたが READY を定義しなければならないなら、あなたはそうすることができます。
: READY ( pad#) DUP LOAD AIM ;
慣例に従わなかった場合、以下のようにするハメになります。
: READY ( pad#) LOAD AIM DROP ;
ヒント
0から始まる番号を使います。
私たち人間は習慣から1で始まる番号を付けます。「第1、第2、第3」などです。一方、数学モデルは、ゼロから始めるとより自然です。 数学モデルに近親のコンピュータは数値プロセッサなので、ゼロから始まる番号を使用するとソフトウェアの記述が簡単になります。
例として、レコード長8バイトの表があるとします。 最初のレコードは表の最初の8バイトを占めます。 その開始アドレスを計算するために、 TABLE に "0"を追加します。 「2番目」のレコードの開始アドレスを計算するには、「8」を TABLE に追加します。

図 47 レコード長8バイトの表
これらの結果を達成するための公式を導き出すのは簡単です。
| 1番目のレコードの開始は | 0 × 8 = | 0 |
| 2番目のレコードの開始は | 1 × 8 = | 8 |
| 3番目のレコードの開始は | 2 × 8 = | 16 |
レコード数(record#)をそのレコードが始まるアドレスに変換するワードを簡単に書くことができます。
: RECORD ( record# -- adr )
8 * TABLE + ;
したがって、コンピュータの観点では、「最初のレコード」を0番目のレコードと呼ぶのが理にかなっています。
あなたの要件が1から始まる番号付けを要求しても大丈夫です。 設計全体でゼロから始まる番号を使用してから、「ユーザ用語集」(エンドユーザが使用する一連のワード)にのみ、ゼロから1への相対番号の変換を含めます。
: ITEM ( n -- adr) 1- RECORD ;
ヒント
アドレスをカウントの前に置きます。
繰り返しになりますが、これは規約であり、Forthの要求ではありませんが、そのような規約は読み取り可能なコードには不可欠です。 この規則の例は TYPE 、 ERASE 、そして BLANK の中にあります。
ヒント
ソースをディスティネーションに先行させます。
読みやすさに関するもう1つの規約。 例えば、いくつかのシステムでは、以下のフレーズ、
22 37 COPY
は、スクリーン22をスクリーン37にコピーします。以下の CMOVE の構文には、この規則と前の規則の両方が組み込まれています。
source destination count CMOVE
ヒント
(入力ストリーム内で)期待するのを避けてください。
一般に、入力ストリームに他の指定のワードがあると想定するワードを作成しないようにしてください。
画面の色が、値1で青を表し、9で水色を表すと仮定します。2つのワードを定義したいとします。 BLUE は1を返します。 LIGHT 9を生成するために BLUE の前に置くことができます。
Forthでは、 BLUE を定数として定義することが可能で、実行されると常に1を返します。
1 CONSTANT BLUE
そして、LIGHT を、入力ストリームの次のワードを探し、それを実行し、それを8でORするように定義します(このロジックは、この本の後半でこの例をもう一度見れば明らかになります)。
: LIGHT ( precedes a color) ( -- color value)
' EXECUTE 8 OR ;
fig-Forthでは、
: LIGHT [COMPILE] ' CFA EXECUTE 8 OR ;
(初心者のために: LIGHT の定義におけるアポストロフィはティック(tick)と呼ばれるForthのワードです。ティックはディクショナリ検索ワードで、名前を取ってディクショナリの中でそれを調べ、定義のアドレスを返します。この定義では、 LIGHT に続くワードのアドレス(たとえば BLUE )を探し、このアドレスを EXECUTE というワードに渡して、 BLUE を実行し、1をスタックにプッシュします。 BLUE を「取り込んだまま」、 LIGHT は1に8をORして9を生成します。)
この定義は入力ストリームで呼び出されたときにはうまくいきますが、コロン定義の中で LIGHT が呼び出されるようにしたいのであれば、特別な処理が必要です。
: EDITING LIGHT BLUE BORDER ;
入力テキストの中でさえ、ここでの EXECUTE の使用は、 LIGHT の後に定義されたワード以外の何かが誤って続いた場合にクラッシュを引き起こします。
この特定の構文を使わざるを得ない場合には、後述のように、 LIGHT でフラグを設定し、そのフラグが設定されているかどうかを BLUE で判断することをお勧めします。
入力ストリームを先読みすることが望ましい、時には必要な場合もあります。 (提案された TO 解決策はしばしばこのように実装されています [rosen82] )。
しかし、一般的には期待するのを避けてください。 それはあなた自身の失望を準備することです。
ヒント
コマンドそれ自身に実行させなさい。
この規則は「期待を避ける」の必然的な結果です。ワードに独自の働きをさせることは、Forth哲学の奇妙なことの1つです。 図 48 の「FORTH COMPILER」(Forthコンパイラ、コロン定義をコンパイルする関数)を見てください。 規則はほとんどありません。
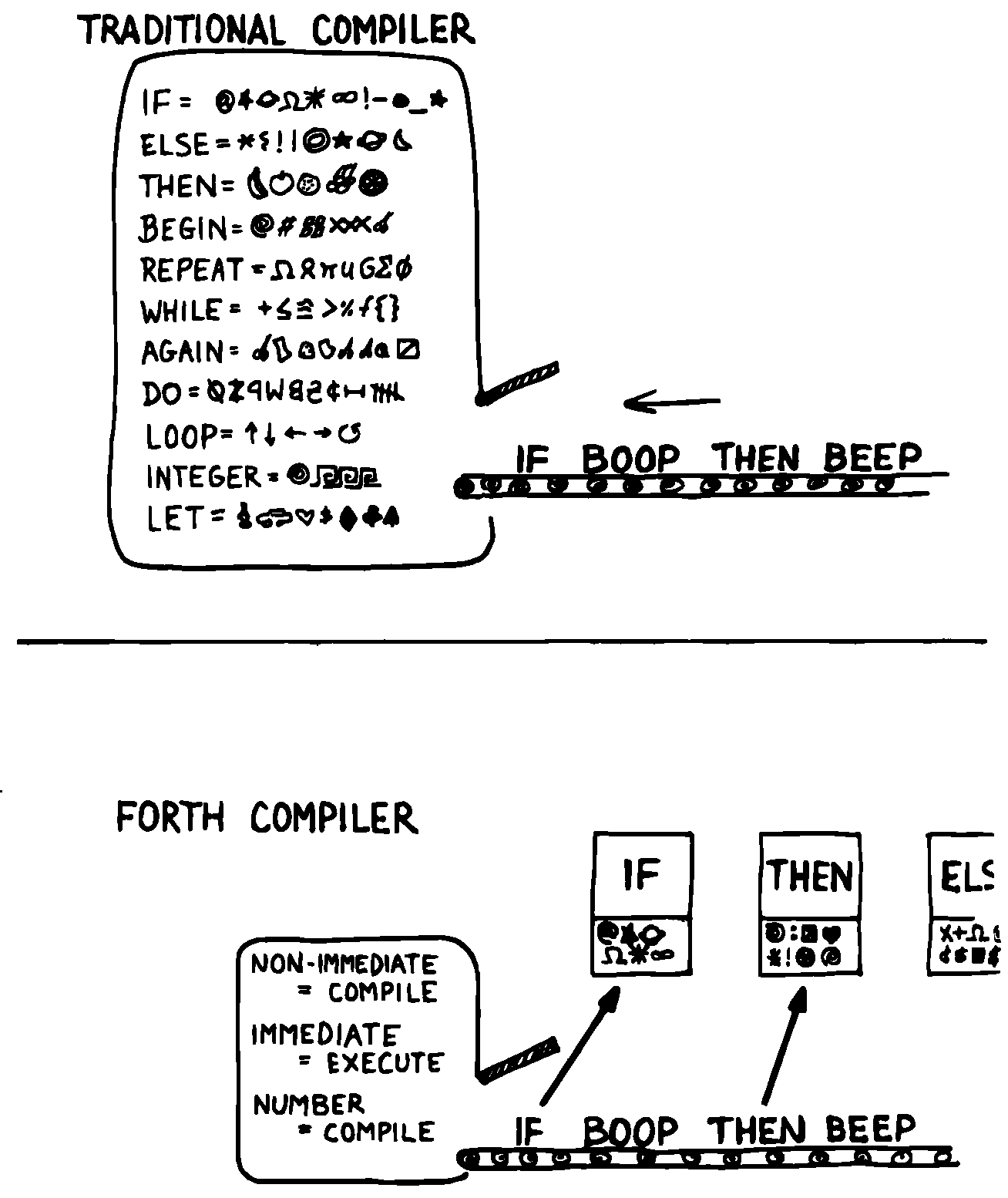
図 48 伝統的なコンパイラ 対 Forthコンパイラ
- 入力ストリームの次のワードをスキャンしてディクショナリで調べます。
- 普通のワードであれば、そのアドレスを「コンパイル」します。
- 「immediate」(即実行)のワードの場合は、「実行」します。
- 定義されていないワードであれば、それを数字に変換してリテラルとしてコンパイルを試みます。
- それが数値ではない場合は、エラーメッセージを出力して中止(アボート)します。
IF, ELSE, THEN などのコンパイルワードについては何も言及されていません。コロンコンパイラはこれらのワードについて知りません。 それは単に特定のワードを「immediate」(即実行)として認識し、それらを実行して、それら自身に仕事をさせるだけです(FORTH入門 第11章 の コロンコンパイラの制御方法 P.358 s参照; Starting Forth, Chapter Eleven, “How to Control the Colon Compiler.”)
コンパイラは、いつコンパイルを停止するかを知るためにセミコロンを「探す」ことすらしません。 代わりに、セミコロンを「実行」して、定義を終了してコンパイラを停止する作業を実行できるようにします。
このアプローチには2つの大きな利点があります。 まず、コンパイラは非常に単純で、数行のコードで記述できます。 第二に、あなたがいつでも追加できる編集可能なワードの数に制限はありません、ただそれらをimmediate(即実行)にすることによって。 これにより、Forthのコロンコンパイラでさえ拡張可能です!
ForthのテキストインタプリタとForthのアドレスインタプリタも同じ規則に従います。
この章で、おそらく最も重要なのが以下のヒントです。
ヒント
Forthシステムを使うことができる時は、あなた自身のインタプリタ/コンパイラを書かないでください。
あるクラスのアプリケーションは、特別な目的の言語、つまり1つの特定のことを実行するための自己完結型のコマンドのセットに対するニーズに応えます。 例としては、機械語アセンブラがあります。 ここにはたくさんのコマンド群、ニーモニックがあり、それを使って組み立てたい命令を記述することができます。 ここでもまた、Forthは主流の哲学と果断に決別します。
従来のアセンブラは特殊目的のインタプリタです。つまり、ADD、SUB、JMPなどの認識されたニーモニックを探してアセンブリ言語のリストをスキャンし、それに応じて機械語命令をアセンブルする複雑なプログラムです。 ただし、Forthアセンブラは、それ自体が機械命令を組み立てるForthのワードの単なる用語集です。
特殊目的言語の例は他にもたくさんあり、それぞれが個々のアプリケーションに固有のものです。 たとえば以下のようなのがあります。
もしあなたがアドベンチャーゲームを構築しているのであれば、あなたは以下のように、モンスターや部屋などを作成したり記述したりすることができる言語を書きたいと思うでしょう。
ROOM DUNGEON
次に、部屋に関連付けられている目に見えないデータ構造を構築して、部屋の属性を説明する一連のワードを作成します。
EAST-OF DRAGON-LAIR WEST-OF BRIDGE CONTAINING POT-O-GOLD etc.
このゲーム構築言語のコマンドは、Forthをインタプリタとした、単純にForthのワードにすることができます。
プログラマブルアレイロジック(PAL)デバイスを使用している場合は、入力ピンの状態に基づいて、出力ピンの動作を論理的に表現できる形式の表記法が必要です。 PALライターは、Michael Stolowitz [stolowitz82] によってForthで非常にシンプルに書かれました。
アプリケーションを操作するために一連のユーザメニューを作成する必要がある場合は、まずメニューコンパイル言語を開発することをお勧めします。 この新しい言語の言葉は、アプリケーションプログラマが必要なメニューをすばやくプログラムできるようにしながら、罫線の描画方法、カーソルの移動方法などに関する情報を隠します。
これらの例はすべて、通常のForthインタプリタを使用して、特殊目的のインタプリタやコンパイラを記述することなく、Forthの用語集としてコーディングできます。
- ムーアは言います。
シンプルな解決策は、関連性のない問題をあいまいにしないものです。 問題について何かが必要であると考えられます。
それは特殊なインタプリタです。しかし、あなたが特殊なインタプリタを見るたびに、それは問題に関して特に厄介な何かがあることを意味します。厄介でない事はまずありません。
あなたがあなた自身のインタプリタを書くのであれば、インタプリタはほぼ確実にあなたのアプリケーション全体の中で最も複雑で精巧な部分です。 あなたは問題解決よりもインタプリタを書くことへ集中します。
プログラマはインタプリタを書くのが好きだと思います。 彼らはこの手の手の込んだ難しいことをやりたいのです。 しかし、早晩、キーパッドのプログラミングや数値の2進数への変換をやめて、問題そのものを解決し始めなければならなくなる時が来ます。
アルゴリズムとデータ構造¶
第2章 では、インターフェースと規則の観点から問題の要件を記述する方法を学びました。 この節では、各コンポーネントの概念モデルを、明確に定義されたアルゴリズムとデータ構造に改良します。
アルゴリズムは、特定のタスクを実行するための、有限数の規則として記述された手順です。 規則は明確で、有限数の適用後に終了することが保証されている必要があります(アルゴリズムという言葉は、9世紀のペルシャの数学者アル・フワーリズミーに由来します)。
「これらの文字を年代順に並べ替えてください」など、人間が言う不正確な指令と、 BEGIN 2DUP < IF … などのコンピュータ言語の正確な指令との中間に、以下のようにアルゴリズムがあります。
- ソートされていない手紙を受け取り、その日付を書き留めます。
- 対応する年・月の連絡先フォルダーを見つけます。
- あなたの手元の手紙より後の日付の最初の手紙が見つかるまで、フォルダの先頭から手紙をめくっていきます。
- あなたの手元の手紙をその手紙の直前に挿入します(フォルダが空の場合は、単に手紙をフォルダに入れるだけです。)
同じ仕事のためにいくつかの可能なアルゴリズムがあるかもしれません。 上記のアルゴリズムは、10通入りのフォルダではうまく機能しますが、100通入りのフォルダでは、おそらく次のようなより効率的なアルゴリズムに頼ることになるでしょう。
- 同上
- 同上
- 日付がその月の前半にあたる場合は、そのフォルダの手前3分の1以内を開きます。その時見つかった手紙が手元の手紙より後の日付である場合は、同じ日付または手元の日付より前の日付の手紙を探し、その時点で手元の手紙を挿入します。 見つかった手紙が現在の手紙より前の日付である場合は、後方検索…
…あなたは手紙を挿入する場所を見つけます。この2番目のアルゴリズムは最初のものよりも複雑です。 ただし、実行時には、平均して必要な手順が少なくなり(毎回フォルダの先頭から検索開始する必要がないため)、実行時間が短縮されます。
データ構造とは、特に問題に合わせて編成された、データの配置またはデータの場所です。 最後の例では、フォルダを含むファイルキャビネットと個々の手紙を含むフォルダはデータ構造として考えることができます。 新しい概念モデルには、ファイリングキャビネットとファイリングフォルダ(データ構造)、およびファイリングを実行するための手順(アルゴリズム)が含まれています。
計算 対 データ構造 対 ロジック¶
前に述べたように、問題に対する最善の解決策は最もシンプルで適切なものです。 どんな問題でも、私たちは最もシンプルなアプローチのために努力すべきです。
次の仕様を満たすコードを書かなければならないとします。
if the input argument is 1, the output is 10
if the input argument is 2, the output is 12
if the input argument is 3, the output is 14
私たちはがとることのできる3つのアプローチがあります。
- 計算
( n) 1- 2* 10 +
- データ構造
CREATE TABLE 10 C, 12 C, 14 C, ( n) 1- TABLE + C@
- ロジック
( n) CASE 1 OF 10 ENDOF 2 OF 12 ENDOF 3 OF 14 ENDOF ENDCASE
この問題では、計算が最もシンプルです。 十分仕様を満たしていると仮定すると(速度は重要ではありません)、計算が最適です。
角度をサインとコサインに変換する問題は、データ構造を使用するよりも答えを計算することによって(少なくともコード行とオブジェクトサイズに関して)より簡単に実装できます。 しかし、しょっちゅう変換が必要な多くのアプリケーションでは、メモリに格納された表で答えを調べる方が速いです。 この場合、最もシンプルな「適切な」解決策はデータ構造を使用することです。
第2章 では電話料金の問題を紹介しました。 その問題では、料金レートは任意であるように見えたので、データ構造を設計しました。
| Full Rate | Lower Rate | Lowest Rate | |
|---|---|---|---|
| First Min. | .30 | .22 | .12 |
| Add’1 Mins. | .12 | .10 | .06 |
データ構造を使用することは、これらの値を計算することができる式を発明することを試みるよりも簡単でした。 そして式は後で不可である事が判明するかもしれません。 この場合、表駆動型コードの方が保守が簡単です。
第3章 では、決定表を使ってタイニー・エディタ用のキーストロークインタプリタを設計しました。
| Key | Not-Inserting | Inserting |
|---|---|---|
| Ctrl-D | DELETE | INSERT-OFF |
| Ctrl-I | INSERT-ON | INSERT-OFF |
| backspace | BACKWARD | INSERT< |
| etc. |
ロジックでも同じ結果が得られたはずです。
CASE
CTRL-D OF 'INSERTING @ IF
INSERT-OFF ELSE DELETE THEN ENDOF
CTRL-I OF 'INSERTING @ IF
INSERT-OFF ELSE INSERT-ON THEN ENDOF
BACKSPACE OF 'INSERTING @ IF
INSERT< ELSE BACKWARD THEN ENDOF
ENDCASE
しかしロジックはもっと混乱しています。 また、元の設計で表が使用されていなかった場合、このような複数条件アルゴリズムを表現するためのロジックの使用はさらに複雑になります。
結果が計算できない場合、または決定が決定表を正当化するほど複雑でない場合は、ロジックの使用が推奨されます。第8章 ではあなたのプログラムでのロジックの使用を最小限にするという問題に専念しています。
ヒント
問題解決にどのアプローチを適用するかを選択する際には、次の順序で優先順位を付けてください。
- 計算(スピードカウント時を除く)
- データ構造
- ロジック
もちろん、Forthなどのモジュール式言語の優れた機能の1つは、コンポーネントの実際の実装(計算、データ構造、ロジックのいずれを使用する場合でも)が、アプリケーションの他の部分から見えなくてもよいことです。
ローマ数字の問題とその解決¶
この節では、用語集を設計するプロセスを説明します。 単に問題とその解決策を提示するのではなく、私は一緒になってこの問題を解決できることを願っています(この問題を最初に解決したときは、自分の思考プロセスを記録していました)。あなたは前述の問題解決ガイドラインの要素をここでも見ることになりますが、それらが一見不自然な順序で適用されるを見ることになるでしょう。でも現実はこの順序なのです。
さあ初めましょう。問題は、スタック上の数を消費し、それをローマ数字として出力する定義を書くことです。
この問題は、大規模システムのコンポーネントの一つである可能性が最も高いです。 この問題を解決する過程で、データ構造を含むいくつかのワードを定義することになるでしょう。 しかし、この特定の用語集には ROMAN という名前が1つだけ含まれており、スタックから引数を取ります(他のワードはコンポーネントの内部にあります)。
このように外部構文を決定したので、次にアルゴリズムとデータ構造を考え出すことに進むことができます。
私たちは科学的な方法に従います。現実を観察し、解決策をモデル化し、現実に照らし合わせて検証し、解決策を修正します。 ローマ数字について私たちが知っていることを思い出すことから始めましょう。
実際、私たちはローマ数字に関する正式な規則は覚えていません。 しかし、あなたが私たちに数字を与えれば、私たちはそれからローマ数字を作ることができます。 私たちその方法を知っていますが、まだその手順をアルゴリズムとして述べることができません。
それでは、最初の10個のローマ数字を見てみましょう。
I
II
III
IV
V
VI
VII
VIII
IX
X
少々観察してみます。まず、tally(訳注:数え方の一つ。日本でいう正の字)というアイデアがあります。ここでは、その数を多くすることで数字を表します(3 = III)。 一方、特殊記号はグループを表すために使用されます(5 = V)。 実際、特殊シンボルを使用する前に、3つ以上の「I」が連続していることはできないようです。
第二に、「5」の前後に対称性があります。 「5」の記号「V」と「10」の記号「X」があります。 パターンI、II、IIIは後半に繰り返されますが、先行するVが付きます。
「5より1つ小さい」は「IV」と書かれ、「10より1つ小さい」は「IX」と書かれます。 大きな値のシンボルの前に「I」を置くことは、「…より1つ小さい」と言っているようです。
これらは曖昧でぼんやりとした観察です。 しかし、それで大丈夫です。 私たちにはまだ全体像はわかりません。
10以上で何が起こるのか調べてみましょう。
XI
XII
XIII
XIV
XV
XVI
XVII
XVIII
XIX
XX
これは前とまったく同じパターンで、前に余分な「X」が付きます。 そう、それは全くもって10のサイクルの繰り返しです。
「20」代を見ると、2つの「X」が付いていて同じです。 「30」代は「X」が3個付いています。実際、「X」の数は、元の10進数の10桁目の数と同じです。
これは重要な観察のように思えます。つまり私たちは10進数値を10進数字に分解し、それぞれの数字を別々に扱うことができます。 例えば、37(三十七)は以下のように書くことができます。
XXX (三十)
に続いて
VII (七)
時期尚早かもしれませんが、私たちはすでにForthが数値を10進数に分解する方法を見る事ができます。たとえば、Forthでは以下のようにして数値を数字に分解します(10で割った剰余)。
37 10 /MOD
スタックに7と3が得られます(商である3が一番上になります)。
しかし、これらの観察には疑問を投げかけます。「10」以下では「10」の位の場所がありません。これは特別な場合でしょうか?各「X」が10を表すと考えるならば、「X」の不在はゼロを表します。 だから特別なケースではありません。 私たちのアルゴリズムは、10未満の数でも動作します。
「10」のサイクルに特に注意を払いながら、観察を続けましょう。 40が「XL」であることがわかります。これは、4が「IV」であるのに似ていますが、10の値だけシフトされています。 「L」の前の「X」は、「50より10小さい」を意味します。
L 50 is analogous to V 5
LX 60 is analogous to VI 6
LXX 70 is analogous to VII 7
LXXX 80 is analogous to VIII 8
XC 90 is analogous to IX 9
C 100 is analogous to X 10
どうやら同じパターンがどんな10進数にもあてはまる。但し、シンボルだけが変わる。 とにかく、今では基本的に10進法を扱っていることは明らかです。
これを押し進めれば、アルゴリズムとデータ構造の組み合わせを使用して、1から99までのローマ数字を出力するためのシステムのモデルを構築することさえ可能です。
データ構造¶
| One`s Table | Ten`s Table | ||
| 0 | 0 | ||
| 1 | I | 1 | X |
| 2 | II | 2 | XX |
| 3 | III | 3 | XXX |
| 4 | IV | 4 | XL |
| 5 | V | 5 | L |
| 6 | VI | 6 | LX |
| 7 | VII | 7 | LXX |
| 8 | VIII | 8 | LXXX |
| 9 | IX | 9 | XC |
アルゴリズム¶
nを10で割ります。商は10の桁です。 余りは1の桁です。 10の位の表で10の位の数字を検索し、対応する記号パターンを出力します。 1の位の表で1の位の数字を調べて、対応する記号パターンを出力します。
例えば、数が72であれば、商は7で、余りは2です。10の位表の7は「LXX」に対応するので、それを出力します。 1の位の表の2が「II」に対応するので、それを出力してください。 その結果は以下です。
LXXII
私たちは、1から99までの数字で機能するモデルを作成しました。それより大きい数字でも、100での最初の除算とともに、百の位の表も必要になります。
ここで説明した論理モデルは、それが仕事をしている限りは問題ないかもしれません。 しかし、なぜか私たちが問題を完全に解決したようには思えません。 一連の表にすべての可能な組み合わせを格納することによって基本的なパターンを作成する方法を考え出すのを避けました。 この章の前半では、可能であれば、データ構造を使用するよりも答えを計算する方が簡単であることを確認しました。
この節ではアルゴリズムの考案について説明しますので、最後までやりましょう。 基本的な記号セットだけを使用して、任意の数字を生成するための一般的なアルゴリズムを探してみましょう。 私たちのデータ構造には、以下の情報が含まれているはずです。
| I | V | |
| X | L | |
| C | D | |
| M |
正しいと思われる方法でシンボルの配列を「整理」してみました。左の列の記号はすべて10の倍数です。 右側の列の記号は5の倍数です。 さらに、各行のシンボルは、そのすぐ上のシンボルの10倍の値を持ちます。
もう1つの違いは、最初の列の記号をすべて「XXXIII」のように倍数で組み合わせることができるということです。ただし、VVVのように、右の列の記号の倍数を指定することはできません。 この観察は使えますか? みんな分かってる?
左の列のシンボルを ONERS と呼び、右の列のシンボルを FIVERS と呼ぶことにしましょう。 ONERS は値1、10、100、1000を表します。つまり10進数で配置可能な「1」のいずれかです。 FIVERS は5、50、500を表します。つまり10進数で配置可能な「5」のいずれかです。
シンボル自体の代わりにこれらの語を使用して、任意の数字を生成するためのアルゴリズムを表現できるはずです(なお、「種類」のシンボルから実際のシンボルを除外しています)。たとえば、次の予備的なアルゴリズムを述べることができます。
どの桁でも、値を合計するのに必要なだけの数のONERSを出力します。
したがって、300の場合は「CCC」、20の場合は「XX」、1の場合は「I」になります。ゆえに、321の場合は「CCCXXI」になります。
このアルゴリズムは、数字が4になるまで機能します。そして今や、以下の例外をカバーするようにアルゴリズムを拡張する必要があります。
値を足すために必要なだけONERSを出力しますが、数字が4の場合はONERを出力してからFIVERを出力します。 したがって、40は「XL」です。 4は「IV」です。
この新しい規則は、数字が5になるまで機能します。前に気づいたように、5以上の数字は FIVER 記号で始まります。 それでは、再び規則を拡張します。
数字が5以上の場合、FIVERで始めて値から5を引いてください。 それ以外の場合は何もしません。 それから値を合計するのに必要なだけ多くのONERSを出力します。 しかし、数字が4の場合、ONERとFIVERだけを出力します。
この規則は、数字が9になるまで機能します。この場合、私たちは、より高い位(表の次の行)の ONER の前に ONER を出力しなければなりません。これを TENER と呼ぶことにしましょう。この規則の完全なモデルは以下です。
数字が5以上の場合、FIVERで始めて値から5を引いてください。 それ以外の場合は何もしません。 それから、値を合計するのに必要なだけ多くのONERSを出力します。 しかし、数字が4の場合はONERとFIVERだけを出力し、9の場合はONERとTENERだけを出力します。
今や私たちのアルゴリズムの文章版があります。しかし、それをコンピュータ上で実行できるようにするにはまだいくつかの段階があります。
特に、例外についてはもっと具体的に説明する必要があります。 私たちはまだ説明することができません。
aとbとcをしてください。 しかし ある場合と、とある場合には、違うことをしてください。
けれども、コンピュータはそれ以降を調べる前に既にa、b、cを実行してしまっています。
代わりに、他のことをする前に例外が「適用されるかどうか」をチェックする必要があります。
ヒント
アルゴリズムを考案する際は、例外を最後に考慮してください。 一方、コードを書く際には、まず例外を処理します。
これは、数字を生成するワードの一般的な構造について私たちに何かを伝えています。 4と9例外のためのテストから始めなければならないでしょう。 どちらの場合も、例外のテストに応じて対応します。 どちらの例外も適用されない場合は、「通常の」アルゴリズムに従います。 以下に疑似コードを示します。
: DIGIT ( n ) 4-OR-9? IF special cases
ELSE normal case THEN ;
経験豊富なForthプログラマは、実際にはこの疑似コードを書き出しませんでしたが、特別な場合を排除するため頭の中で構造を思い浮かべる可能性があります。 経験の浅いプログラマーであれば、ここで行ったように、ダイアグラムまたはコードで構造を捉えると便利な場合があります。
Forthでは、ロジックへの依存を最小限に抑えるよう試みます。しかし、この場合、除外する必要がある例外があるため、条件付きの IF が必要です。 それでも、この定義の IF THEN の数を1つに制限することで、制御構造の複雑さを最小限に抑えました。
ええ、私たちはまだ4の場合と9の場合をを区別する必要がありますが、その構造上の次元は下位レベルの定義(4または9のテストおよび「特殊ケース」コード)に延期しました。
私たちの構造が本当に言っているのは、4の例外または9の例外が通常の場合の実行を禁止しなければならないということです。 以下のバージョンのように、単に各例外をテストするだけでは不十分です。
: DIGIT ( n ) 4-CASE? IF ONER FIVER THEN
9-CASE? IF ONER TENER THEN
normal case... ;
なぜなら通常の場合が除外されることは決してないからです。( ELSE は IF と THEN の間に現れなければならないので、通常の直前に ELSE を置く方法はありません。)
4の例外と9の例外を別々に処理することを主張する場合は、例外が発生したことを示す追加のフラグを渡すように各例外に手配することができます。 これらのフラグのどちらかが真であれば、通常の場合を除外することができます。
: DIGIT ( n ) 4-CASE? DUP IF ONER FIVER THEN
9-CASE? DUP IF ONER TENER THEN
OR NOT IF normal case THEN ;
しかし、このアプローチは不必要に新しい制御構造を追加することになり、定義を複雑にします。 そのままにしておきます。
これで、主な定義の構造についての一般的な考え方がわかりました。
私たちは言いました。「数字が5以上の場合は、 FIVER で始め、値から5を引いてください。 それ以外の場合は何もしません。 それから、値を合計するのに必要なだけ多くの ONERS を出力してださい。」
これらの規則をForthに直接変換すると、次のようになります。
( n) DUP 4 > IF FIVER 5 - THEN ONERS
これは技法的には正しいですが、剰余除算の手法に精通している場合、これを剰余除算の5での自然な状況と見なすことができます。数値を5で除算すると、商は0(偽)になります。 数字は5未満で、5から9の間は1(真)です。これを先頭の FIVER が必要かどうかを示すためにブールフラグとして使用できます。
( n ) 5 / IF FIVER THEN ...
商(フラグ)は IF の引数になります。.
さらに、5を除数とする除算の剰余は常に0から4の間の数です。つまり、(例外を除くと) ONERS への引数として剰余を直接使用できます。 私達はフレーズを以下のように修正します。
( n ) /MOD IF FIVER THEN ONERS
その例外にもどると、 4-OR-9? の名前の通り、4と9の両方を1回でテストできることが分かりました。以下のように、残りが4の場合、最初に5の /MOD を実行してから例外をテストすることができることを示唆しています。
: DIGIT ( n )
5 /MOD OVER 4 = IF special case ELSE
IF FIVER THEN ONERS THEN ;
(消費せずに4と比較できるように、剰余を OVER (訳注: 剰余 商 -- 剰余 商 剰余)しました。)
結局、二重にネストされた IF THEN にしました。しかし、 IF THEN が特別な場合を扱っているので、それはもっともなことです。 もう1つ、短いフレーズ IF FIVER THEN は別の定義にする価値はほとんどありません。この辺りは好みです。分けても構いません。
特別な場合のコードに注目しましょう。 そのアルゴリズムは、「数字が4の場合は ONER と FIVER を出力します。数字が9の場合は ONER と TENER を出力します。
数字はどちらか一方になると仮定することができます。そうでなければ、この定義を実行することは決してありません。 問題は、それをどうやって見分けるのかということです。
繰り返しになりますが、5の除算の商を使用できます。 商がゼロの場合、数字は4以下でなければなりません。商がゼロでなければ数字は9以下です。だから私たちは同じトリックを弄して、ブーリアンフラグとして商を使用します。 私たちは以下のように書きました。
: ALMOST ( quotient )
IF ONER TENER ELSE ONER FIVER THEN ;
振り返ってみると、我々はどちらかの方法で ONER を出力していることに気づきます。 定義を次のように単純化することができます。
: ALMOST ( quotient )
ONER IF TENER ELSE FIVER THEN ;
スタックには使用する商があると仮定しました。 DIGIT の定義に戻り、実際に行ったことを確認しましょう。
: DIGIT ( n )
5 /MOD OVER 4 = IF ALMOST ELSE
IF FIVER THEN ONERS THEN ;
商だけでなく、その下にも余りがあることがわかります。 ELSE 句を実行した場合でも、両方をスタックに保持しています。 しかし、 ALMOST というワードは商を必要とするだけです。 それで、対称性のために、剰余の部分を以下のように DROP (訳注: n -- ;スタックトップを単に捨てる)しなければなりません。
: DIGIT ( n )
5 /MOD OVER 4 = IF ALMOST DROP ELSE
IF FIVER THEN ONERS THEN ;
ここに、ローマ数字の1桁の数字を生成するための完全なコード化定義があります。 必要な補助定義を書く前に試してみたかったら、1つのシンボルのグループを出力するためにワードの用語集をすぐに定義することができます。以下の ONES の行をご覧下さい。
: ONER ." I" ;
: FIVER ." V" ;
: TENER ." X" ;
: ONERS ( # of oners -- )
?DUP IF 0 DO ONER LOOP THEN ;
これを ALMOST と DIGIT の定義を読み込む前に定義しておきます。
しかし、私たちはそれほどやけくそではありません。 いいえ、 ONER 、 FIVER 、 TENER というワードを定義するという問題に移ることを切望しているので、それらの記号はフォーマットしている10進数の数字に依存します。
先ほど作成したシンボル表に戻りましょう。
| ones | I | V |
| tens | X | L |
| hundreds | C | D |
| thousands | M |
下の行の OWNER である TENER も必要であることを私たちは観察しました。 表として実際に書かれるべきであるように思われます。

しかし、それは冗長に思えます。 それを避けることができますか? おそらく、次のように別のモデル、おそらく線形表を試すとします。
| ones | I V |
| tens | X L |
| hundreds | C D |
| thousands | M |
これで、各列の名前(“ones” “tens” など)がその列の1つを指すことを想像できます。 そこから、現在の ONER の1つ下のスロットに到達することで各列の FIVER を、2つの下のスロットに到達することで TENER を取得することもできます。
3本の手で腕を組むようなものです。図 49 (a)のようにそれを ONES 列に取り付けることもできますし、図 49 (b)のようにそれをtens列に取り付けることもできます。またはそれを任意の10のべき乗で取り付けられます。
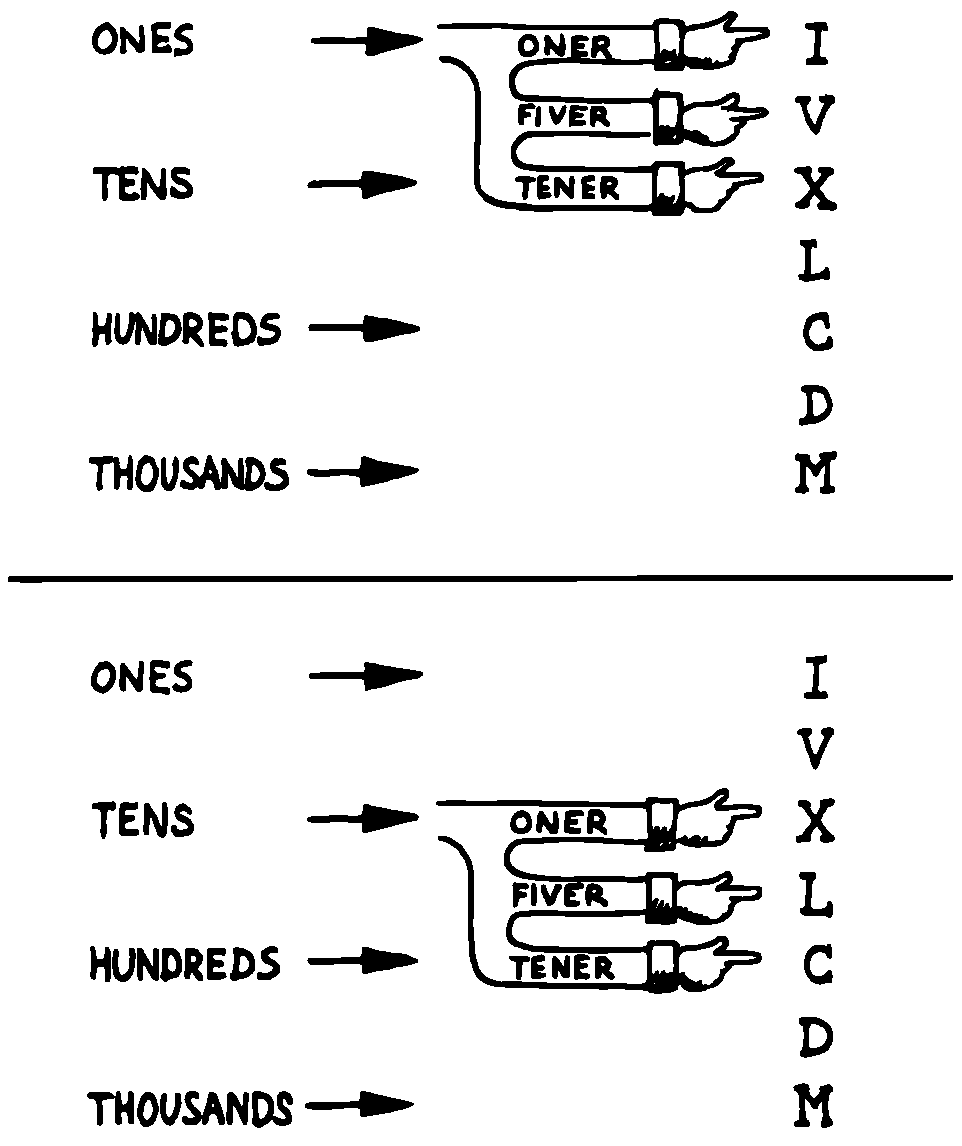
図 49 データ構造へのアクセスの機械的表現(3本の腕、可動腕)
熟練したForthプログラマーは、腕、手、またはそのようなものを想像することはほとんどありません。 しかし、コードでモデルを構築しようとする前に、強い精神的イメージ―右脳思考のもの―がなければなりません。
この右脳思考を学んでいる初心者は、以下の助言が役に立つと思うかもしれません。
ヒント
概念モデルについて考えるのが難しい場合は、それを機械的な装置として視覚化する(または描画する)。
私たちの表は単に文字の配列です。 文字は1バイトしか必要としないので、それぞれの「スロット」を1バイトにしましょう。 表を ROMANS と呼びます。
CREATE ROMANS ( ones) ASCII I C, ASCII V C,
( tens) ASCII X C, ASCII L C,
( hundreds) ASCII C C, ASCII D C,
( thousands) ASCII M C,
注意:この ASCII は STATE (訳注: -- f;コンパイル時なら0以外の値を返す)の状態にに依存します( 付録C 参照)。 またはそれが STATE の状態に依存しないようにするには、次のようにします。
CREATE ROMANS 73 C, 86 C, 88 C, 76 C,
67 C, 68 C, 77 C,
2つの異なるオフセットを同時に適用することで表から特定のシンボルを選択できます。 1つの次元は位取りを表します。1(ones)、10(tens)、100(hundreds)などです。この次元は「現在(current)」になります。つまり、変更するまでその状態は変わりません。
もう1つの次元は、現在の位取りの中で、欲しいシンボルの種類( ONER 、 FIVER 、TENER )を表します。 この次元は付随的なものです。つまり、毎回どのシンボルが必要かを指定します。
「現在(current)」の次元を実装することから始めましょう。 現在の10進数桁位置を指すための何らかの方法が必要です。 `` COLUMN#`` (カラム・ナンバー(column-number)と発音する)という名前の変数を作成し、それに表へのオフセットを含めます。
VARIABLE COLUMN# ( current offset)
: ONES O COLUMN# ! ;
: TENS 2 COLUMN# ! ;
: HUNDREDS 4 COLUMN# ! ;
: THOUSANDS 6 COLUMN# ! ;
これで、 ROMANS で与えられる COLUMN# の内容を表の先頭アドレスに追加することで、任意の「腕の位置」に進むことができます。
: COLUMN ( -- adr-of-column) ROMANS COLUMN# @ + ;
シンボルを表示するためのワードの1つを実装できるかどうか見てみましょう。 ONER から始めましょう。
私たちがONERでやりたいことは文字を出す( EMIT)ことです。
: ONER EMIT ;
逆からたどって、 EMIT はスタック上にASCII文字コードを必要とします。 どうやってそれを得るのですか? それには C@ を使います。
: ONER C@ EMIT ;
その C@ は、欲しい文字コードを含むスロットの「アドレス」を必要とします。 そのアドレスはどうやって取得するのですか?
ONER は可動腕の最初の「手」、つまり COLUMN がすでに指している位置です。だから、私たちが欲しいアドレスは単に COLUMN によって返されるアドレスです。
: ONER COLUMN C@ EMIT ;
それでは FIVER を書きましょう。 それは同じスロットアドレスを計算し、それからシンボルを取得してそれを出力する前に、次のスロットを取得するために1を追加します。
: FIVER COLUMN 1+ C@ EMIT ;
そして TENER は、
: TENER COLUMN 2+ C@ EMIT ;
これら3つの定義は重複しています。 それらの間の唯一の違いは付随的なオフセットであるので、我々は残りの定義から付随的なオフセットを除外することができます。
: .SYMBOL ( offset) COLUMN + C@ EMIT ;
いまや、私たちは以下のように定義できます。
: ONER O .SYMBOL ;
: FIVER 1 .SYMBOL ;
: TENER 2 .SYMBOL ;
私たちが今やるべきことは、完全な10進数値を一連の10進数数字に分解することだけです。 私たちがすでに行った観察に基づいて、これは簡単なはずです。 リスト 1 は完成したリストを示しています。
じゃーん! 問題から概念モデル、そしてコーディングまでできました。
注意:この解決策は最適ではありません。 この章では最適化フェイズは取り扱いません。
もう1つ考えるべきこととして、このアプリケーションを使用している人によっては、エラーチェックを追加することをお勧めします。 実際、私たちが知っている最高のシンボルはMです。 ここで表現できる最高値は3,999、つまりMMMCMXCIXです。
私たちはROMANを次のように再定義するかもしれません。
: ROMAN ( n)
DUP 3999 > ABORT" Too large" ROMAN ;
- ムーアは言います。
あなたが正しく行ったときには、正義の感覚があります。 Forthを他の言語と区別するのはそのような感覚かもしれません。 Forthでは、それは「なるほど!(Aha!)」反応です。 あなたは走り出して誰かに伝えたくなります。
もちろん、その感覚は正しく行ったあなただけが味わえるものです。
0 1 2 3 4 5 6 7 8 9 10 11 12 | \ Roman numerals 8/18/83
CREATE ROMANS ( ones) ASCII I C, ASCII V C,
( tens) ASCII X C, ASCII L C,
( hundreds) ASCII C C, ASCII D C,
( thousands) ASCII M C,
VARIABLE COLUMN# ( current_offset)
: ONES O COLUMN# ! ;
: TENS 2 COLUMN# ! ;
: HUNDREDS 4 COLUMN# ! ;
: THOUSANDS 6 COLUMN# ! ;
\
: COLUMN ( -- address-of-column) ROMANS COLUMN# @ + ;
\
|
0 1 2 3 4 5 6 7 8 9 10 11 12 | \ Roman numerals cont'd 8/18/83
: .SYMBOL ( offset -- ) COLUMN + C@ EMIT ;
: ONER O .SYMBOL ;
: FIVER 1 .SYMBOL ;
: TENER 2 .SYMBOL ;
\
: ONERS ( #-of-oners -- )
?DUP IF O DO ONER LOOP THEN ;
: ALMOST ( quotient-of-5/ -- )
ONER IF TENER ELSE FIVER THEN ;
: DIGIT ( digit -- )
5 /MOD OVER 4 = IF ALMOST DROP ELSE IF FIVER THEN
ONERS THEN ;
|
0 1 2 3 4 | \ Roman numerals cont'd 8/18/83
: ROMAN ( number --) 1000 /MOD THOUSANDS DIGIT
100 /MOD HUNDREDS DIGIT
10 /MOD TENS DIGIT
ONES DIGIT ;
|
要約¶
この章では、単一のコンポーネントを開発するために、まずその構文を決定し、それからにそのアルゴリズムとデータ構造を決定を進め、そしてForthでの実装を完結させました。
この章で私たちは設計の議論を終えました。 本の残りの部分では、スタイルとプログラミング手法について説明します。
更なる思考のために¶
コンポーネントを設計し、カードのシャッフルをシミュレートするのに必要なアルゴリズムを記述します。 あなたのアルゴリズムは、ランダムな順序で配置された0から51の数字の配列を生成します。
この問題の特別な制約は、もちろん、同じカードが配列内に2回現れることはないということです。
あなたはCHOOSEと呼ばれる乱数発生器を持ってるとしましょう。 スタック引数は n です。 0から n-1 までの乱数を生成します(邦訳:Forth入門の第10章の「知っていると便利です 乱数発生器」P.314 を参照(See the Handy Hint, Chapter Ten, Starting Forth ))。
あなたはそれがループの各回で不定数のスロットをチェックするという時間のかかる負担を避けるようにカードシャッフリングアルゴリズムを設計することができますか? 1つの配列だけを使ってそうすることができますか?
参考文献¶
| [polya] |
|
| [hart75] | Leslie A. Hart, How the Brain Works , (C) 1975 by Leslie A. Hart, (New York, Basic Books, Inc., 1975). |
| [rosen82] | Evan Rosen, "High Speed, Low Memory Consumption Structures," 1982 FORML Conference Proceedings , p.191. |
| [stolowitz82] | Michael Stolowitz, "A Compiler for Programmable Logic in FORTH," 1982 FORML Conference Proceedings , p.257. |