第7章 データの取り扱い:スタックと状態¶
Forthは2つの方法のいずれかでデータを取扱います。それはスタックかデータ構造のいずれかです。この章の話題は、どのアプローチを使用するか、そしてスタックとデータ構造の両方をどのように管理するかです。
スタイリッシュ・スタック¶
Forthのワードがお互いに引数を渡す最も簡単な方法はスタックを使うことです。 スタックとの間で値をプッシュしたりポップしたりする作業はすべて暗黙的であるため、このプロセスは「シンプル」です。
- ムーアは言います。
- データスタックは、この「隠し情報」の概念を使用しています。 サブルーチン間で渡される引数は、呼び出しシーケンスでは明示的ではありません。 プログラマの意識レベルを下回っていても、まったく同じワードがまったく目に見えないほどたくさんのワードに波及している可能性があります。これは、単に明示的に言及する必要がないからです。
このアプローチの1つの重要な結果として、引数は名前が付けられていません。 それらは名前付き変数ではなく、スタック上にあります。 この効果はForthの優雅さの理由の1つです。 同時にそれは、不適切に書かれたForthコードが読めなくなる可能性がある理由の一つです。 この矛盾を探って見ましょう。
スタックの発明は、英語の代名詞の発明と似ています。以下の一節について考えてみましょう。
Take this gift, wrap it in tissue paper and put it in a box.
「gift(贈り物)」という言葉が一度だけ述べられていることに注意してください。 gift(贈り物)は、以後「それ(it)」と呼ばれます。
「それ(it)」構文が形式が張らない構文なので、英語が読みやすくなります(「それ(it)」を参照するものが明確である場合)。 そのため、スタックでは、暗黙的に引数を渡すことでコードが読みやすくなります。 プロセスへの引数の受け渡しではなく、プロセスを重視します。
私たちの代名詞への類推は、なぜ悪いForthがそれほど読めなくなる可能性があるかを示唆しています。 あまりにも多くのことが代名詞で参照されている場合、話し言葉は混乱します。
Take off the wrapping and open the box. Remove the gift and throw it away.
この箇所の問題は、一度に多くのものを参照するために「それ(it)」を使用していることです。 このエラーには2つの解決策があります。 最も簡単な解決策は、「それ(it)」の代わりに実際の名前を指定することです。
Remove the wrapping and open the box. Take out the gift and throw the box away.
あるいは、「前者(former)」と「後者(latter)」という言葉を紹介することもできます。しかし、最良の解決策は、当該箇所を再設計することです。
Remove the wrapping and open the present. Throw away the box.
Forthでは以下のような類似の観察結果があります。
ヒント
スタックを使用してコードを単純化してください。しかし、どの定義内でも深く積み重ねないでください。 再設計するか、最後の手段として、名前付き変数を使用します。
Forthの初心者の中には、体操選手が楽しく飛び跳ねるトランポリンのようにスタックをとらえる人が居ます。しかし、スタックはアクロバットではなくデータの受け渡しを目的としています。
では、どのぐらいの深さが「深すぎる」のでしょうか?一般的に、スタック上の3つの要素が1つの定義内で管理できる最大の要素です(。2倍長演算では、各「要素」は2つのスタック位置を占めますが、 2DUP 、 2OVER などの演算子によって論理的に単一の要素として扱われます)。
通常のスタック演算子の用語集は、 ROT が3番目のスタック項目にアクセスできる唯一のものです。 PICK と ROLL (これについてはすぐに説明します)以外に、それより深いものを見つける簡単な方法はありません。
私たちの類推を限界にまで広げると、スタック上の3つの要素は、3つの英語の代名詞「this(これ)」、「that(それ)」、および「t’other(その他)」に対応する可能性があります。
再設計¶
間違った向きのアプローチが厄介なスタック問題につながるケースを見てみましょう。+THRU の定義を書き込もうとしているとします( 第5章 の「リストの整理」の節の「相対ロード」の部分を参照)。 私たちはループ本体を以下のように定めました。
... DO I LOAD LOOP ;
つまり、 LOAD をループに入れてから、ロードされる絶対スクリーンに対応するようにインデックスと制限を調整します。
スタック上に最初にこれがあります。
lo hi
ここで、「lo」と「hi」は BLK からのオフセットです。
私たちは、以下のようにこれらを DO の為に並べ替える必要があります。
hi+1+blk lo+blk
最大の問題は両方のオフセットに BLK の値を追加することです。
すでに間違った方向に進んでいますが、私たちはまだそれを知りません。なので引き続き進みましょう。 私たちは以下のように試してみます。
lo hi
BLK @
lo hi blk
SWAP
lo blk hi
OVER
lo blk hi blk
+
lo blk hi+blk
1+
lo blk hi+blk+1
ROT ROT
hi+blk+1 lo blk
+
hi+blk+1 lo+blk
私たちははそれを作りました、しかし、酷いなコレ。
もし私たちが罪深き者なら、更に以下のコードを書いたでしょう。
BLK @ DUP ROT + 1+ ROT ROT +
と
BLK @ ROT OVER + ROT ROT + 1+ SWAP
3つのシーケンスはすべて同じことを行いますが、コードがぼやけているように見え、良くありません。
経験を重ねると、 ROT ROT の組み合わせを危険の兆候として認識することを学びます。つまり、スタックが混雑しすぎているためです。 代替案を考え出すまでもなく、私たちは問題を認識しています。「blk」のコピーを2つ作成すると、スタックには4つの要素ができます。
この時点では、最初の手段は通常リターンスタックです。
BLK @ DUP >R + 1+ SWAP R> +
(スタイリッシュ・リターン・スタックについては次節参照) ここでは DUP を付けて “blk” し、コピーの一つをリターン・スタックに保存し、コピーのもう一つを「hi」に追加します。
これは確かに改善です。 しかし読めますかコレ?
次に私たちは、「名前付き変数が必要かもしれません」と思います。もちろん1つは既にあります。それは BLK です。だから私たちは以下を試みます。
BLK @ + 1+ SWAP BLK @ +
だいぶ読みやすくなりました。それでもまだ長く冗長です。 BLK @ + は2回現れています。
BLK @ + がおなじみのようですね。最後に私たちの頭脳が閃きます。
私たちは、先ほど定義した +LOAD のソースを振り返ってみましょう。
: +LOAD ( offset -- ) BLK @ + LOAD ;
このワード、 +LOAD は仕事を為しているはずです。 私達が書かなければならないのは以下の通りです。
: +THRU ( lo hi ) 1+ SWAP DO I +LOAD LOOP ;
ここではより効率的なバージョンを作成していません。なぜなら、 BLK @ + の作業はループのすべてのパスで行われるためです。 しかし、私たちは、よりクリーンで、概念的によりシンプルで、より読みやすいコードを作成しました。 この場合、非効率は各ブロックがロードされるときにのみ発生するため、目立ちません。
問題を再設計すること、つまり問題を再考することは、状況が悪くなったらすぐにすべき道でした。
ローカル変数¶
ほとんどの場合問題は、スタック上で一度にいくつかの引数しか必要とされないように調整することができます。 しかし時折、あなたができることが何もない事があります。
以下がその最悪の例です。 以下の順番で座標として指定された、任意の2点間に線を引く LINE というワードがあるとします。
( x1 y1 x2 y2)
ここで、 x1,y1 は始点の、 x2,y2 は終点の x,y 座標をを表します。
続けて、この順番の4つの引数で、[BOX] と呼ばれる箱を描くワードを書かなければなりません。
( x1 y1 x2 y2)
ここで x1 y1 はボックスの左上隅の x,y 座標を表し、x2 y2 は右下隅の座標を表します。 スタック上に4つの要素があるだけでなく、ポイントからポイントへと線を引くときにそれらをそれぞれ複数回参照する必要があります。
4つの引数を取得するためにスタックを使用していますが、ボックスを描画するためのアルゴリズムの為には、スタックの特長は役立ちません。 急いでいる場合は、簡単な方法で脱出することをお勧めします。
VARIABLE TOP ( y coordinates top of box)
VARIABLE LEFT ( x " left side)
VARIABLE BOTTOM ( y " bottom)
VARIABLE RIGHT ( x " right side)
: [BOX] ( x1 y1 x2 y2) BOTTOM ! RIGHT ! TOP ! LEFT !
LEFT @ TOP @ RIGHT @ TOP @ LINE
RIGHT @ TOP @ RIGHT @ BOTTOM @ LINE
RIGHT @ BOTTOM @ LEFT @ BOTTOM @ LINE
LEFT @ BOTTOM @ LEFT @ TOP @ LINE ;
私たちがここで行ったことは、各座標に1つずつ、4つの名前付き変数を作成することです。 [BOX] が最初に行うことは、これらの変数にスタックからの引数を入れることです。 次に、変数を参照して4本の線が描かれます。 これらのような定義内(または場合によっては用語集内)でのみ使用される変数は、「ローカル変数」と呼ばれます(訳注:他の言語で言う、構文・スコープ上他からアクセスできない「局所的」な変数ではないので注意。意味的な区別に過ぎない。)。
私は、ローカル変数を定義するのではなく、スタック上で可能な限り多くのことを試みることで、名プレイヤーを演じるという罪を何度も犯してきました。 この生意気な行為を避けなければならない理由は以下の3つです。
第一に、そのようにコーディングするのは面倒です。 第二に、結果は読めたものではありません。第三に、設計変更が必要になり、2つの引数の順序がスタック上で変わると、このすべての作業が無駄になります。 DUP 、 OVER 、 ROT は、問題を解決するためのものではなく、モノの場所をあっちこっち組み替えているだけでした。
この第三の理由を念頭に置いて、私は次のことをお勧めします。
ヒント
特に設計段階では、すぐに使用する引数だけをスタックに残してください。 他のためにはローカル変数を作成します(必要に応じて、最適化段階で変数を削除してください)。
第四に、定義が非常に時間的にクリティカルな場合、それらの扱いにくいスタック演算子(例えば ROT ROT )は実際に、クロックサイクルを使い果たす可能性があります。 変数に直接アクセスする方が速いです。
それが「本当に」時間的にクリティカルな場合は、とにかくアセンブラに変換する必要があるかもしれません。 この場合、すべてのデータがレジスタ内または間接的にレジスタを介して参照されるため、スタックに関するすべての問題が発生します。 幸いなことに、最も扱いにくいスタック引数を持つ定義は、多くの場合機械語で書かれたものです。 我々の [BOX] プリミティブはその一例です。 CMOVE> がもう一つの例です。
[BOX] で行ったアプローチは、確かに30分掛けてスタック上のアイテムをジャグリングするのに費やすドキドキよりは優れていますが、それは決して最善の解決策ではありません。 最低なのは、この1つのルーチン内で使用するためだけに、4つの名前付き変数、ヘッダー、およびすべてを作成することの費用です。
(辞書のヘッダを必要としないアプリケーションをコンパイルすることを目標としているならば、唯一の損失は変数のためのRAMの8バイトです。将来のForthシステムでは、ヘッダはとにかくメモリの他のページに分けられるかもしれません)。 繰り返しますが、この例は最悪の状況を表しており、ほとんどのForthアプリケーションではめったに発生しません。 ワードがよくファクタリング(要素分解)されているならば、それぞれのワードがすることはほんの少しになるように設計できています。。 ほんの少ししかすることがない無いワードでは、一般に引数はほとんど必要ありません。
ただし、この場合は、それぞれ2つの座標で表される2つの点を扱います。
設計を変更できるでしょうか? まず、 LINE はあまりに原始的なプリミティブ・ワードなのかもしれません。 必要に応じて任意の2点間に斜めに線を引くことができるので、4つの引数が必要です。
私たちの箱を描くとき、私たちは完全に垂直と完全に水平の線を必要とするだけです。この場合、これらの線を引くために、もっと強力ではあるが割と普遍的なワード VERTICAL と HORIZONTAL を書くことができます。 それぞれに必要な引数は3つだけです。開始位置のxとy、そして長さです。 この機能のファクタリング((要素分解)は [BOX] の定義を簡単にします。
または、以下の構文がユーザにとってより自然に感じられることを発見するかもしれません。
10 10 ORIGIN! 30 30 BOX
ここで ORIGIN! は箱が始まる位置(左上隅)を指す「原点(origin)」への2要素のポインタを設定します。 それから 30 30 BOX は原点から高さ30単位、幅30単位の箱を描きます。
このアプローチは設計の一部として BOX の為のスタック引数の数を減らします。
ヒント
スタックを介してではなくデータ構造を介してどの引数を処理するかを決定するときは、より永続的な引数、または現在の状態を表す引数を選択してください。
PICK と ROLL¶
PICK や ROLL というワードが好きな人もいます。 彼らはこれらのワードを使ってスタックのどの深さの要素にでもにアクセスします。 私はお勧めしません。まず、 PICK と ROLL はプログラマがスタックを配列と考えることを奨励しますが、実際はそうではありません。スタックに非常に多くの要素があり、 PICK と ROLL が必要な場合は、それらの要素は代わりに配列に含まれるべきです。
第二に、彼らは、目の前で引数として渡されたものに対して定義を呼び出すのではなく、より間接的なレベルでスタックに残されている引数を参照することをプログラマに奨励します。これにより、定義は他の定義に依存します。 それは構造化されていない。危険です。
最後に、スタック上の要素の位置は、その上にあるものによって異なり、その上にあるものの数は常に変化します。 たとえば、4番目のスタック位置の下にアドレスがある場合は以下のように書くことができます。
4 PICK @
その内容を取得します。 しかし、あなたは以下のように書く必要があります。
( n) 5 PICK !
なぜなら、スタックに n があると、アドレスは現在5番目の位置にあるからです。 このようなコードは読みにくく、修正が困難です。
スタック図面の作成¶
解決するのが面倒なスタック状況があるときは、紙と鉛筆で解決するのが最善です。 図 52 のような書式を作る人もいます。 正式に(電話の請求書の裏面にではなく)このように行われている場合、スタック解説は素晴らしい補助資料として役立ちます。
スタックに関するヒント¶
ヒント
スタック効果がすべての可能な制御フローの下でバランスが取れていることを確認してください。
図 52 の CMOVE> のためのスタック解説では、内側の波括弧が DO…LOOP の内容を表しています。 ループから出るときのスタックの深さは、ループに入るときと同じです。1要素です。 外側の中括弧内では、 IF 節のスタック結果は ELSE 節の結果と同じです。1つの要素が残ります( THEN のところに「x」が付くように、残りの要素が何を表しているかは問題ではありません)。

図 52 スタック解説の例
ヒント
同じ数値で2つのことをするときは、最初にスタックの下に置く方の機能を実行してください。
例えば以下のように。
: COUNT ( a -- a+1 # ) DUP C@ SWAP 1+ SWAP ;
(あなたが最初にカウント( 1+ )を得るなら)もっと効率的に書く事ができます。
: COUNT ( a -- a+1 # ) DUP 1+ SWAP C@ ;
(あなたは最初にアドレスを計算します。)
ヒント
可能な場合は、可能な限りすべての戻り引数の数を同じにしてください。
あなたはしばしば何らかの仕事をする定義を見つけるでしょう、そして何かがうまくいかないなら、問題を特定するエラーコードを返します。 これがスタックインターフェースの設計方法の1つです。
( -- error-code f | -- t)
フラグがtrueの場合、操作は成功しました。 フラグがfalseの場合は失敗し、エラーの性質を示す別の値がスタックにあります。
ただし、インターフェイスを以下のように設計し直すと、スタック操作が簡単になります。
( -- error-code | O=no-error)
1つの値がフラグとしても(エラーの場合には)エラーコードとしても機能します。 負論理が使用されていることに注意してください。 ゼロ以外はエラーを示します。 エラーコードには、ゼロ以外の任意の値を使用できます。
スタイリッシュ・リターン・スタック¶
一時的な引数を保持するためのリターンスタックの使用についてはどうでしょうか?それは良いスタイルなのでしょうか?
何人かの人々はその使用に大いに立腹します。 しかし、リターンスタックは、特定のぎくしゃくしたスタックの詰まりに対して最も簡単な解決策を提供します。 前節の CMOVE> の定義を見てください。
この目的でリターンスタックを使用することにした場合は、意図した以外の目的でForthのコンポーネントを使用していることに注意してください。 (この章で後述する「コンポーネントの共有」という節を参照してください。)
ここで、あなたが自分の足を撃たないようにするためのいくつかの提案があります。
ヒント
- リターンスタック演算子を対称に保って下さい。
- リターンスタック演算子は、すべての制御フロー条件下で対称に保って下さい。
- 定義のファクタリング(要素分解)では、片方の部分にだけリターンスタック演算子が含まれてなかったり、対応が合ってないなんてことにならないように注意してください。
DO…LOOPの中で使われる場合、リターンスタック演算子はループ内で対称的でなければなりません、そしてIは>RとR>で囲まれたコードではもはや有効ではありません。
すべての >R に対して、同じ定義内に R> がなければなりません。 演算子は対称に見えることがありますが、それらは制御構造ではありません。 たとえば以下
... BEGIN ... >R ... WHILE ... R> ... REPEAT
この構造がアプリケーションの外側のループで使用されている場合は、突然爆発して終了するまで(おそらく数時間後)、すべて正常に動作します。 何が問題なのでしょう? 最後のループで R> はスキップされます。
変数に伴う問題¶
私たちはスタック上ですぐに関心のあるデータを処理しますが、変数に入れられた多くの情報に依存しており、繰り返しアクセスできるようになっています。 コードの一部は、そのデータがどのように使用されるのか、誰がそれを使用するのか、いつ使用されるのか、そしていつ使用されるのかについて必ずしも何かを知る必要なく、変数の内容を変更できます。 別のコードでは、変数の内容を取得して、その値がどこから来たのかを知らなくても使用できます。
値をスタックにプッシュするワードごとに、別のワードがその値を消費する必要があります。 このスタックは、郵便局のように、ポイントツーポイントの通信を可能にします。
一方、変数は任意のコマンドで設定でき、任意のコマンドで何度でもアクセス(または、全くアクセスしない事が)できます。落書きのように、目に止めた人は誰でも変数を利用できます。
したがって、変数は現在の状況を反映するために使用できます。
その時点での状態を利用する事にすると問題を単純化できます。 第4章 のローマ数字の例では、現在の桁位置を表すために変数 COLUMN# を使いました。 ONER 、 FIVER 、TENER というワード、どの種類のシンボルを表示するかを決定するためにこの情報に依存していました。 TENS ONER や TENS FIVER などのように、毎回両方の説明を指定する必要はありませんでした。
一方で、その時点の状態を利用する事は新しいレベルの複雑さを追加します。 最新の情報にするには、最初に変数またはある種のデータ構造を定義する必要があります。 他の部分がそれを設定する機会がある前に、私たちのコードの部分がそれを参照する可能性があるならば、それを初期化することを忘れないでください。
変数に関するより深刻な問題は、それらが「再入可能(リエントラント)」ではないということです。マルチタスクのForthシステムでは、ローカル変数を必要とする各タスクはそれ自身のコピーを持たなければなりません。 Forthの USER 変数はこの目的を果たします( Starting Forth Chapter 9、"Forth Geography";邦訳 FORTH入門 第9章「仮面の下に」参照)。
変数を参照する定義は、単一のタスク内でも、引数がスタックを介して渡される場合と異なり、テスト・検証・再利用するのが困難です。
ワープロ、エディタを実装しているとします。 現在のカーソル位置と前の改行文字との間の文字数を計算するルーチンが必要です。 そのため、現在位置( CURSOR @ )から始まり、0番目の位置まで、 DO…LOOP を使って改行文字を検索するワードを書きます。
ループが当該文字パターンを見つけたら、現在のカーソル位置からその相対アドレスを引きます。
its-position CURSOR @ SWAP -
それらの間の距離を決定します。
私たちのワードのスタック効果は以下のようになります。
( -- distance-to-previous-cr/lf)
しかし、のちのコーディングで、現在のカーソル位置ではなく任意の文字から最初の前の改行文字までの距離を計算するための同様のワードが必要なことが分かりました。 CURSOR @ を取り除き、開始アドレスをスタックの引数として渡すことができるようすると、以下のようになります。
( starting-position -- distance-to-previous-cr/lf)
変数への参照を括り出すことで、定義をより便利にしました。
ヒント
読みにくくなるまでスタックを乱雑にしない限り、引数を変数から引き出すのではなく、スタックを介して引数を渡すようにしてください。
- Koggeは言います。
Forthのモジュール性のほとんどは、Forthのワードを数学的な意味での「関数(function)」として設計および処理することによって得られます。 私の経験では、Forthのプログラマは通常、最も重要なグローバル変数以外のものを定義しないようにします(机の上に「変数を打ち出すヘルプ」という書き込みのある友人が居ます)。 つまり、参照透過性のあるワードを書こうとします。すなわち、同じスタック入力が与えられると、それが実行されるより大域的な文脈に関係なく、ワードは常に同じスタック出力を与えるでしょう。
実際、この性質は、ワードを単独でテストするときに使用するものとまったく同じです。 この性質を持たないワードはテストするのがかなり難しいです。 ある意味では、値が頻繁に変わる「名前付き変数」は、今どきは「禁止されている」GOTOの次に良くない代物です。
図 53 「高速移動する列車から大砲で撃ち出され、風車の羽根の間をくぐりぬけ、更に熱気球からぶら下がっているブランコをつかむなんて…あなたはエースだけど、あまりにも変数が多すぎたわ」
以前、スタック渋滞を排除するために、特に設計段階でローカル変数を使用することをお勧めしました。 その際、変数は1つの定義内でのみ参照されることに注意することが重要です。 私たちの例では、 [BOX] はスタックから4つの引数を受け取り、すぐにそれらをローカル変数にロードして使用します。 4つの変数はこの定義外では参照されず、ワードは単一の機能として安全に動作します。
暗黙のうちにデータを渡すことができる言語に慣れていないプログラマは、必要なだけスタックを利用するとは限りません。マイケル・ハムは、その理由はおそらくForthユーザがスタックを信頼していないことにあると示唆しています。 [ham83] 最初は値をスタックに残すことよりも、変数に値を格納することがより安全だと感じる事を、彼は認めています。「スタック上で転げ回っているすべてのことで何が起こるのかわからない」と彼は感じました。
「期待される入力と出力のためだけにスタックを使用し、自分自身が後でクリーンアップすることを、ワードそれ自身が正しく守れば、それらは封印されたシステムとみなすことができます…私はループの初めにスタックにカウントを置くことができます。各グループの為の完全なルーチンを実行させ、そしてそれが終わると、最後にスタックの先頭にはカウントがあります。髪の毛ほどもズレていません」彼がこれを理解するには少し時間がかかりました。
ローカル変数とグローバル変数と、その初期化¶
既に見たように、他のコードから隠された、単一の定義(または単一の用語集)内で排他的に使用される変数は、ローカル変数と呼ばれます。 複数の用語集で使用される変数は、グローバル変数と呼ばれます。 前章で見たように、いくつかの用語集間の共通のインターフェースをまとめて記述するグローバル変数のセットは「インターフェース用語集」と呼ばれます。
Forthはローカル変数とグローバル変数を区別しません。 しかしForthプログラマは区別します。
- ムーアは言います。
私たちは読者のために書くべきです。 ローカルでのみ参照される場合、合計を累積するための一時的な変数である場合は、ローカルで定義する必要があります。 それが使用されているブロック内でそれを定義するほうが便利で、あなたはそこにそれのコメントを見ることができます。
もしそれがグローバルに使われているのであれば、私達はそれらの論理的機能に従って物事を集め、そして別のスクリーン上でそれらを一緒に定義するべきです。 1行に1つ、コメント付きで。
問題は、どこでそれらを初期化するかです。その定義のすぐ後に、同じ行で、と言う人もいます。 しかし、それはコメントをめちゃめちゃにします、そしてまともなコメントの余地はありません。 そして、それはアプリケーション全体にわたって初期化を散乱させます。
私は、初期化はすべてロード・スクリーンで行います。 すべてのブロックをロードしたら、初期化する必要があるものを初期化します。 カラールックアップ表を設定したり、初期化コードを実行したりする可能性もあります。
あなたのプログラムがターゲットコンパイルされることになっているならば、すべての初期化を包含する場所にワードを書くのは簡単です。
もっと複雑になることがあります。 私は変数をROM内で定義しました。変数はすべてハイメモリの配列でオフになっていて、初期値はROM内にあります。初期値は初期化時にコピーします。 しかし、通常は、いくつかの変数をゼロ以外のものに初期化するだけです。
状態の保存と復元¶
変数には、内容を変更すると以前に存在していた値が上書きされるという特性があります。 これが引き起こす問題と、それらについて我々ができることのいくつかを見てみましょう。
BASE は全ての数値入出力に対する現在の基数を示す変数です。 以下のワードは、Forthシステムで一般的に見られます。
: DECIMAL 10 BASE ! ;
: HEX 16 BASE ! ;
メモリダンプを表示するワードを書いたとします。 通常、私たちは10進数モードで作業しますが、ダンプは16進数で行います。 だから私たちは以下ように書きます。
: DUMP ( a # )
HEX ... ( code for the dump) ... DECIMAL ;
ほとんどの場合、これは機能します。 しかし、それらは10進数モードに戻りたいだろうという推測に基づいています。 16進数で機能していて、16進数に戻りたい場合はどうなりますか? 基数を HEX に変更する前に、現在の値を保存する必要があります。 そしてダンプが完了したら復元します。
これは、ダンプをフォーマットしている間、保存した値を一時的に隠しておく必要があることを意味します。 リターンスタックはこれを行うための1つの場所です。
: DUMP ( a # )
BASE @ >R HEX ( code for dump) R> BASE ! ;
面倒になりすぎる場合は、一時変数を定義する必要があります。
VARIABLE OLD-BASE
: DUMP ( a # )
BASE @ OLD-BASE ! HEX ( code for dump )
OLD-BASE @ BASE ! ;
物事はすぐに複雑になります。
このような場合、現在のバージョンと古いバージョンの変数の両方が自分のアプリケーションだけに属していて(システムの一部ではない)、同じ状況が複数回発生する場合は、以下のようにファクタリング(要素分解)の手法を適用します。
: BURY ( a) DUP 2+ 2 CMOVE ;
: EXHUME ( a) DUP 2+ SWAP 2 CMOVE ;
それから CONDITION と OLD-CONDITION のように2つの変数を定義する代わりに、1つの2倍長変数を定義します。
2VARIABLE CONDITION
元の値を保存し復元するには、 BURY と EXHUME を使います。
: DIDDLE CONDITION BURY 17 CONDITION ! ( diddle )
CONDITION EXHUME ;
BURY は CONDITION 2 + で条件の「古い」バージョンを保存します。
あなたはまだ注意する必要があります。 私たちの DUMP の例に戻って、あなたが ESC キーを押すことによっていつでもユーザーにダンプを終了させるという親しみやすい機能を追加することに決めたとしましょう。 それでループの中であなたは押されたキーのテストを構築し、もしそうなら QUIT を実行します。 しかし、そうすると何が起こるでしょうか?
ユーザは基数10進数で始めてから DUMP とタイプします。 彼が途中で DUMP 終了させると、不思議なことに、基数は16進数になっているではありませんか。
当面の単純な場合、最善の解決策は QUIT ではなく、 定義の末尾の BASE のリセットを行う場所へ( LEAVE などを介して)、ループからの制御された終了を使って脱出する事です。
非常に複雑なアプリケーションでは、制御された出口は実際には実用的ではありませんが、それでも多くの変数を何らかの方法で自然な状態に復元する必要があります。
- ムーア はこの例に対して、以下のように言います。
あなたは自縄自縛に陥っています。あなたは自分自身のせいで問題を引き起こしています。 16進ダンプが欲しいのなら、私は
HEX DUMPと言います。 10進数のダンプが欲しいなら、DECIMAL DUMPと言います。 私はDUMPに自分の環境をいじり回す特権を与えません。あなたが終了したときに状況を回復することとあなたが開始したときに状況を確定することの間に哲学的な選択があります。 長い間、私はあなたが終わったときあなたが状況を回復するべきであると感じました。 そして私はそれをどこでも一貫してやろうとするでしょう。 しかし、「どこでも」を定義するのは困難です。 だから今、私は始める前に状態を確立する傾向があります。
私が、どこかにある物事を気にかけるワードがあるならば、私がその物事を設定するようにしたほうがよいでしょう。 そうすれば、他の誰かがそれらを変更しても、それらをリセットすることを心配する必要はありません。
入り口よりも多くの出口の方が多いのです。
やり直す前にリセットを実行する必要がある場合は、このリセットを実行するために1つのワード( PRISTINE と呼びます)があると便利です。 以下のようにして PRISTINE を起動します。
- アプリケーションの通常の出口で
- ユーザが意図的に終了する可能性がある場所(
QUITの直前) - 致命的なエラーが発生してアボートを引き起こす可能性がある場所で
最後に、値を保存または復元しなければならないというこのような状況に遭遇したときには、それが単なる悪い要素ではないことを確認してください。 たとえば、次のように書いたとします。
: LONG 18 #HOLES ! ;
: SHORT 9 #HOLES ! ;
: GAME #HOLES @ O DO I HOLE PLAY LOOP ;
現在の GAME は LONG か SHORT のどちらかです。
後になって、私たちは任意の数のホール(hole)をプレイするためのワードが必要だと決心しました。 そこで、 #HOLES の現在の値を上書きしないように GAME を起動します。
: HOLES ( n) #HOLES @ SWAP #HOLES ! GAME #HOLES ! ;
GAME を定義した後は HOLES が必要だったので、それはもっと複雑なように思えました。 私たちは GAME の周りに HOLES を作りました。 しかし、実際には、おそらくあなたはすでにそれを見ているはずですが、再考するのが正しいのです。
: HOLES ( n) O DO I HOLE PLAY LOOP ;
: GAME #HOLES @ HOLES ;
私たちは HOLES の周囲に GAME を構築し、このような保存/復元のナンセンスをすべて回避することができます。
アプリケーションスタック¶
前節では、単一の値を保存および復元する方法をいくつか検討しました。 一部のアプリケーションでは、複数値を保存および復元する必要があります。 自分のスタックを定義することで、この問題に対する最善の解決策が見つかることがよくあります。
以下は、非常に単純なエラーチェックを含むユーザスタックのコードです(エラー発生時はスタックをクリアする)。
CREATE STACK 12 ALLOT \ { 2tos-pointer | 10stack [5 cells] }
HERE CONSTANT STACK>
: INIT-STACK STACK STACK ! ; INIT-STACK
: ?BAD ( ?) IF ." STACK ERROR " INIT-STACK ABORT THEN ;
: PUSH ( n) 2 STACK +! STACK @ DUP STACK> = ?BAD ! ;
: POP ( -- n) STACK @ @ -2 STACK +! STACK @ STACK < ?BAD ;
PUSH というワード、データスタックから値を取り出し、それをこの新しいスタックに「プッシュ」します。 POP は反対で、新しいスタックから値をForthのデータスタックに「ポップ」します。
実際のアプリケーションでは、概念的な目的に合うように PUSH と POP の名前を変更することをお勧めします。
共有コンポーネント¶
ヒント
以下の条件であれば、意図した目的以外に追加の目的でコンポーネントを使用することは適正です。
- このコンポーネントの使用はすべて相互に排他的です。
- コンポーネントの使用を中断するたびに、コンポーネントは終了時の前の状態に復元されます。
それ以外の場合は、追加のコンポーネントまたは追加の複雑さのレベルが必要です。
私たちは前にリターンスタックを使ったこの原則の簡単な例を見ました。 リターンスタックは、リターンアドレスを保持するように設計されたForthシステムの構成要素であり、それによって、自分がどこにいて、どこに向かっているのかを示すものとして機能します。 戻り値のスタックを一時的な値を保持するものとして使用することは可能であり、多くの場合は望ましいことです。 但し、上記の制限の1つを無視すると問題が発生します。
私のテキストフォーマッタでは、出力は見えなくすることができます。 この機能には2つの目的があります。
- 何かが合うかどうかを見るために先を見越して、そして
- 目次をフォーマットするためのものです(実際には何も表示されずに文書全体がフォーマットされ、ページ番号が計算されます)。
出力を非表示にする機能を追加した後は、この機能を使用して両方の目的を果たすことができると思いがちでした。 残念ながら、この2つの目的は相互に排他的ではありません。
この規則に違反しようとするとどうなるか見てみましょう。 DISPLAY というワードが出力を行い、目に見えるか見えないかを判断するのには十分賢いです。 VISIBLE と INVISIBLE というワードはそれぞれ状態を設定します。
私の、先読みコードは、最初に INVISIBLE を実行し、次に来るテキストをテストフォーマットしてその長さを決定し、そして最後に VISIBLE を実行して通常の状態に戻します。
これはうまくいきます。
後で目次機能を追加します。 最初にコードは IN-VI-SI-BLE を実行し、それからページ番号などを決定するドキュメントを実行します。 それから、最後に VISIBLE を実行して物事を通常の状態に戻します。
落とし穴は?目次を実行していて、先を見越している場所の1つにヒットしたとします。 先を見終わったら、 VISIBLE を実行します。 目次を実行しようとしていたときに、突然文書の印刷を開始しました。
解決策は? いくつかあります。
1つの解決策は、先読みコードが、目録によって予め設定されている可能性がある可視/不可視フラグを潰していることが問題です。 したがって、先読みコードはフラグを保存し、後で復元する責任があります。
もう1つの解決策は、2つの別々の変数を保持することです。1つは先読みを示し、もう1つは目次を印刷していることを示します。 DISPLAY というワードは実際に何かを表示するために両方のフラグが偽であることを要求します。
あなたが問題をどのように分解したいかに応じて、後者のアプローチを達成するための2つの方法があります。 まず、以下のように、ある条件を別の条件の中に入れ子にすることができます。
: [DISPLAY] ...
( the original definition, always does the output) ... ;
VARIABLE 'LOOKAHEAD? ( t=looking-ahead)
: <DISPLAY> 'LOOKAHEAD? @ NOT IF [DISPLAY] THEN ;
VARIABLE 'TOC? ( t=setting-table-of-contents)
: DISPLAY 'TOC? @ NOT IF <DISPLAY> THEN ;
DISPLAY は、目次を設定していないことを確認してから、 <DISPLAY> を呼び出します。これにより、先読みしていないことが確認され、 [DISPLAY] が呼び出されます。
開発段階では、常に出力を行う [DISPLAY] というワードは、もともとは DISPLAY と呼ばれていました。 それから、先読みチェックを含むように新しい DISPLAY が定義され、元の定義は [DISPLAY] に改名されました。したがって、 DISPLAY を使用したコードを変更せずに後方レベルの複雑さを追加します。
最後に、目次機能が追加されたとき、目次チェックを含むように新しい DISPLAY が定義され、前の DISPLAY は <DISPLAY> に改名されました。
これは、2つの変数を使用するための1つの方法です。 もう1つの方法は、以下のように両方のテストを1つのワードに含めることです。
: DISPLAY 'LOOKAHEAD? @ 'TOC @ OR NOT IF [DISPLAY] THEN ;
しかし、この特定のケースでは、さらに別の方法で全体の混乱を単純化できます。 フラグとしてではなく、カウンターとして単一の変数を使用できます。
私たちは以下のように定義します。
VARIABLE 'INVISIBLE? ( t=invisible)
: DISPLAY 'INVISIBLE? @ O= IF [DISPLAY] THEN ;
: INVISIBLE 1 'INVISIBLE? +! ;
: VISIBLE -1 'INVISIBLE? +! ;
先読みコードは、カウンタを1つ上げた INVISIBLE を呼び出すことで始まります。 ゼロ以外は true なので、 DISPLAY は出力を行いません。 先読みの後、コードは VISIBLE を呼び出してカウンタをゼロ(false)に戻します。
目次コードも VISIBLE で始まり IN-VI-SI-BLE で終わります。 先読みしている間に目次を実行していると、2回目の VISIBLE の呼び出しでカウンタが2になります。
その後の INVISIBLE の呼び出しでカウンタが1つ減ります。まだ見えないので、目次が実行されるまで見えません。
( NOT= の代わりに 0= を代入しなければならないことに注意してください。FORTH-83規格では、 1の補数を意味するように NOTが変更されました。 私はこれは間違いだと思います。)
ただし、このカウンターの使用は危険な場合があります。 それはコマンド使用の同等性を必要とします。つまり、VISIBLE がカウンターを刻まない限り、2つの VISIBLE を隠してしまいます。
: VISIBLE 'INVISIBLE? @ 1- O MAX 'INVISIBLE? ! ;
状態表¶
単一の変数は、フラグ、値、または関数のアドレスのいずれかの単一の条件を表すことができます。
条件の集まりは、アプリケーションまたは特定のコンポーネントの状態を表します。 [slater83] 一部のアプリケーションでは、現在の状態を保存してから後で復元する機能、または複数の状態を交互に表示する機能が必要になります。
ヒント
アプリケーションが条件のグループを同時に処理する必要がある場合は、変数を分離せずに状態表を使用してください。
単純な場合としては、状態を保存して復元する必要があります。 リスト 11 に示すように、最初に特定のコンポーネントの状態を表す6つの変数があるとします。
VARIABLE TOP
VARIABLE BOTTOM
VARIABLE LEFT
VARIABLE RIGHT
VARIABLE INSIDE
VARIABLE OUT
ここで、それらすべてを保存する必要があるとします。保存後、さらに何かしら処理が行われ、後でそれらすべてが復元されます。 以下のように定義できます。
: @STATE ( -- top bottom left right inside out)
TOP @ BOTTOM @ LEFT @ RIGHT @ INSIDE @ OUT @ ;
: !STATE ( top bottom left right inside out -- )
OUT ! INSIDE ! RIGHT ! LEFT ! BOTTOM ! TOP ! ;
それにより、それらが復元される時までスタック上のすべての値を保存します。 または、上記の各変数に対して、各値を個別に保存するための代替変数を定義することもできます。
しかし、推奨される手法では、表の各要素を名前で参照して表を作成します。 次に、同じ長さの2番目の表を作成します。 図 54 に見られるように、 POINTERS と呼ばれる表を SAVED と呼ばれる2番目の表にコピーすることで状態を保存することができます。
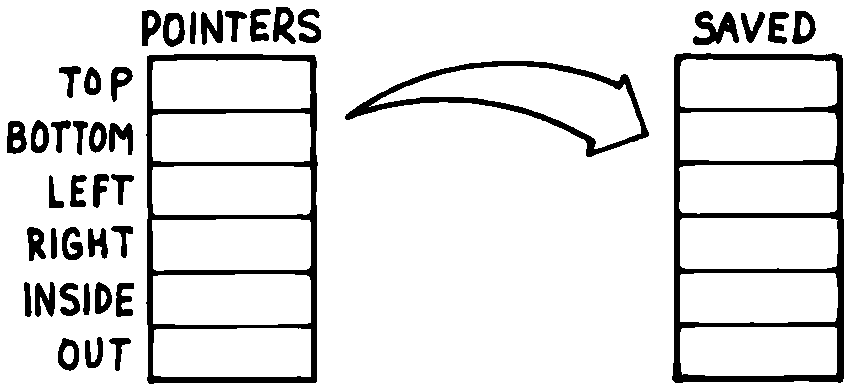
図 54 状態表を保存するための概念モデル。
このアプローチは リスト 12 のコードで実装しました。
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | 0 CONSTANT POINTERS \ address of state table PATCHED LATER
: POSITION ( o -- o+2 ) CREATE DUP , 2+
DOES> ( -- a ) @ POINTERS + ;
0 \ initial offset
POSITION TOP
POSITION BOTTOM
POSITION LEFT
POSITION RIGHT
POSITION INSIDE
POSITION OUT
CONSTANT /POINTERS \ final computed offset
HERE ' POINTERS >BODY ! /POINTERS ALLOT \ real table
CREATE SAVED /POINTERS ALLOT \ saving place
: SAVE POINTERS SAVED /POINTERS CMOVE ;
: RESTORE SAVED POINTERS /POINTERS CMOVE ;
|
この実装では、ポインタの名前、 TOP 、 BOTTOM などは常に同じアドレスを返すことに注意してください。 状態の現在値を表すために使用される場所はいつでも1つだけです。
また、 CREATE ではなく CONSTANT でダミーのゼロを使って POINTERS (表の名前)を定義していることにも注意してください。 これは、定義ワード POSITION で POINTERS を参照しているためですが、すべてのフィールド名を定義した後で初めて、表がどれだけの大きさでなければならないかを知ることができます。
私たちはフィールド名を作成したらすぐに、表のサイズを定数 /POINTERS として定義します。 私たちは終に表自身のためのスペースを確保したので、その先頭アドレス( HERE )を定数 POINTERS にパッチします( >BODY というワードは、ティック( ' )によって返されたアドレスを定数の値のアドレスに変換します)。したがって POINTERS は、 CREATE で定義された名前のように、後で割り当てられた表のアドレスを返します。 名前のヘッダーのすぐ下に割り当てられている表のアドレスを返します。
ここで行っているように、コンパイル時に CONSTANT の値にパッチを当てることは有効ですが、スタイルの制限があります。
ヒント
アプリケーションがコンパイルされたら、 CONSTANT の値を変更しないでください。
交互の状態の場合はもう少し複雑です。 このような状況では、2つ(またはそれ以上)の状態を交互に切り替える必要があります。他の状態にジャンプしたときに、各状態の条件を変更することは決してありません。 図 55 はこの種の状態表の概念モデルを示しています。
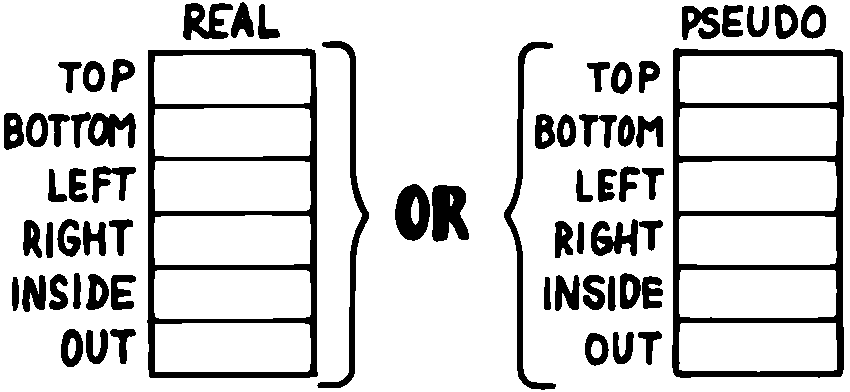
図 55 交互状態表の概念モデル
このモデルでは、 TOP 、 BOTTOM などの名前を、 REAL または PSEUDO の2つの表のいずれかを指すようにすることができます。 REAL 表を現在の表にすることで、すべてのポインタ名は REAL 表のアドレスを参照します。 PSEUDO 表を最新にすることで、 PSEUDO 表をアドレス指定します。
リスト 13 のコードはこの交互状態メカニズムを実装しています。 WORKING と PRETENDING というワードはポインタを適切に変更します。例えば以下の通り。
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | VARIABLE 'POINTERS \ pointer to state table
: POINTERS ( -- adr of current table) 'POINTERS @ ;
: POSITION ( o -- o+2 ) CREATE DUP , 2+
DOES> ( -- a ) @ POINTERS + ;
0 \ initial offset
POSITION TOP
POSITION BOTTOM
POSITION LEFT
POSITION RIGHT
POSITION INSIDE
POSITION OUT
CONSTANT /POINTERS \ final computed offset
CREATE REAL /POINTERS ALLOT \ real state table
CREATE PSEUDO /POINTERS ALLOT \ temporary state table
: WORKING REAL 'POINTERS ! ; WORKING
: PRETENDING PSEUDO 'POINTERS ! ;
|
WORKING
10 TOP !
TOP ? 10
PRETENDING
20 TOP !
TOP ? 20
WORKING
TOP ? 10
PRETENDING
TOP ? 20
後者のアプローチとの大きな違いは、名前が余分なレベルの間接参照を通過することです( POINTERS は定数からコロン定義に変更されました)。 フィールド名は、2つの状態表のいずれかを指すようにすることができます。 したがって、それぞれの名前にはもう少し作業が必要です。 また、前者のアプローチでは、名前は固定位置を指します。 値を保存または復元するたびに CMOVE が必要です。このアプローチでは、現在の表を変更するために1つのポインタを変更するだけです。
ベクトル化実行¶
ベクトル化実行は、データを超えた直接性と間接性の概念を機能にまで拡張します。 値やフラグを変数に保存できるのと同じように、機能はアドレスで参照できるため、機能を保存することもできます。
ベクトル化された実行を実装するための伝統的なテクニックは Starting Forth,Chapter Nine(邦訳:FORTH入門 第9章)で説明されています。 この節は、私が開発した新しい構文について説明します。これは、従来の方法よりもエレガントにさまざまな状況で使用できると思います。
その構文は DOER/MAKE と呼ばれます(システムにこれらのワードが含まれていない場合、コードと実装の詳細については 付録B 参照)。それは以下のように、動作をベクトル化可能なワード DOER で定義できます。
DOER PLATFORM
最初は、 PLATFORM という新しいワードは何もしません。 その後、 MAKE というワードを使って、 PLATFORM の動作を変更するワードを書くことができます。
: LEFTWING MAKE PLATFORM ." proponent " ;
: RIGHTWING MAKE PLATFORM ." opponent " ;
LEFTWING を起動すると、 MAKE PLATFORM というフレーズは PLATFORM の動作を変更します。 PLATFORM と入力すると、次のようになります。
LEFTWING ok
PLATFORM proponent ok
RIGHTWING は PLATFORM に「opponent.」を表示させます。他の定義の中で PLATFORM を使うことができます。
: SLOGAN ." Our candidate is a longstanding " PLATFORM
." of heavy taxation for business. " ;
その声明
LEFTWING SLOGAN
キャンペーン声明を1つ表示します。
RIGHTWING SLOGAN
もう一方の表示。
MAKE コードは、任意のForthコードで、あなたが望むだけの長さで書くことが出来ます。但しそれをセミコロンで終わらせることを忘れないでください。 LEFTWING の末尾のセミコロンは、 LEFTWING と、 MAKE の後のコードの、両方に使用されます。 MAKE が DOER ワードの実行をリダイレクトすると、それを記述したワードの実行も「停止」します。
たとえば、LEFTWING を起動すると、MAKE は PLATFORM をリダイレクトして終了します。 LEFTWING を起動しても「proponent」は表示されません。 図 56 は辞書の概念図を使ってこの点を説明しています。
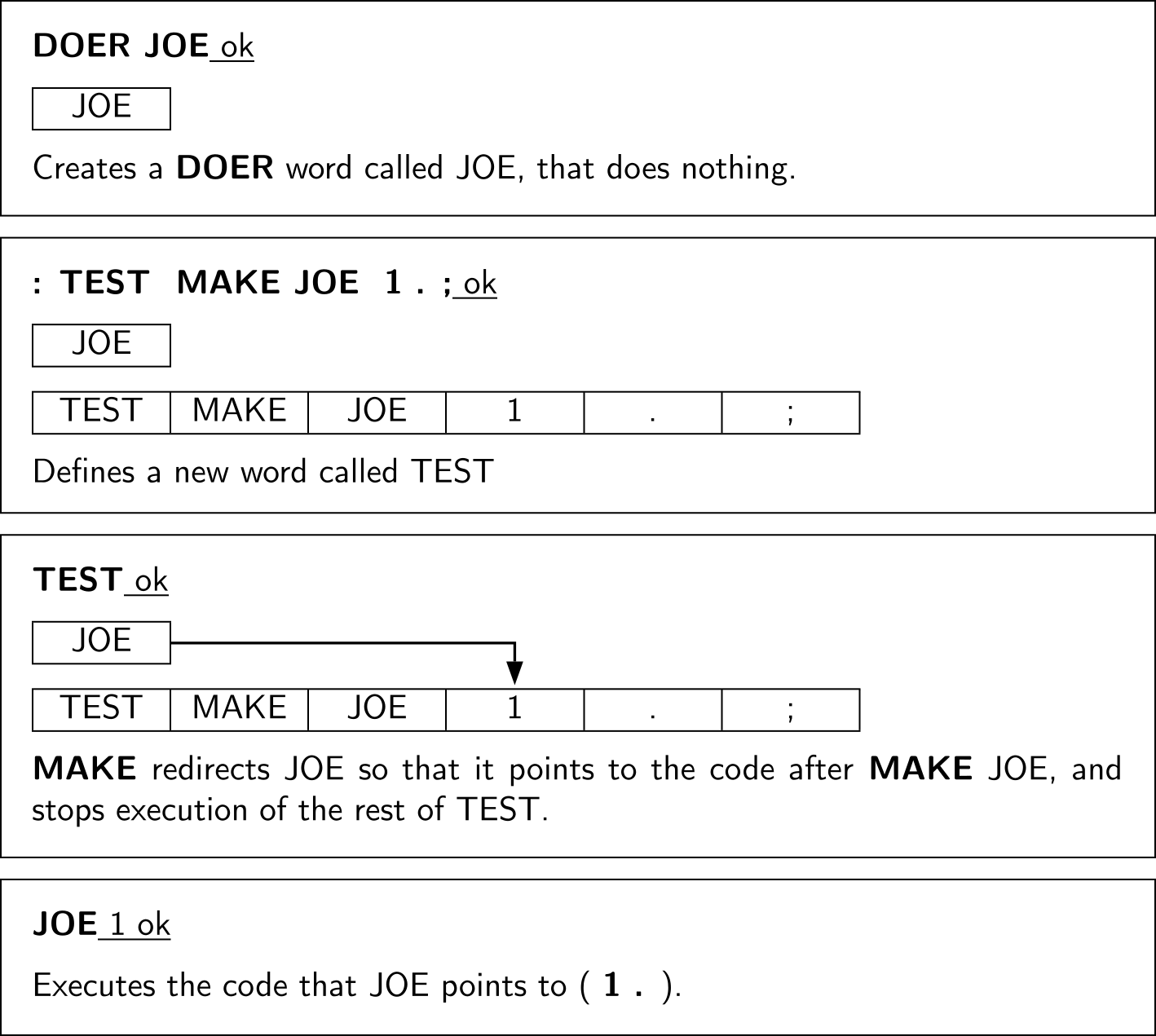
図 56 DOER と MAKE
実行を継続したい場合は、セミコロンの代わりにワード ;AND を使用できます。 ;AND は 図 57 にあるように、 DOER ワードが指すコードを終了させ、それが現れる定義の実行を再開します。

図 57 ;AND を使って複数の MAKE を並列に実行
最後に、 ;AND を使わないことで、 DOER のワードの「メイキング」を連鎖させることができます。 図 58 は、私が説明を書くよりもよりも上手く図示示しています。

図 58 複数の MAKE の連なり
DOER/MAKEの使用¶
DOER/MAKE 組み立てが有益であることが証明される機会はたくさんあります。
機能の状態を変更する(状態の外部テストが不要な場合)。
LEFTWINGとRIGHTWINGというワードは、PLATFORMというワードの状態を変更します。内部フレーズを類似の定義から括り出します。しかし、それはループなどの制御構造の中に入っています。
指定されたメモリ領域の内容を表示するように設計された
DUMPと呼ばれるワードの定義を考えてください。0 1 2 3 4
: DUMP ( a # ) O DO I 16 MOD O= IF CR DUP I + 5 U.R 2 SPACES THEN DUP I + @ 6 U.R 2 +LOOP DROP ;
この問題は、セルではなくバイト数に従って出力をフォーマットするように設計された
CDUMPと呼ばれる定義を書くときに起こります。0 1 2 3 4
: CDUMP ( a # ) O DO I 16 MOD O= IF CR DUP I + 5 U.R 2 SPACES THEN DUP I + C@ 4 U.R LOOP DROP ;
これら2つの定義内のコードは、3行目を除いて同一です。 しかし、ここは
DO…LOOPの内部にあるため、ファクタリング(要素分解)は困難です。以下はこの問題に対する解決策です。
DOER/MAKEを使ってください。 変更されたコードはワード.UNITに置き換えられました。その動作はDUMPとCDUMPのコードによって管理されています(1 +LOOPはLOOPと同じ効果があります)。DOER .UNIT ( a -- increment) \ display byte or cell : <DUMP> ( a # ) O DO I 16 MOD O= IF CR DUP I + 5 U.R 2 SPACES THEN DUP I + .UNIT +LOOP DROP ; : DUMP ( a #) MAKE .UNIT @ 6 U.R 2 ;AND <DUMP> ; : CDUMP ( a #) MAKE .UNIT C@ 4 U.R 1 ;AND <DUMP> ;
DUMPとCDUMPがベクトルを設定します。それから、実行シェル(ワード<DUMP>)へ進みます。単一のコマンドを呼び出して関連機能の状態を変更すること。 たとえば以下のように。
0 1 2 3 4 5 6 7 8 9 10 11
DOER TYPE' DOER EMIT' DOER SPACES' DOER CR' : VISIBLE MAKE TYPE' TYPE ;AND MAKE EMIT' EMIT ;AND MAKE SPACES' SPACES ;AND MAKE CR' CR ; : INVISIBLE MAKE TYPE' 2DROP ;AND MAKE EMIT' DROP ;AND MAKE SPACES' DROP ;AND MAKE CR' ;
ここでは、各ワードの末尾に「プライム(
')」マークが付いた、わかりやすい一連の出力ワードを定義しました。VISIBLEはそれらのワードを名前から期待される機能に設定します。INVISIBLEはそれらを「何もしない(no-op)」ワードに設定し、通常それらのワードに渡される引数を単に食い尽くします。よって「INVISIBLE」と言うと、これら4つの出力操作ワードに対して定義されたワードは出力を生成しません。次回の発生時のみ状態を変更するには、再度状態を変更(またはリセット)します。
アドベンチャーゲームを書いているとしましょう。 プレイヤーが最初に特定の部屋に到着すると、ゲームは詳細な説明を表示します。 後でプレイヤーが同じ部屋に戻った場合、ゲームは短いメッセージを表示します。
私たちは以下のように書きます。
DOER ANNOUNCE : LONG MAKE ANNOUNCE CR ." You're in a large hall with a huge throne" CR ." covered with a red velvet canopy." MAKE ANNOUNCE CR ." You're in the throne room." ;
ワード
ANNOUNCEはいずれかのメッセージを表示します。最初に私たちは長いメッセージでANNOUNCEを初期化するためにLONGと言います。今や私たちはANNOUNCEをテストする事ができ、それは長いメッセージを表示します。その後、続けて、短いメッセージを表示する処理でANNOUNCEを書き換えます。私たちがもう一度
ANNOUNCEをテストすると、短いメッセージが表示されます。 そしてLONGと再び言うまでは、それは短いメッセージの表示のままです。事実上、私たちは行動を待ち行列に入れています。 各動作に次の動作を設定させて、動作をいくつでもキューに入れることができます。 次の例は(あんまり実用的ではありませんが)この動作を表しています。
0 1 2 3 4 5 6 7 8 9 10 11 12 13
DOER WHERE VARIABLE SHIRT VARIABLE PANTS VARIABLE DRESSER VARIABLE CAR : ORDER \ specify search order MAKE WHERE SHIRT MAKE WHERE PANTS MAKE WHERE DRESSER MAKE WHERE CAR MAKE WHERE O ; : HUNT ( -- a|O ) \ find location containing 17 ORDER 5 O DO WHERE DUP O= OVER @ 17 = OR IF LEAVE ELSE DROP THEN LOOP ;
このコードでは変数のリストを作成し、それからそれらが検索されることになる
ORDERを定義しました。 ワードHUNTはそれぞれを見て、17を含む最初のものを探します。HUNTは正しい変数のアドレスを返します。値がない場合はゼロを返します。これは単に
WHEREを5回実行することによって行われます。 毎回、WHEREはORDERで定義されているように異なるアドレスを返し、最後にゼロを返します。それ自身の振る舞いを際限なくON/OFFする
DOERというワードを定義することさえできます。DOER SPEECH : ALTERNATE BEGIN MAKE SPEECH ." HELLO " MAKE SPEECH ." GOODBYE " O UNTIL ;
前方参照を実装します。 通常、前方参照は「フック(hook)」、つまり低レベルの定義で呼び出され、リストの後半で定義されているコンポーネントで使用するために予約されているワードとして必要です。
前方参照を実装するには、その名前を呼び出す前に、ワードのヘッダを
DOERで構築します。DOER STILL-UNDEFINED
リストの後半で
MAKEを使います。MAKE STILL-UNDEFINED ALL THAT JAZZ ;
(覚えておいてください、
MAKEはコロン定義の外で使うことができます。)直接的または間接的な再帰
ワードが自分自身を呼び出すときに直接再帰が発生します。 良い例は、以下のような最大公約数用の再帰定義です。
GCD of a, b = a if b = O GCD of b, a mod b if b > Oこれは以下のように素敵に変換できます。
DOER GCD ( a b -- gcd) MAKE GCD ?DUP IF DUP ROT ROT MOD GCD THEN ;
間接再帰は、あるワードが別のワードを呼び出すときに発生し、2番目のワードが最初のワードを呼び出すときに発生します。 これは以下の形式で行えます。
DOER B : A ... B ... ; MAKE B ... A ... ;
デバッグの為に、私はしばしば以下の定義をします。
DOER SNAP
(
SNAPSHOTの略)それから、何が起こっているのか見たいところでSNAPを私のアプリケーションに編集してください。 たとえば、キーストロークインタプリタのメインループ内でSNAPを呼び出すと、キーを入力したときにデータ構造に何が起きているのかを確認できるように設定できます。 そして、ループを再コンパイルしなくても、SNAPの動作を変更できます。
tick-and-executeアプローチを使用するのが望ましい状況は、決定表の要素を介してベクトル化するとき、またはその内容を保存/復元しようとするときなど、ベクトルのアドレスを制御する必要がある場合です。
要約¶
この章では、スタックを使用することと、変数や他のデータ構造を使用することとの間のトレードオフを調べました。 テストと再利用のためにはスタックを使用することをお勧めしますが、単一の定義によってスタック上で操作される値が多すぎると、読みやすさと書きやすさが低下します。
また、データ構造を保存したり復元したりするためのテクニックも調べ、 DOER/MAKE を使ったベクトル実行の研究で締めくくりました。
参考文献¶
| [ham83] | Michael Ham, "Why Novices Use So Many Variables," Forth Dimensions , vol. 5, no. 4, November/December 1983. |
| [slater83] | Daniel Slater, "A State Space Approach to Robotics," The Journal of Forth Application and Research , 1, 1 (September 1983), 17. |