第3章 予備設計・分解¶
あなたが、自分のプログラムで何を達成すべきかについて何らかの考えを持っていると仮定して、設計を始める時が来ました。最初の段階である予備設計では、山のようにそびえ立つ問題をモグラ塚に縮小する事に焦点を当てます。
この章では、Forthアプリケーションを分解する2つの方法について説明します。
コンポーネントによる分解¶
あなたはこのような経験がないでしょうか? あなたはある週末に登山するために3ヶ月前から計画を練っていました。あなたは何を持っていくべきかのリストを作り、そして山肌について空想しています。
その合間に、あなたは来週の土曜日、いとこの結婚式に何を着ていくかを決めます。彼らは形式ばらないタイプなので、あなたはあまり着飾りたくはありません。しかし、結婚式は結婚式です。たぶんあなたはとにかくタキシードを借りるべきです。
これら全ての計画において、あなたは木曜日になるまで2つのイベントが同時に起こる事に気付きませんでした。誰しもそんな事があります。
私は賢いはずなのに、どうしてうっかりなんかしちゃうんだろう? どうやら人間の心は記憶と記憶の間に繋がりを作ります。関連する考えの経路に、新しい考えがなぜか追加されています。
図 29 まだ繋がってない記憶のプール
今述べた災難では、木曜日になるまで2つの記憶プールの間に繋がりができることはありませんでした。(土曜日の天気予報を聞くようなちょっとしたことで)幾つかの新しい入力が2つの思考プールをつなげた時、おそらく矛盾に気付くのです。理解のひらめきが記憶プール間で起こり、そして容赦ないパニックがそれに続きます。
そのような災害を回避するためのシンプルなツールが発明されました。 カレンダーと呼ばれています。 両方の計画を同じカレンダーに記録する場合、もう一方のイベントがスケジュールされているのが分かります。これはあなたの脳の、その複雑な素晴らしさゆえに出来なかった事です。
ヒント
二つの事の関係を調べるためには、それらを近づけてください。 関係を思い出させるために、それらを 一緒 に保持します。
これらわかりきったことはソフトウェア設計、特に予備設計段階に当てはまります。 このフェイズでは伝統的に、設計者が大規模なアプリケーションを、より小さなプログラマサイズのモジュールに分割します。
第1章 で、私たちはアプリケーションが都合よくコンポーネントに分解できる事を発見しました。
ヒント
予備設計の目的は、要件を満たすためにどのコンポーネントが必要かを決定することです。
たとえば、あらかじめ決められたスケジュールに従ってイベントを発生させる必要があるアプリケーションがあるとします。 スケジュールを管理するには、最初に「スケジュール作成用の用語集」を構成するためのいくつかのワードを設計します。これらのワードを使用して、アプリケーション内で発生するイベントの順序を記述できます。
こうすれば単一のコンポーネント内で、情報を共有するだけでなく、潜在的な競合を解決することもできます。 間違った方法とは、各機能モジュールがそのスケジュールについて、他のモジュールのスケジュールと衝突する可能性があることを「知っている」ことです。
コンポーネントを設計する際に、使用するコンポーネントに必要なコマンドはどのようして知るのでしょうか?確かに、これは「鶏が先か、卵が先か」問題のようなものです。 しかし、Forthプログラマーは、鶏や卵と同じ方法でそれを処理しています。
コンポーネントが適切に設計されていれば、完全性は重要ではありません。 実際、コンポーネントは現在の反復回の設計に十分であれば十分です。 維持管理中のアプリケーションと異なり、そのアプリケーションが完成するまでは、どのコンポーネントも「決定済の事項」と見なすべきではありません。
例として、あなたの製品がシステムの一部である汎用I/Oチップを介して他のマシンと「話す」必要があると想像してください。この特定のチップは「制御レジスタ」と「データレジスタ」を持っています。良くない設計のアプリケーションでは、プログラム全体に散りばめられたコード片が、単純にOUT命令を呼び出して適当なコマンドバイトをコマンドレジスタに入れるだけでその通信チップに通信チップにアクセスします。これはアプリケーション全体を特定のチップに不必要に依存させることになります。非常に危険です。
代わりに、ForthプログラマはI/Oチップを制御するためのコンポーネントを書くでしょう。 これらのコマンドには、論理名と便利なインタフェース(通常はForthのスタック)があり、残りのアプリケーションで使用することができます。
製品の設計を何度も繰り返す場合は、その時点までに必要なコマンドだけを実装します。「制御レジスタ」にセットできる有効なコードをすべて実装したりはしません。プロジェクトサイクルの後半で追加のコマンドが必要になり、それがボーレートを変更するためのものであれば、新しいコマンドはボーレートの設定に必要なコードではなく、I/Oチップの用語集に追加します。 この変更を行っても、編集や再コンパイルにかかる時間が最大数分掛かることを除けば、ペナルティはありません。
ヒント
各コンポーネント内で、現在の反復回に必要なコマンドだけを実装します(しかし、将来の追加を妨げないようにしてください)。
コンポーネントの内部で起きることは、ほとんどそれ自身のための仕事です。 コンポーネント内の定義が冗長な情報を共有するのは必ずしも悪いスタイルではありません。
たとえば、あるデータ構造のレコードは14バイトの長さです。 コンポーネント内のある定義では、次のレコードを指すためにポインタを14バイト分進めます。 別の定義では、ポインタを14バイト分減算します。
その数字14はコンポーネントの「秘密」であり、他の場所から利用されない限り、定数として定義する必要はありません。 両方の定義に14という数字を使用するだけです。
: +RECORD 14 RECORD# +! ;
: -RECORD -14 RECORD# +! ;
一方、コンポーネントの外部で値が必要になる場合、またはコンポーネント内で値が複数回使用されていて値が変更される可能性が高い場合は、それを名前の下に隠すことをお勧めします。
14 CONSTANT /RECORD
: +RECORD /RECORD RECORD# +! ;
: -RECORD /RECORD NEGATE RECORD# +! ;
(Forthの慣習的に /RECORD と言う名前は、「レコード当たりのバイト(bytes per record)」を意味します。)
例:タイニー・エディタ¶
実際の問題にコンポーネントによる分解を適用しましょう。 本章 で大規模なアプリケーションを設計するのは素敵です。しかし、残念なことに、私たちは開発チームを持っていないし、アプリケーションを理解しようとして横道にそれてしまいます。
代わりに、すでに分解されている大規模アプリケーションからコンポーネントを取り出します。 このコンポーネントをさらに分解してサブコンポーネントにすることで、このコンポーネントを設計します。
ユーザが端末画面の入力フィールドの内容を変更できるようにするタイニーエディタを作成する必要があるとします。 たとえば、画面は次のようになります。

エディタは、ユーザが入力フィールドの内容を変更するための3つのモードを提供します。
- 上書き
- 通常の文字をタイプすると、そこにある文字は全て上書きされます。
- 削除
- 組み合わせキー CTRL D を押すと、カーソル位置の1文字を削除し、その後ろの文字列が1文字左にスライドします。
- 挿入
- 組み合わせキー CTRL I を押すと、エディタは「挿入モード」に切り替わり、通常の文字を入力すると、カーソル位置に挿入し、カーソル位置にあった1文字とそれ以降の文字列は右にスライドします。
概念モデルの一部として、エラーまたは例外処理も考慮する必要があります。 例えば、フィールドは何文字まで入力できますか? 挿入モードで文字が右にあふれたときに何が起こりますか?などです。
これが今現在、私たちの手元にあるすべての仕様です。 残りは私たち次第です。
どのコンポーネントが必要かを決定してみましょう。まず、エディタはキーボードで入力されたキーに反応します。したがって、私たちにはキーストロークインタプリタが必要です。それはキーストロークを待ち受け、それらを可能な操作のリストと照合する、ある種のルーチンです。キーストロークインタプリタは1つのコンポーネントであり、その用語集は単一のワードで構成されます。 そのワードはフィールドの編集を許可するので、 EDIT というワードを呼び出すことになるしょう。
キーストロークインタプリタによって呼び出された操作は、2番目の用語集を構成します。 この用語集の定義は、必要なさまざまな機能を実行します。 DELETE 、 INSERT 、等と呼ばれるかもしれません。これらのコマンドはそれぞれキーストロークインタプリタによって呼び出されるので、それぞれが単一のキーストロークを処理します。
これらのコマンドの下には、3番目のコンポーネント、編集するデータ構造を実装する一連のワードがあります。
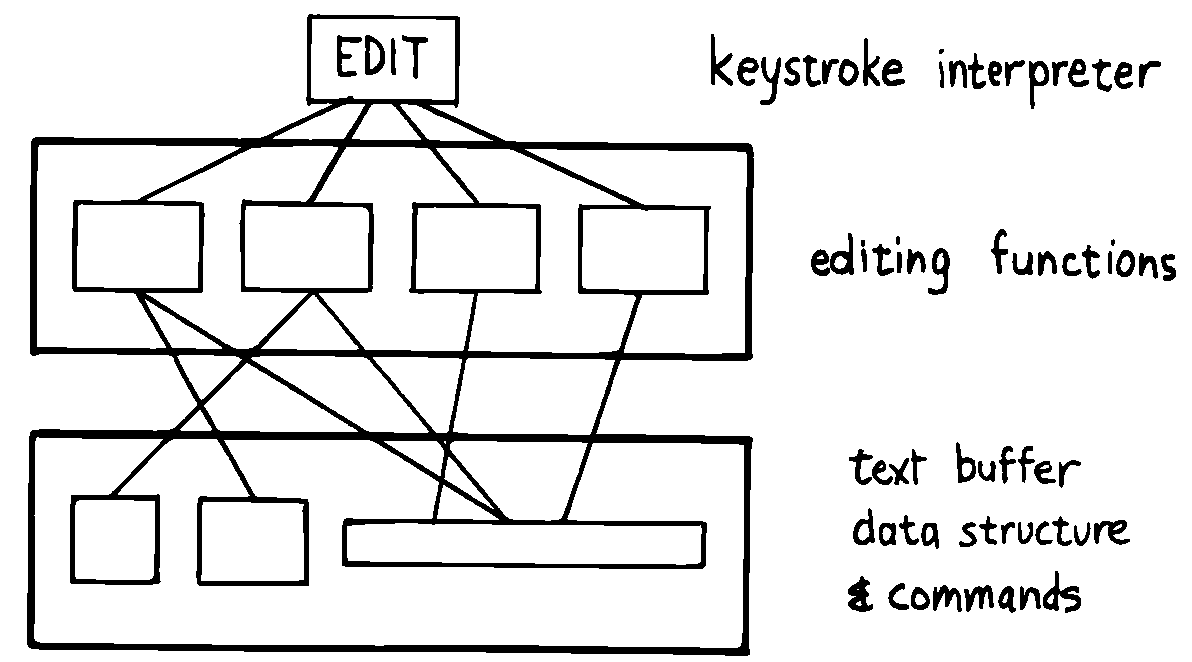
図 30 タイニーエディタ問題の一般化された分解
最後に、ビデオ画面にフィールドを表示するためのコンポーネントが必要です。 簡単にするために、各キーが押された後にフィールド全体を再表示するために、1つのワード REDISPLAY のみを作成することを計画しましょう。
: EDITOR BEGIN KEY REVISE REDISPLAY ... UNTIL ;
このアプローチはバッファの修正と表示の更新を分離します。 今のところ、バッファの修正に集中するだけです。
各コンポーネントを個別に見て、それぞれが必要とするワードを判断してみましょう。 まず、上書き、削除、挿入という3つの最も重要な編集機能内で発生しなければならないイベントについて検討します。 私たちは、チラシの裏に次のようなものを描くかもしれません(この議論では例外処理にあまり注意を払いません)。
- 上書き処理
- 1文字をポインタの示すバイト位置に格納。
- (フィールドの末尾以外なら)ポインタを1つ進める。

- 削除処理
- ポインタの1つ右から始まる文字列を1桁左にコピー。
- その行の末尾に「空白」を格納。

- 挿入処理
- ポインタ位置からの文字列を1桁右にコピー。
- ポインタの示すバイト位置に新しい1文字を格納
- (フィールドの末尾以外なら)ポインタを1つ進める。

この問題の為のアルゴリズムは丁度いま手元で開発中です。
次のステップでは、これら3つの重要な処理を調べて、便利な「名前」を探します。それは手順または要素のいずれかで、以下のいずれかを実行できるものです。
- 再利用可能か、または、
- 変更可能なもの
私たちは、3つの処理全てが「ポインタ」と呼ばれるものを使用していること発見しました。私たちには以下の2つの処理が必要です。
- ポインタを取得する(ポインタが相対位置指定の場合は、この機能は何らかの計算を実行します)。
- ポインタを進める
ちょっと待った!3つめの処理が必要です。
- ポインタを後ろに動かす
なぜなら私たちは編集せずに「カーソルキー」でカーソルを前後に移動させたいからです。
これら3つの操作はすべて、メモリ内のどこかにある物理ポインタを参照します。それが保持される場所と、それがどのように(相対値または絶対値)格納されるかはコンポーネント内に隠されるべきです。
これらのアルゴリズムをコードに書き換えてみましょう。
: KEY# ( returns value of key last pressed ) ... ;
: POSITION ( returns address of character pointed-to) ;
: FORWARD ( advance pointer, stopping at last position) ;
: BACKWARD ( decrement pointer, stopping at first position) ;
: OVERWRITE KEY# POSITION C! FORWARD ;
: INSERT SLIDE> OVERWRITE ;
: DELETE SLIDE< BLANK-END ;
テキストを左側方向に、あるいは右側方向にコピーするためには、私たちは2つの新しい名前 SLIDE< と SLIDE> (それぞれ「slide-backwards」、「slide-forwards」と発音します)をペアで考え出す必要がありました。それらの両方とも POSITION を使用します。しかし、それらは私たちが考慮するのを延期した要素に依存します。それはフィールドの長さを「知る」方法です。3番目のコンポーネントを書くことになったら、その側面に取り組むことができます。しかし、すでに判った事もあります。「挿入」は単に SLIDE> OVERWRITE と記述することができます。
言い換えれば、 「挿入」は、(少なくとも構造化プログラマにとっては)同じレベルに存在しているように見えても、実際には「上書き」を使用します。
3番目の要素について詳しく調べるのではなく、最初の要素、つまりキーインタプリタについて知っていることを設計しましょう。 まず、「挿入モード」の問題を解決しなければなりません。「挿入」は、削除のように特定のキーを押したときに発生するものではないことが判明します。代わりに、それは、可能なキーストロークのいくつかを 異なる方法で解釈すること です。
たとえば「上書き」モードでは、通常の文字が現在のカーソル位置に格納されます。 しかし「挿入モード」では、行の残りの部分を最初に右にシフトする必要があります。 また、バックスペースキーは、エディタが挿入モードのときにも動作が異なります。
「挿入」と「非挿入」の2つのモードがあるため、キーストロークインタプリタはキーを2つの可能な名前付き手続きセットに関連付ける必要があります。
キーストロークインタプリタを以下のように決定表として書くことができます(実装については後で考えますします)。
| Key | Not-inserting | Inserting |
|---|---|---|
| Ctrl-D | DELETE | INSERT-OFF |
| Ctrl-I | INSERT-ON | INSERT-OFF |
| backspace | BACKWARD | INSERT< |
| left-arrow | BACKWARD | INSERT-OFF |
| right-arrow | FORWARD | INSERT-OFF |
| return | ESCAPE | INSERT-OFF |
| any printable | OVERWRITE | INSERT |
決定表では、可能な種類のキーを左側の列に配置し、それらが通常行う操作を中央の列に配置し、「挿入モード」で行う操作を右側の列に配置します。
挿入モードで「backspace」が押されたときに何が起こるかを実装するために、私たちは新しい手順を追加します。
: INSERT< BACKWARD SLIDE< ;
(カーソルを後方に移動して最後に入力した文字の上に配置してから、すべてを左にスライドさせて間違いを隠します)。
この表は現在のレベルでの問題の最も論理的な表現のように見えます。 後で実装します( 第8章 )。
それでは、保守性の観点から、このアプローチの大きな価値を実証します。 私たちは我々自身に変化球を投げます。それは計画の大幅な変更です!
コンポーネントベース・アプリケーションの保守¶
私たちの設計は変化に直面した時、どれだけうまくいくでしょうか。 以下のシナリオを想定します。
キーを押すたびにフィールドを再入力するだけでビデオ表示を更新できると当初は考えていました。 スキャンサイクルの間に1行全体を更新する、メモリマップされたビデオを使用して、コードをパーソナルコンピュータに実装することもできました。 しかし今、私たちの顧客は、すべてのI/Oがそれほど速くないボーレートで行われる、電話ベースのネットワーク上でアプリケーションを実行することを望んでいます。 一部の入力フィールドはビデオ画面とほぼ同じ幅、おそらく65文字なので、すべてのキーストロークで行全体を更新するには時間がかかりすぎます。
実際に変化するフィールドの部分だけを更新するように、アプリケーションを変更する必要があります。 「挿入」および「削除」では、これはカーソルの右側のテキストを意味します。 「上書き」では、上書きされる1文字だけを変更することを意味します。
この変更は重要です。 私たちが横柄にキーインタプリタに任せたビデオ更新機能は、今や、どの編集機能が行われるかに依存しなければなりません。 私たちが発見した、キーインタプリタを実装するために必要な最も重要な名前は以下のとおりです。
FORWARD
BACKWARD
OVERWRITE
INSERT
DELETE
INSERT<
これらの説明では、ビデオ更新プロセスについて言及していません。これはもともとこれらの後で起こると想定されていたためです。
しかし、物事は見かけほど悪くはありません。 今見てみると、OVERWRITE 処理は端末のカーソルがあるところに新しい文字をタイプするコマンドを簡単に含めることができます。 そして SLIDE< と SLIDE> は POSITION の右側に全てをタイプするコマンドを含めることができ、それから端末のカーソルを現在の位置にリセットします。
以下が、私たちが改訂した手続き名です。 追加したコマンドは、OVERWRITE の定義の KEY# EMIT の部分と、 RETYPE の定義および、 INSERT 、 DELETE での使用です。
: OVERWRITE KEY# POSITION C! KEY# EMIT FORWARD ;
: RETYPE ( type from current position to
end of field and reset cursor) ;
: INSERT SLIDE> RETYPE OVERWRITE ;
: DELETE SLIDE< BLANK-END RETYPE ;
これらはメモリを変更する唯一の3つの機能なので、画面を更新する必要があるのはこれら3つの機能だけです。 この考えは重要です。 私たちはプログラムの正当性を保証するためにそのような主張をすることができなければなりません。 この主張は問題の本質に内在するものです。
画面リフレッシュの、この追加の問題には「追加のポインタ」が要るとに注意してください。それは現在の画面上のカーソルの位置です。しかし、コンポーネントによる分解は、 OVERWRITE 処理がデータフィールドと画面の表示の両方の変更の面倒を見る事を我々に勧めました。 SLIDE< や SLIDE> も同様です。このため、メモリ内のデータアドレス、または画面上の桁位置のいずれかを計算できる、実際のポインタを1つだけ(相対ポインタ)を維持することが、今や自然なように思われます。
ポインタの性質は、 POSITION 、 FORWARD 、 BACKWARD の3つのプロセスの中に完全に隠されているので、たとえそれが最初のアプローチではなかったとしても、このアプローチにて容易に対応できます。
この変更は、ここでも十分に単純に思えたかもしれません。 もしそう思ったのなら、それはこの技法が柔軟な設計を保証するからです。 従来のアプローチを使用していた場合、つまり構造に従って、または順次プロセスによるデータ変換に従って設計していた場合、私たちの脆弱な設計は変更によって粉々になります。
この主張を証明するには、私たちは最初からやり直す必要があります。
伝統的なアプリケーションの設計と保守¶
タイニーエディタの問題に付いてまだ検討していないとしましょう。私たちは最小限の仕様の頃まで巻き戻します。各キーストロークの後でフィールド全体を再タイプすることで表示を更新できるという最初の仮定から再度始めます。
トップダウン設計の格言に従って、可能な限り広角の展望で問題を検証しましょう。 図 31 はプログラムを最も簡単に表現しています。 ここで、私たちは、エディタは実際にはユーザーがリターンキーを押すまで、キーストロークを取得して何らかの編集機能を実行し続けるループであることが分かりました。
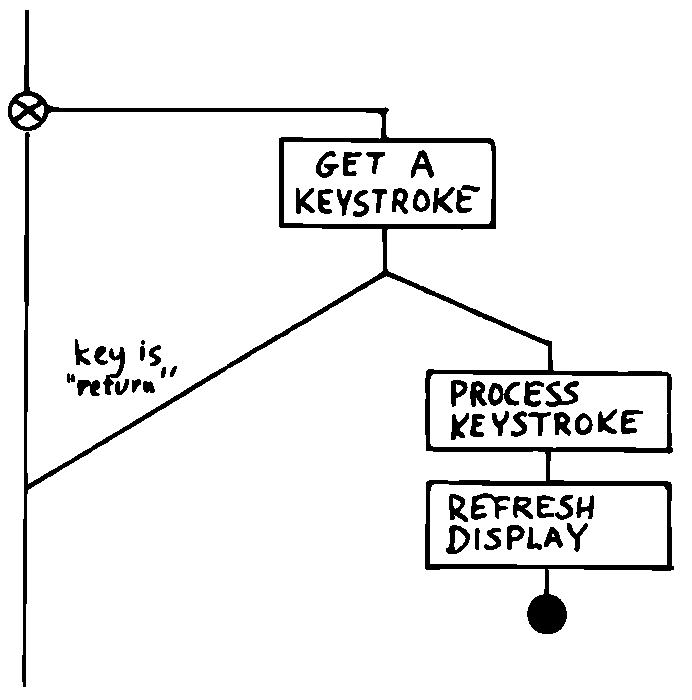
図 31 伝統的アプローチ:頂上から展望せよ。
ループ内には3つのモジュールがあります。それは、キーボードから文字を取得するモジュール、データを編集するモジュール、最後にデータに合わせて表示を更新するモジュールです。
明らかに、ほとんどの作業は「キーストロークの処理」内で行われます。
図 32 は、連続した改良の概念を適用して「キーストローク処理」を拡張して描き直したものです。この設定にたどり着くまでに数回試行する必要があります。 このレベルを設計すると、以前の試行で後にすると延期していた多くのことを一度に検討する必要があります。
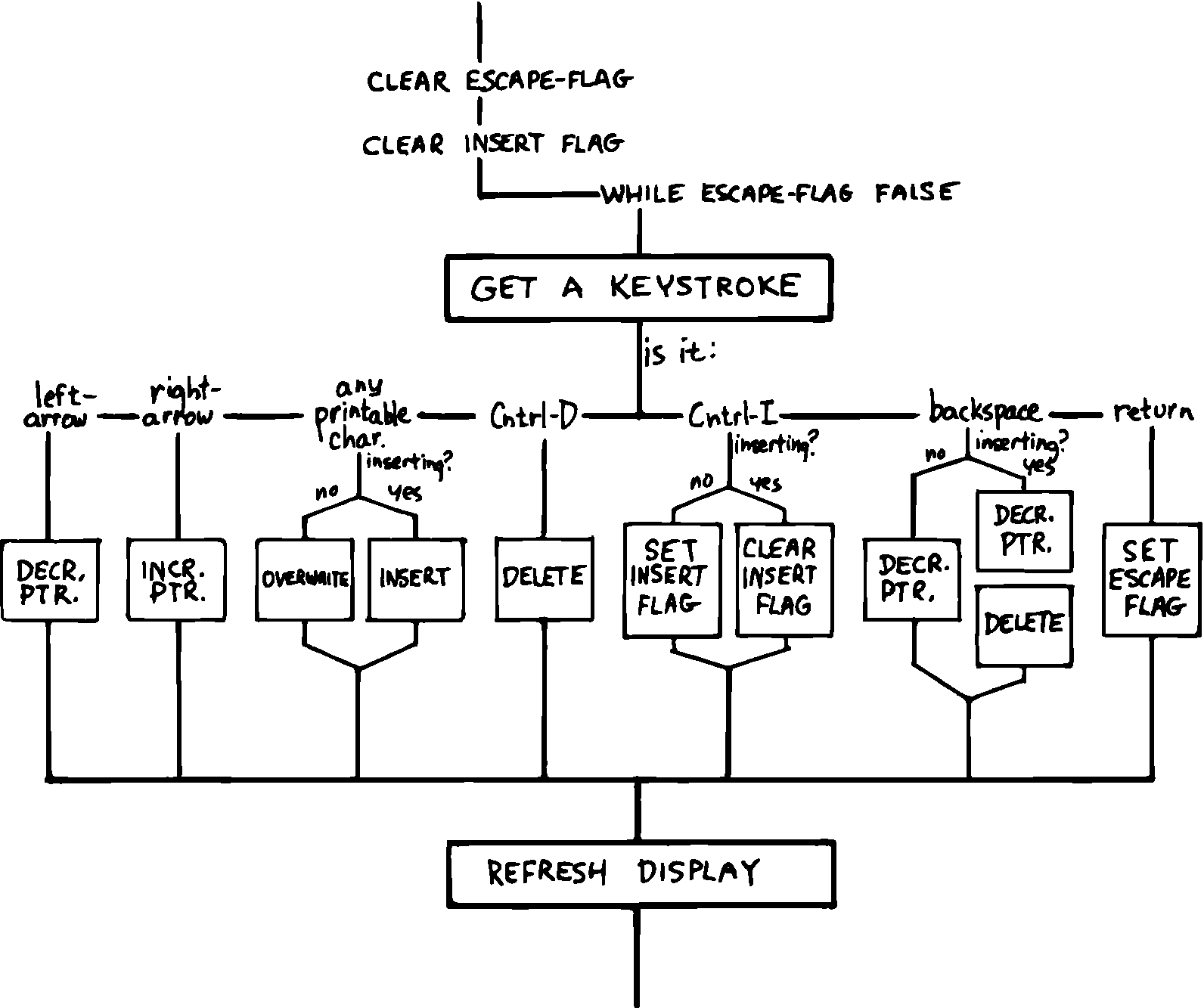
図 32 「キーストローク処理」の構造
たとえば、押される可能性のあるすべてのキーを決定する必要があります。 もっと重要なことに、「挿入モード」の問題を考慮しなければなりません。そのために、 Ctrl I キーによってON/OFFされる INSERT-MODE と呼ばれるフラグを作り出す必要があります。 それはいくつかの処理の流れの中で、ある型のキーどのように処理するかを決定するために使われます。
ESCAPE と呼ばれる2番目のフラグは、挿入モードではないときにユーザがリターンキーを押した場合に、エディタループをエスケープするための、素敵な構造化された方法を提供するように見えます。
図は完成しましたが、いま私たちは挿入モードのための複数の条件に悩まされています。 処理の初めで挿入モードかどうかの条件分岐が必要です。これを盛り込む為に、私たちはさらに別のチャートを描きます( 図 33 )。
ご覧のとおり、これは最初の図よりもさらに厄介です。 今や各キーについて2回テストしています。 興味深いのは、2つの構造がまったく異なるのに機能的には同一であることです。 この制御構造が問題に密接に関連しているのかどうかはなはだ疑問です。
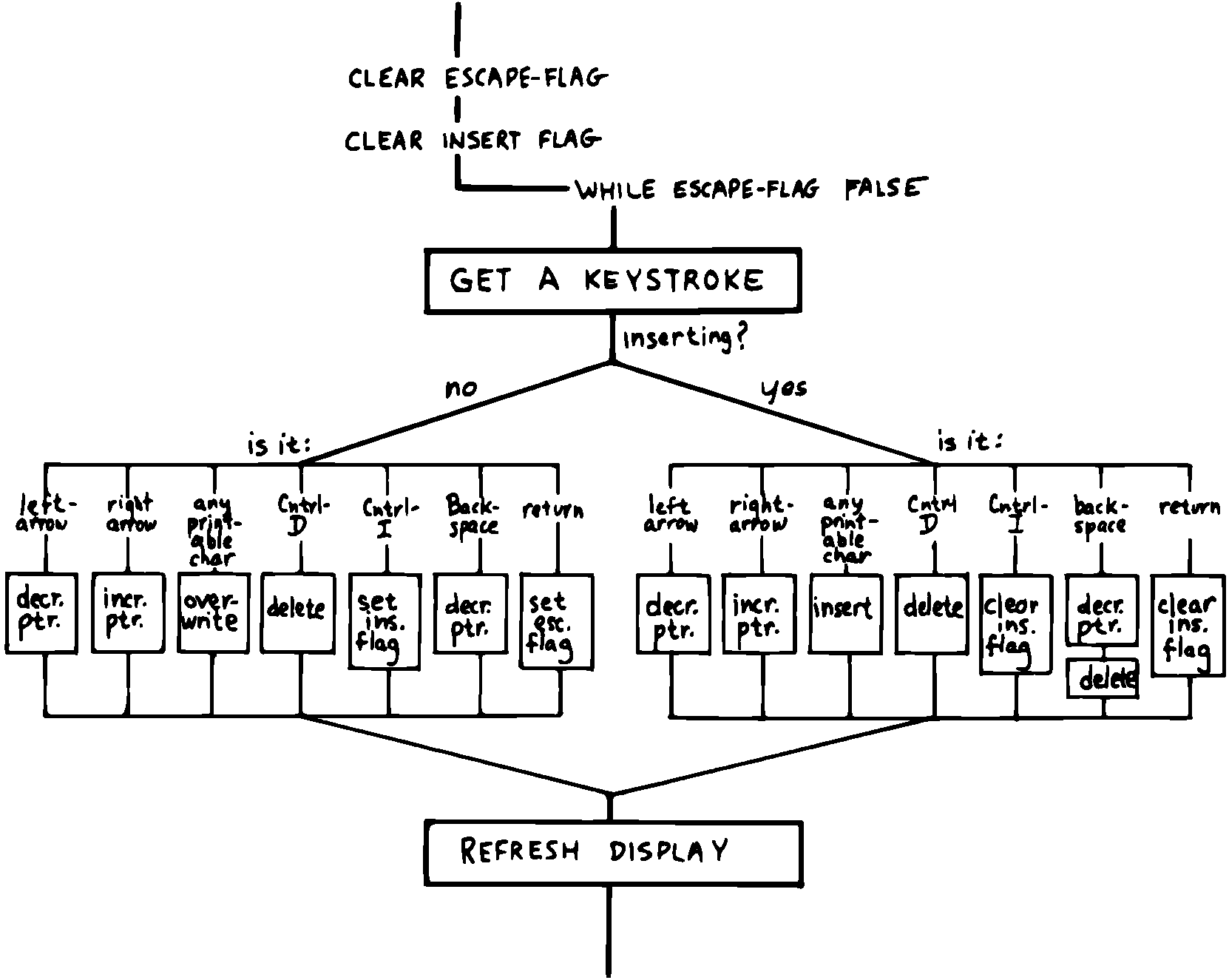
図 33 「キーストローク処理」の別の構造
最初の構造を決定したので、ついに最も重要なモジュール、つまり上書き、挿入、削除の作業を行うモジュールにたどり着きました。 図 32 の中のキーストローク処理部分をもう一度見てください。 考えられる7つの実行経路のうち、表示可能な文字が押された場合に発生する実行経路のうちの1つだけを考えてみましょう。
図 34 の(a)には、表示可能文字の処理の元々の経路が示されています。
文字を上書きして挿入するためのアルゴリズムを見つけたら、 図 34 の(b)のように洗練させるかもしれません。 しかし、コードの冗長性(点線で囲まれた部分)を見てください。 有能な構造化プログラマは、この冗長性は不要であると認識し、 図 34 の(c)のように構造を変更します。 今までところ、そんなに悪くないでしょう?
計画の変更¶
さて、おまえら聞いて驚け!たった今、このアプリケーションはメモリマップドディスプレイ(訳注:現在一般的な、メモリの特定の番地と画面の特定の位置が対応しているディスプレイ)では実行されないと判明しました。この変更は私たちの設計構造に何をもたらすでしょうか?
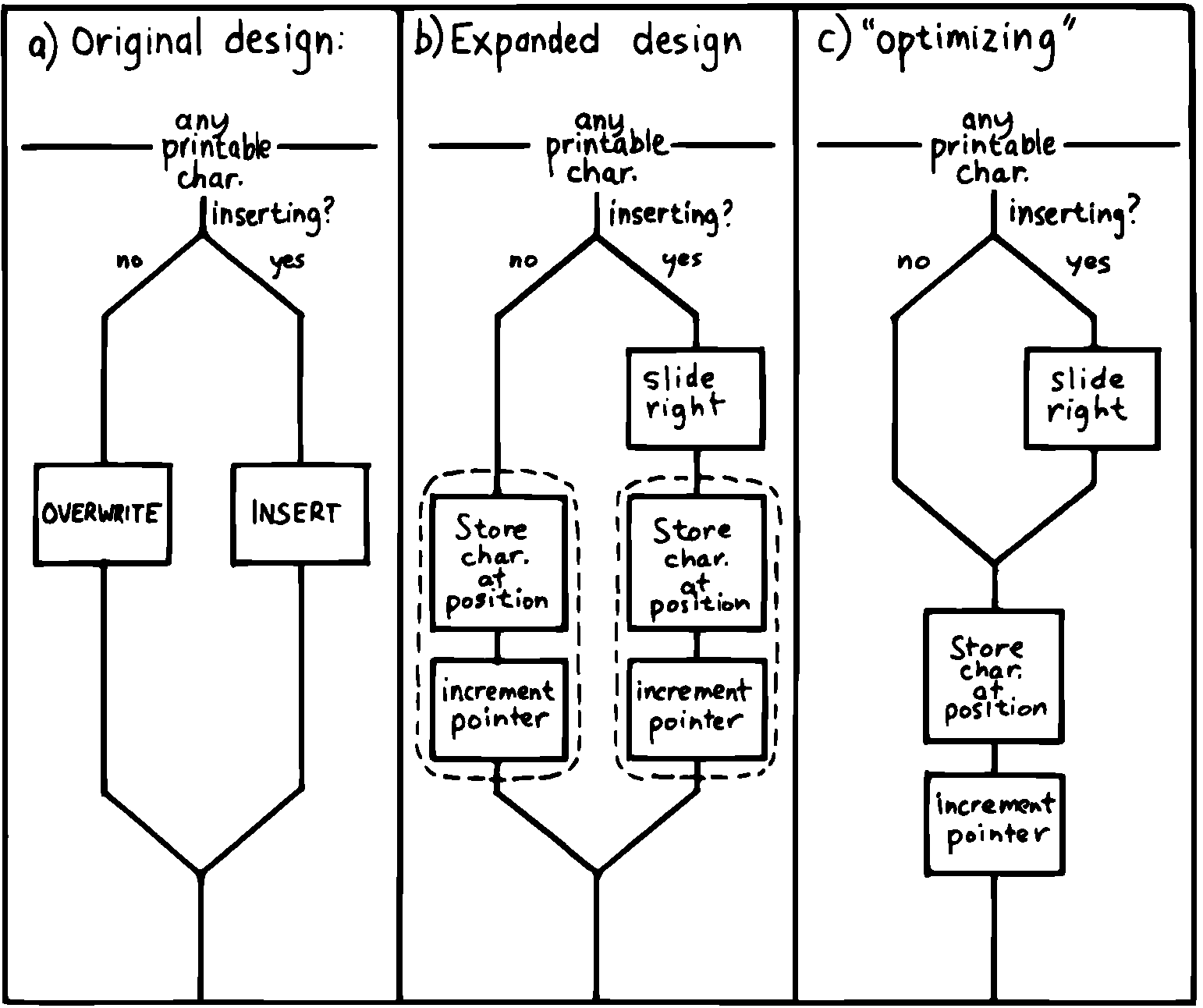
図 34 同一区間の「洗練」と「最適化」
そうですね、これは一つには、ばらばらのモジュールでの「画面更新」作業を破壊します。「画面更新」の機能は「キーストローク処理」内の様々な処理経路にちりばめられています。アプリケーション全体の構造を変えねばなりません。見当違いの事をしていたと見つけるためだけに、何週間も費やしてトップダウン設計を行った事は誰の目にも明らかです。
私たちがプログラムを変更しようとするとどうなりますか? 印刷可能な文字の処理経路をもう一度見てみましょう。
図 35 の(a)は、リフレッシュを追加したときに初回経路の設計がどうなるかを示しています。 パート(b)は、リフレッシュモジュールを拡張した「最適化」設計を示しています。 外側のループのこの単一の区間内で挿入フラグを2回テストしています。
しかしさらに悪いことに、この設計にはバグがあります。 あなたには分かりますか?
上書きと挿入どちらの場合も、ポインタをリフレッシュする前に増加させています。 上書きの場合は、新しい文字が間違った位置に表示されています。 挿入の場合は、行の残りの部分は入力しますが、新しい文字は入力されません。
はい、確かにこれは簡単に直せる問題です。 「ポインタの増加」前にリフレッシュモジュールを移動するだけです。ここでのポイントは、どうしてそれを見逃してしまったのかです。それはプログラム設計の表面的な要素である制御フロー構造に夢中になってしまったからです。
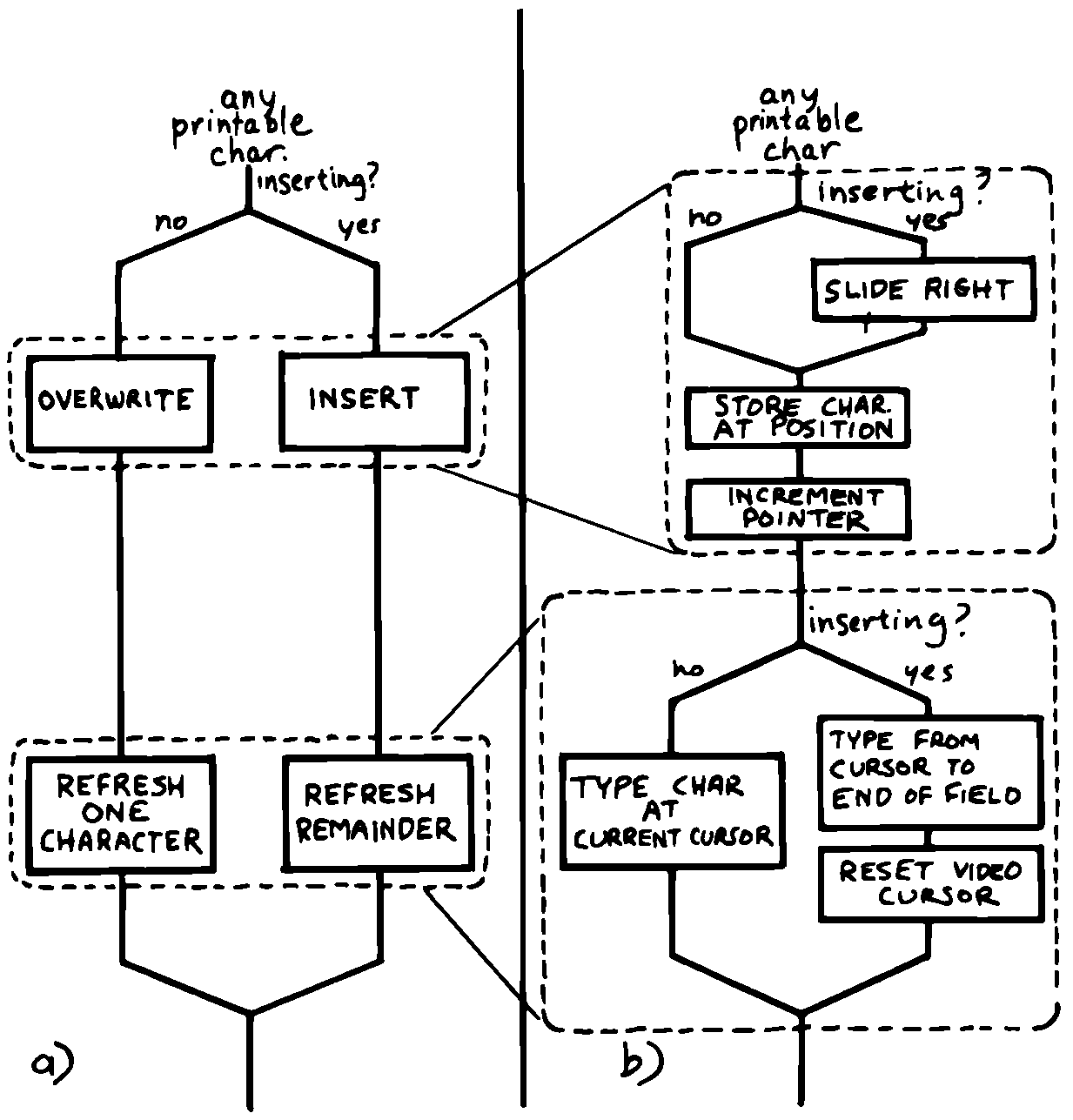
図 35 画面更新処理追加
対照的に、コンポーネントによる設計では、更新コンポーネントを編集コンポーネント内で「使用」したため、自然に正しい解決策に落着しました。つまり、私たちは INSERT 内部で OVERWRITE を使いました。
私たちのアプリケーションを、相互使用するコンポーネントに分解することによって、 優雅さ だけでなく 正しさ への、より直接的な道筋を実現しました。
インターフェイスコンポーネント¶
コンピュータサイエンスの用語では、モジュール間のインタフェースには2つの側面があります。 まず、他のモジュールがそのモジュールを呼び出す方法があります。 これが制御インターフェースです。 次に、他のモジュールがモジュールとの間でデータをやり取りする方法があります。 これがデータインタフェースです。
Forthの辞書構造のため、制御インターフェイスは問題になりません。 定義は名前付きで呼び出されます。 この節では、「インターフェース」という用語を使用するときは、データの参照の事です。
モジュール間のデータインターフェースに関しては、伝統的な知恵は「インターフェースは最小限の複雑さで慎重に設計されるべきである」と言うだけです( 図 36 )。
これは冗長コードの存在を意味します。 これまで見てきたように、冗長なコードは少なくとも2つの問題を引き起こします。それはかさばるコードと貧弱な保守性です。あるモジュールのインタフェースを変更すると、反対側のモジュールのインタフェースにも影響が及びます。
図 36 インターフェイスの伝統的な観点は接合点です。
これ以外にも優れたインターフェース設計があります。 「インターフェース・コンポーネント」と呼ぶ設計要素を紹介させて下さい。インターフェース・コンポーネントの目的は、2つ以上の他のコンポーネント間のデータ・インターフェースを実装し、情報を隠すことです( 図 37 )。
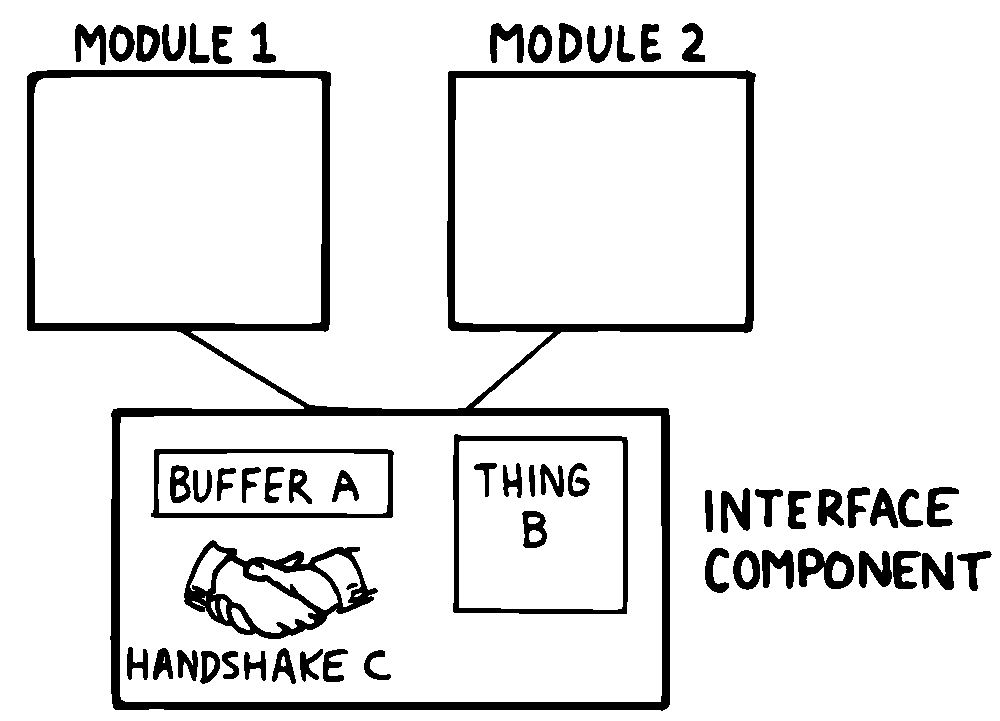
図 37 インターフェイス・コンポーネントの使用
ヒント
モジュール間のデータ通信に関連するデータ構造とコマンドは、両方ともインタフェースコンポーネントに局限すべきです。
私自身の最近の経験から例を挙げましょう。 私の趣味の1つは、テキストフォーマッタ・エディタを書くことです(この本を書くためのものを含み、2つ書きました)。
私の最新の設計では、フォーマッタ部分は2つのコンポーネントを含みます。 最初のコンポーネントはソース文書を読み、改行や改ページを入れる場所などを決定します。ただし、テキストを直接端末やプリンタに送信するのではなく、一度に1行分の値を「ラインバッファ」に保存します。
同様に、テキストがフォーマットされているときに、太字や下線などのプリンタ制御コマンドを送信する代わりに、テキストが実際に送信されるまでこれらのコマンドを延期します。 制御コマンドを延期するために、「属性バッファ」と呼ばれる2番目のバッファがあります。バイトごとに、ラインバッファと対応します。ただし、各バイトには、対応する文字に下線引くかどうかや太字にするかやその他を示す一連のフラグが含まれます。
2番目のコンポーネントは、ラインバッファの内容を表示または印刷します。 コンポーネントは、端末に送信しているのかプリンタに送信しているのかを認識し、属性バッファによって示されている属性に従ってテキストを出力します。
ここでは、2つの明確に定義されたコンポーネント(line-formatterとoutputコンポーネント)があり、それぞれがフォーマッター全体の機能の一部を担っています。
これら2つのコンポーネント間のデータインタフェースはかなり複雑です。 インタフェースは2つのバッファ、現在の有効文字数を示す変数、そして最後にそれらすべての属性パターンが何を意味するのかについての「知識」で構成されます。
Forthでは、これらの要素を1つのスクリーンにまとめて定義しました。 バッファは CREATE で定義され、カウントは通常の VARIABLE で、属性パターンは CONSTANT として定義されます。
1 CONSTANT UNDERNESS ( bit mask for underlining)
2 CONSTANT BOLDNESS ( bit mask for boldface)
フォーマット化コンポーネントは、属性バッファのビットを設定するために UNDERNESS SET-FLAG のようなフレーズを使います。 出力コンポーネントは属性バッファを読み込むために UNDERNESS AND のようなフレーズを使います。
設計ミス¶
インターフェイスコンポーネントを設計する際には、「通信するコンポーネントが共有する必要がある構造とコマンドのセットは何ですか?」と自問する必要があります。インターフェイスに属する要素と、1つのコンポーネント内に残す要素を決定することは重要です。
私のテキストフォーマッタを書いているとき、私はこの質問に完全に答えることができず、バグを発見しました。 以下の問題を発見しました。
縮小文字や倍角など、異なる幅の文字を使用することを許可します。これは、異なる信号をプリンタに送信するだけでなく、1行に許可される文字数を変更することを意味します。
フォーマッタのために WALL と呼ばれる変数を保持します。 WALL は右マージンを表します。これを超えると、それ以上テキストを設定できなくなります。 異なる型幅に変更することは、比例して WALL の値を変更することを意味します。 (実際には、これ自体は間違いです。私はもっと細かい単位を使用する必要があります。その数はその行では一定のままです。タイプ幅を変更すると、1文字当たりの単位数が変わることになります。 ポカミス…)
残念ながら、私は表示する文字数を決めるために出力コンポーネントの中で WALL を使っていました。 私の推論は、この値は私が使っていたタイプ幅によって変わるだろうということでした。
私は99%正しかった。 しかしある日、ある条件の下では、要約テキストの行がどういうわけか短くなっていることがわかりました。 最後の2、3の語はただ足りなかった。 その理由は、出力コンポーネントがそれを使用する機会を得る前に WALL が変更されていたことです。
もともと私は出力コンポーネントもフォーマッタの WALL を巧妙に使うようにしても問題ないと思っていました。 今、私はフォーマッタが、バッファに有効な文字がいくつあったかを示すため、出力コンポーネントのために別の変数を残さなければならないことに気づきました。 これにより、以降のフォントコマンドは自由に WALL を変更できるようになります。
2つのバッファ、属性コマンド、および新しい変数が、2つのモジュール間でのみ共有できる要素であることが重要でした。 他のモジュールからどちらかのモジュールにアクセスすると、問題が発生します。
この話の教訓は、単一のコンポーネント内でのみ有効に使用されるデータ構造と、複数のコンポーネントで共有される可能性のあるデータ構造を区別する必要があるということです。
関連する点:
ヒント
コンポーネント間で共有するデータを客観的な単位で表します。
例:
- モジュールAはオーブンの温度を測定します。
- モジュールBはバーナーを制御します。
- モジュールCは、オーブンがとても熱くなると、ドアがロックされていることを確認します。
皆が関心のある情報は、客観的に「度」で表現されたオーブンの温度です。 モジュールAは熱センサーから電圧を表す値を受け取ることがありますが、他のアプリケーションに表示する前にこの値を「度数」に変換する必要があります。
高度化させる順序による分解¶
私たちは、コンポーネントに応じて、それを分解する1つの方法を議論してきました。 2番目の方法は、高度化させる順序によるものです。
Forthの規則の一つは、ワードが呼び出されたり参照される前に、必ず定義済でなければならないということです。通常、ワードが定義されている順序は、そのワードが持っていなければならない能力を増加させる順序と同じです。この順序は、ソースリストの自然な構成を導きます。強力なコマンドは基本的なアプリケーションの上に単純に追加されています( 図 38 (a) )。
教科書のように、基本的なものが最初に来ます。 このプロジェクトの初心者は、高度なものに進む前に、コードの基本部分を読むことができます。
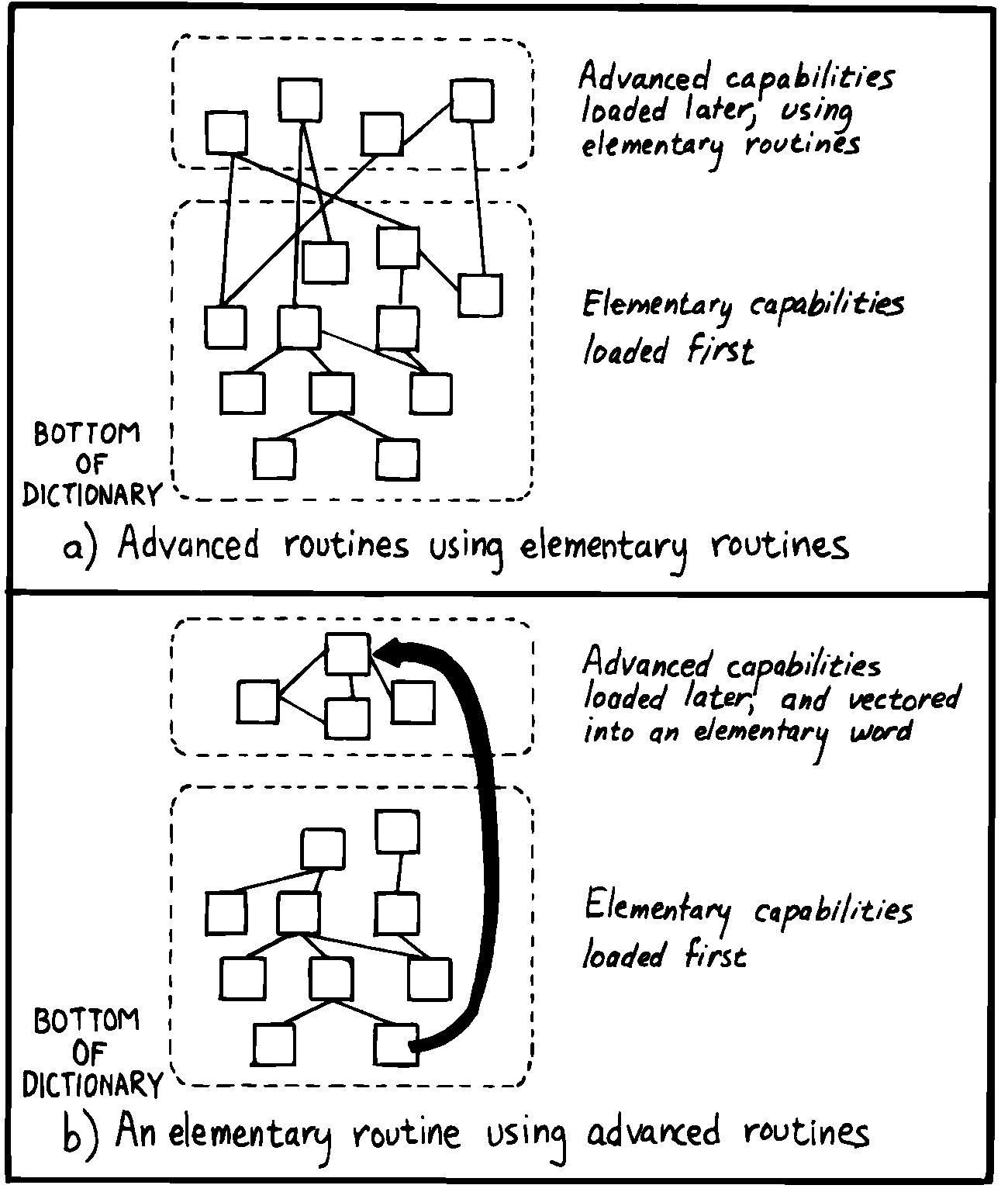
図 38 高度な機能を追加する2つの方法
しかし多くの大規模なアプリケーションでは、追加の機能はアプリケーションの基本部分にあるプライベートな根っこの機能の拡張として実装するのが一番です( 図 38 (b)))。 根っこの機能を変更できるようにすることで、ユーザは根っこを使用するすべてのコマンドの機能を変更できます。
ワードプロセッサの例に話を戻すと、かなり原始的なルーチンとして新しいページを開始するものがあります。改行するワードで使用されています。 行がなくなったら新しいページを開始する必要があります。 この改行するワードは、その行の語をフォーマットするルーチンによって使用されます。 次の語が現在の行に収まらない場合は、 NEWLINE を呼び出します。 この階層を「使う」ためには、アプリケーションの早い段階で NEWPAGE を定義する必要があります。
問題とは? 高度なコンポーネントの1つは、 NEWPAGE によって呼び出されるルーチンを含みます。 具体的には、図や表が(画面上は)テキストの途中に表示されていても、フォーマット時にページの残りに収まらない場合、フォーマッタはテキストの出力を続行しながら図を次のページに延期します。 この機能はどういうわけか NEWPAGE の中に入ることを必要とします、それで NEWPAGE が次に実行されるとき、それは新しいページの一番上に、延期していた図をフォーマットするでしょう。
: NEWPAGE ... ( terminate page with footer)
( start new page with header) ... ?HOLDOVER ... ;
How can NEWPAGE invoke ?HOLDOVER , if ?HOLDOVER is not defined until much
later?
高度な機能が根っこ機能の前に定義されるようリストを編成することは理論的には可能ですが、そのアプローチはよろしくない理由が2つあります。
第一に、(能力の度合いによる)自然な編成が破壊されます。第二に、高度なルーチンは、基本機能の中で定義されているコードを使用します。高度なルーチンをアプリケーションの根っこ側に移動する場合は、それらが使用する全てのルーチンを併せて移動するか、複製する必要があります。非常に面倒です。
「ベクトル化」という手法を使用して、高度化の度合いでリストを編成できます。根っこの機能が、根っこの機能以降に定義されているさまざまなルーチンのいずれかを呼び出す(指し示す)ことを許可できます。私たちの例では ?HOLDOVER の「名前だけ」を早めに作成しておく必要があります。その定義は後で与える事ができるのです。
Forthのベクトル化手法は 第7章 で扱います。
レベル思考の限界¶
私たちのほとんどは、「高レベル」と「低レベル」の違いを強調し過ぎているという罪を犯しています。この概念は任意のものです。 それはソフトウェアの問題について明確に考える私たちの能力を制限します。
伝統的な意味での「レベル」思考は、3方面から私たちの努力を歪めます。
- 開発の順序は階層構造に従うべきであるとしています。
- 各レベルはお互いに分離されるべきであるとし、再利用性の利点を妨げます。
- それはレベル間の構文上の違い(例えば、アセンブラ対高級言語など)と、私たちが機械語から遠ざかるにつっれてプログラミングの性質がなぜか変化するという信念を助長します。
これらの誤解をひとつひとつ調べてみましょう。
どこから初めましょうか?¶
私はムーアに、どのようにして特定のアプリケーション、子供向けのゲームを開発するのかについて尋ねました。 子供が数字キーパッドの数字を0から9まで押すと、同じ数の大きなボックスが画面に表示されます。
- ムーアは言います。
- 私はトップから始めません。それはうまくいきません。 正確には、私は箱を描くワードを書くでしょう。 私は一番下から始めて、キーボードを監視している「GO」というワードで終わります。
そのうちのどれだけが直感的ですか?
ある程度。 私はどこに到達すべきか知っているので、そこから始める必要はありません。 そして、キーボードをプログラムするよりもボックスを描く方が楽しいです。 問題を解決するために、最も楽しいことをします。 これらすべての詳細を後で整理する必要がある場合は、それが私が支払う対価です。
あなたは興味順アプローチを提唱しているのですか?
自由精神に基づくやり方でそれをやっているということなら、それはイエスです。2日間でお客様にデモンストレーションを行った場合は、別の方法で行います。 最もおもしろいものではなく、最も目に見えるものから始めます。 しかしそれでも、階層的な順序ではありません。 私は、顧客への感動、何か動くもの、他の人々に関心を引くためにどのように動くべきかを示すなど、より早急な検討を基本アプローチにしています。
レベルを「入れ子」と定義した場合であれば、はい、それは問題を分解するための良い方法です。 しかし、私は「レベル」という概念が有用であるとは思いませんでした。 レベルのもう一つの側面は、言語、メタ言語、メタ―メタ言語です。 アセンブラレベル、最初の統合レベル、最後の統合レベル。髪の毛をより分けたりするように、どのレベルにいるのかを試してみたりするのは、単調で面倒です。 私のレベルはすべて絶望的に混ざりあっています。
コンポーネントによる設計は、重要性の低いところから初めます。たとえば、キーインタプリタから始めることができます。 その目的は、キーストロークを受信して数字に変換し、これらの数字を内部的に呼び出されるワードに渡すことです。もしあなたがForthのワード . (ドット。スタックから数字を出力する) で代用すれば、私たちはキーインタプリタを実装することができます、それをテストして、そして、正方形の描画に関係のあるルーチンを使用せずにそれをデバッグします。一方、アプリケーションが今現在手元にないハードウェアサポートパッケージ(グラフィックパッケージなど)を必要とする場合は、問題を解決するために、とりあえずアスタリスクを表示するなど、利用可能なものに置き換えることをお勧めします。 用語集の観点から考えることは、いくつかのキャンバスにまたがる巨大な壁画を描くようなものです。 すべてのキャンバスにまんべんなく一度に作業します。最初に重要な設計要素を全てのキャンバスにスケッチしてから、壁画全体が完成するまであちこちに色を入れていきます。
ヒント
どこから設計を始めるかを迷っている時は、以下を参考にしてください。
- 最も創造性が要求される分野(変化が最も起こりそうな分野)
- 最も満足のいくフィードバックを与える領域
- アプローチが決定された分野は他の分野に大きな影響を与えるでしょう。あるいは述べられた問題が解決できるかどうか決定するでしょう。
- 相互理解のために、顧客に見せるべきもの
- 借り入れに必要な場合は、投資家に見せることができます。
表現しないところは分離作業しない。¶
レベルが最適な解を妨げる可能性がある2つ目の方法は、レベルの分離を促進することです。 「オブジェクト」と呼ばれる一般的な設計構成は、この危険な哲学の典型です。 [1]
オブジェクトは、単一の名前で呼び出すことができるコードの一部ですが、複数の機能を実行できます。 特定の機能を選択するには、オブジェクトを呼び出してそれにパラメータまたはパラメータのグループを渡す必要があります。 オブジェクトが、思いどおりに機能させるために押すことができるボタンの列を表すものとして、パラメータを視覚化できます。
オブジェクトの観点からアプリケーションを設計することの利点は、コンポーネントのように、オブジェクトがアプリケーションの他の部分から情報を隠し、改訂を容易にすることです。
ただし、いくつか問題があります。 第一に、オブジェクトはどの機能を実行しなければならないかを決定するために複雑な決定構造を含まなければならない。 これにより、オブジェクトサイズが大きくなり、パフォーマンスが低下します。 一方、用語集は、直接呼び出すための使用可能なすべての機能を名前で提供します。
第二に、オブジェクトは通常独立して設計されています。 サポートコンポーネントによって提供されるツールを利用することはできません。 その結果、アプリケーション内の他の場所に現れるコードをそれ自体の内部に複製する傾向があります。 いくつかのオブジェクトはそれらのパラメータを解釈するためにテキストを解析することさえ要求されます。 それぞれ独自の構文を使うことさえできます。 時間とエネルギーの恥知らずな無駄づかいです!!
図 39 「スクランブルエッグにはできないの?」
最後に、オブジェクトは有限の可能性を認識するように構成されているため、新しい機能が必要なときにボタンの列に追加するのは困難です。 オブジェクト内のツールは再利用できるようには設計されていません。
レベルの考え方は、IBMパーソナルコンピュータの設計にも広がっています。 プロセッサ自体(もちろん、独自の機械命令セットを使用した)の他に、以下のソフトウェアのレベルがあります。
- アセンブラで書かれ、システムのROMに書き込まれた一連のユーティリティ(訳注:BIOS)
- ユーティリティを起動するディスクオペレーティングシステム
- オペレーティングシステムとユーティリティを呼び出す高級言語
- そして最後に、その言語を使用しているアプリケーション。
ROMユーティリティは、ハードウェアに依存するルーチン(ビデオ画面、ディスクドライブ、およびキーボードを処理するルーチン)を提供します。 特定のレジスタに制御コードを入れて適切なソフトウェア割り込みを生成することによってそれらを呼び出します。
例えば、ソフトウェア割り込み10Hはビデオルーチンに入る。 これらのルーチンは16個あります。 あなたは必要なビデオルーチンの番号をレジスタAHにセットします。
残念ながら、その16個のルーチンのいずれも文字列を表示するものはありません。 あなたがやることは、どのルーチンか必要か選び、文字列の全ての文字のために、レジスタにセットしてソフトウェア割り込みを生成する処理を繰り返し行う必要があります。そして、あなたは必要としていない他のいつくかの事をします。
各キーストローク毎に画面全体を更新する必要があるテキストエディタを書いてみてください。 えらく遅いな! 外部で提供されているものを除き、ビデオルーチン内の情報を再利用することはできないため、速度を向上させることはできません。 このような書き方をする理由は、プログラマをデバイスアドレスやその他のハードウェアの詳細から絶縁するためです。 どのみちこれらは将来のアップグレードで変わる可能性があります。
このマシンでビデオI/Oを効率的に実装する唯一の方法は、文字列をビデオメモリに直接移動することです。 リファレンスマニュアルにはビデオメモリの開始アドレスが記載されているので、これは簡単にできます。 しかし、これはシステムの設計者の意図に反します。 あなたのコードはもはやハードウェアの更新に耐えられないかもしれません。
プログラマを細部から「保護」することによって、分離は情報隠蔽の目的を打ち砕きます。対照的に、コンポーネントは分離されたモジュールではなく、辞書への累積的な追加です。 少なくとも、ビデオ用語集はビデオメモリのアドレスに名前を付けます。
必要に応じて使う、コンポーネント間のビットON/OFF機能インターフェイスの概念は、何も悪いことではありません。ここでの問題は、このビデオコンポーネントが不完全に設計されていることです。 一方、システムが完全に統合されている場合(オペレーティングシステムとForthで書かれたドライバ)、ビデオコンポーネントはすべてのニーズに合うように設計される必要はありません。 アプリケーションプログラマは、ビデオ用語集から入手可能なツールを使用して、ドライバを書き直すか、ドライバを拡張することができます。
ヒント
あなたの道具を詰め込まないで下さい。
泡の塔¶
レベル思考による最後の詐欺は、プログラミング言語が高水準ほど質的に異なるようになるべきであるという思い込みです。 高水準のコードはめったに見られないありがたいものとして、低レベルのコードは不器用で不敬なものとして話す傾向があります。
これらの区別はある程度は妥当性がありますが、これは私たち全員が標準として受け入れている特定の恣意的なアーキテクチャ上の制約の結果にすぎません。 簡潔なニーモニックと不自然な構文を持つアセンブラはあたりきりのものとみなしているのは、それが「低レベル」だからです。
コンポーネントの概念は、高レベルと低レベルの対立の概念に反しています。 すべてのコードの見た目は同じであるべきです。 コンポーネントとは、データ構造とアルゴリズムをまとめて便利な機能に変換する一連のコマンドです。これらの機能は、その中の構造やアルゴリズムに関する知識がなくても使用できます。
実際の機械語から、これらの構造までの距離は関係ありません。 出力ポートのビットをON/OFFするために書かれたコードは、理屈としては、レポートをフォーマットするためのコードよりも恐ろしげにに見えるべきではありません。
機械語でも充分読みやすくあるべきです。 真のForthベースのエンジンは、今日私たちが知っている「高レベル」辞書と同様の、恒久的な構文と辞書を享受するでしょう。
要約¶
この章では、アプリケーションをコンポーネントに分解できることを説明しました。それはコンポーネントによる分解と、高度化させる順序による分解の2つの方法です。
他のコンポーネント間のインターフェースとして機能するコンポーネントには特別な注意を払う必要があります。
いまや、予備設計を正しく行った場合、問題は管理しやすい部分がたくさんあることになります。 各部分は解決するべき問題を表します。 お気に入りの部分をつかみ、次の章に進んでください。
さらなる思考のために¶
(解答は 付録 D )
以下は、エディタのキーボードインタプリタを定義する2つの方法です。 どちらがいいですか? それは何故ですか?
(a).
( Define editor keys ) HEX 72 CONSTANT UPCURSOR 80 CONSTANT DOWNCURSOR 77 CONSTANT RIGHTCURSOR 75 CONSTANT LEFTCURSOR 82 CONSTANT INSERTKEY 83 CONSTANT DELETEKEY DECIMAL ( Keystroke interpreter) : EDITOR BEGIN MORE WHILE KEY CASE UPCURSOR OF CURSOR-UP ENDOF DOWNCURSOR OF CURSOR-DOWN ENDOF RIGHTCURSOR OF CURSOR> ENDOF LEFTCURSOR OF CURSOR< ENDOF INSERTKEY OF INSERTING ENDOF DELETEKEY OF DELETE ENDOF ENDCASE REPEAT ;
(b).
( Keystroke interpreter) : EDITOR BEGIN MORE WHILE KEY CASE 72 OF CURSOR-UP ENDOF 80 OF CURSOR-DOWN ENDOF 77 OF CURSOR> ENDOF 75 OF CURSOR< ENDOF 82 OF INSERTING ENDOF 83 OF DELETE ENDOF ENDCASE REPEAT ;
この問題は、情報隠蔽の課題です。 (何らかの理由で)Forthディクショナリの外部にデータ構造に割り当てたいメモリ領域があるとします。 メモリ領域はHEXアドレスC000から始まります。 そのメモリに常駐する一連の配列を定義したいと思います。
私たちはこのようにするかもしれません。
HEX C000 CONSTANT FIRST-ARRAY ( 8 bytes) C008 CONSTANT SECOND-ARRAY ( 6 bytes) C00C CONSTANT THIRD ARRAY ( 100 bytes)
上記で定義した各配列要素名は適切な配列要素の開始アドレスを返します。 しかし、すでに割り当てられているバイト数に基づいて、各配列要素の正しい開始アドレスを計算する必要があることに注意してください。
>RAMという「アロケーションポインタ」を保持して、次の空きバイトがどこにあるかを示すことで、これを自動化してみましょう。 まずポインタをRAM空間の先頭に設定します。VARIABLE >RAM C000 >RAM !
これで各配列要素を次のように定義できます。
>RAM @ CONSTANT FIRST-ARRAY 8 >RAM +! >RAM @ CONSTANT SECOND-ARRAY 6 >RAM +! >RAM @ CONSTANT THIRD-ARRAY 100 >RAM +!
配列要素を定義したら、次の新しい配列要素のサイズ分だけポインタを増やして、その分多くのRAMを割り当てたことを確認します。
上記をより読みやすくするために、これら2つの定義を追加します。
: THERE ( -- address of next free byte in RAM) >RAM @ ; : RAM-ALLOT ( #bytes to allocate -- ) >RAM +! ;
これを上記と等価に書き換えることができます。
THERE CONSTANT FIRST-ARRAY 8 RAM-ALLOT THERE CONSTANT SECOND-ARRAY 6 RAM-ALLOT THERE CONSTANT THIRD-ARRAY 100 RAM-ALLOT
(上級のForthプログラマーは、おそらくこれらの操作を1つの定義用語にまとめますが、そのまとめたモノ自体は私が話を向けているものと密接な関係があるわけではありません。)
最後に、このような配列定義が20個もアプリケーション全体に散在しているとします。
さて、今、どういうわけか私たちのシステムのアーキテクチャが変化し、私たちはそれがHEXアドレスEFFFで「終わる」ようにこのメモリを割り当てなければいけないことになりました。言い換えれば、最後から始めて、配列を逆方向に割り当てなければなりません。ただし、各配列要素名は「開始」アドレスを返さなければなりません。
これを行うには、次のように書きます。
F000 >RAM ! ( EFFF, last byte, plus one) : THERE ( -- address of next free byte in RAM) >RAM @ ; : RAM-ALLOT ( #bytes to allocate) NEGATE >RAM +! ; 8 RAM-ALLOT THERE CONSTANT FIRST-ARRAY 6 RAM-ALLOT THERE CONSTANT SECOND-ARRAY 100 RAM-ALLOT THERE CONSTANT THIRD-ARRAY
今回は
RAM-ALLOTはポインタを「デクリメント」します。 大丈夫、RAM-ALLOTの定義にNEGATEを追加するのは簡単です。 私たちが現在懸念していることは、配列を定義するたびに、それを定義する前に「RAM-ALLOT」する必要があるということです。 コードの中から20箇所を見つけて修正する必要があります。THEREとRAM-ALLOTというワードは素晴らしくて親しみやすいものですが、領域の割当方法を隠すことには成功していません。 領域の割当方法を隠せていたなら、それを私たちがどの順序で呼び出したかは問題になりません。ついに私たちの質問にたどり着きました。この設計変更の影響を最小限にするために、
THEREとRAM-ALLOTに何をしたらいいでしょうか(繰り返しますが、私が探している答えはワードを定義することとは関係ありません)。
脚注
| [1] | 編集者 Bernd Paysn より: 1994年度版への序文 の概説と、 2004年度版への序文 の説明を参照してください。Windows COMの「オブジェクト」やCORBAのようなものを考えてください。実際のオブジェクト指向プログラミングは、Smalltalkに由来するので、プログラマから情報を隠すことはありません。「卵マスターオブジェクト」に「スクランブルエッグ作成」メソッドを追加しても問題ありません。Smalltalkは既知のクラスにメソッドを追加することで機能します。それらをサブクラス化する必要はありません。あなたはいつでもオブジェクトとそのソースコードの内側を見ることができます。また、表駆動によるメソッドのディスパッチは非常に効率的です。 |