第8章 制御構造の最小化¶
Forthでは、制御構造は他の言語ほど重要ではありません。 Forthのプログラマは、 IF…THEN 構造をあまり強調せずに、短いワードで非常に複雑なアプリケーションを書く傾向があります。
制御構造を最小化するためのいくつかの手法があります。 本章には以下の内容が含まれます。
- コンピューティング あるいは 計算
- リファクタリング(再要素分解)による条件文の非表示
- 構造化された脱出の使用
- ベクトル化
- 再設計
この章では、コードから制御構造を、単純化および削除する、これらの手法について調査します。
制御構造の何がそんなに悪いの?¶
ヒントのリストを読み始める前に、なぜ条件文を回避する必要があるのかを検討してみましょう。
条件付き構造を使用すると、コードが複雑になります。 コードが複雑になればなるほど、それを読んで保守するのは難しくなります。 機械の部品数が多いほど、故障する可能性が高くなります。 そして、誰かが直すのが難しくなります。
- ムーア はこんなストーリーを語ります。
私は最近数年前に仕事をしていた会社に戻りました。 彼らのプログラムは5歳になり、とても複雑になったので、彼らは私に電話をかけてきました。プログラマは、状態変数と条件文を追加して、物事にパッチを当てていました。 私が5年前に単純なものであったことを思い出すすべてのステートメントは、今非常に複雑になっています。「もしならば コレ でなければ ソレ もしでなければ アレ…そしてそれからなにか単純な事をする」と言った具合です。
今や、そのステートメントを読んで、私はそれが何をしているのか、そしてその理由を理解することは不可能でした。 私は、各変数が何を示しているのか、なぜそれがこの場合に関連があるのか、そしてその結果として何が起こっていたのか、あるいは起こらなかったのかを覚えておかなければなりません。
それは無邪気に始まった。 彼らは心配する必要がある特別なケースを持っていました。 その特別なケースを処理するために、彼らはある場所に条件文を置きます。 それから彼らはまた、それらがここやそこでれを必要とすることを発見した。 そして、階段を登るようなステップでプログラムに少しづつ混乱を追加しました。 彼らはプログラマだったので、今や彼らは階段の頂上にいます。
最終結果は悲惨でした。 結局、彼らは半ダースのフラグを抱え込んでいました。これをテストし、リセットし、設定しなければなりません。この状態の結果として、気をつけなければならない他の状態がやってくることを知っていました。 彼らは、構造化プログラムの可能性にもかかわらず、スパゲッティプログラムと論理的に同等なものを作成しました。
複雑さは彼らが今まで意図していたものをはるかに超えていました。 しかし、彼らはこの道を進むことを決心していました、そして彼らはそれをすべて不要にしたであろう単純な解決策を逃しました。それは 1つではなく2つのワードを持つこと。あなたは
GOと言うか、PRETENDと言うかのどちらかです。ほとんどのアプリケーションでは、状態をテストする必要がある回数は著しく少ないです。たとえば、ビデオゲームでは、「ボタンAを押した場合はこれを行い、ボタンBを押した場合はそれ以外のことをします」と言っているのではありません。 あなたはそのような論理を経験しません。
彼がボタンを押すと、あなたは何かをする。 あなたがすることはロジックではなくボタンに関連付けられています。
条件文自体はそれほど悪くありません。それらは本質的な構成要素です。 しかし、多くの条件付きプログラムは不器用で読みにくいものです。 あなたができることは、それぞれ一つずつ質問することです。 どの条件文でも、「私は何を間違っているのですか?」と尋ねるべきです。
条件付きで試そうしていることは別の方法でも可能です。 さまざまな方法による長期的な結果は、条件式による長期的な結果よりも優先されます。
いくつかの詳細なテクニックを紹介する前に、特定の例で条件文を使うための3つのアプローチを見てみましょう。 リスト 14 、 リスト 15 、 リスト 16 は現金自動預払機の3種類の設計を表しています。
AUTOMATIC-TELLER
IF card is valid DO
IF card owner is valid DO
IF request withdrawal DO
IF authorization code is valid DO
query for amount
IF request < current balance DO
IF withdrawal < available cash DO
vend currency
debit account
ELSE
message
terminate session
ELSE
message
terminate session
ELSE
message
terminate session
ELSE
IF authorization code is valid DO
query for amount
accept envelope through hatch
credit account
ELSE
message
terminate session
ELSE
eat card
ELSE
message
END
最初の例は、構造化プログラミングスクールから直接得られたものです。 アプリケーションのロジックは、IFステートメントの正しいネストに依存します。
読みやすいですか? じゃあ、ユーザのキャッシュカードがどのような状況で食べられちゃうのか私に教えてください。 答えるには、下からELSEを数えて上から同じ数のIFと一致させるか、定規を使用する必要があります。
AUTOMATIC-TELLER
PROCEDURE READ-CARD
IF card is readable THEN CHECK-OWNER
ELSE eject card END
PROCEDURE CHECK-OWNER
IF owner is valid THEN CHECK-CODE
ELSE eat card END
PROCEDURE CHECK-CODE
IF code entered matches owner THEN TRANSACT
ELSE message, terminate session END
PROCEDURE TRANSACT
IF requests withdrawal THEN WITHDRAW
ELSE DEPOSIT END
PROCEDURE WITHDRAW
Query
If request &(&le&) current balance THEN DISBURSE END
PROCEDURE DISBURSE
IF disbursement &(&le&) available cash THEN
vend currency
debit account
ELSE message END
PROCEDURE DEPOSIT
accept envelope
credit account
2番目のバージョン リスト 15 は、名前付きの小さな手続きをたくさん使うことで読みやすさが向上することを示しています。 所有者が無効な場合は、ユーザのカードが食べられちゃいます。
しかし、この改善があっても、各ワードの設計はテストが実行されなければならないシーケンスに完全に依存します。 おそらく「最高」レベルの手順は、最悪の場合、最も簡単な種類のイベントを排除することに苦労します。そして各テストは次のテストを呼び出す責任を負います。
\ AUTOMATIC-TELLER
: RUN
READ-CARD CHECK-OWNER CHECK-CODE TRANSACT ;
: READ-CARD
valid code sequence NOT readable IF eject card QUIT
THEN ;
: CHECK-OWNER
owner is NOT valid IF eat card QUIT THEN ;
: CHECK-CODE
code entered MISmatches owner's code IF message QUIT
THEN ;
: READ-BUTTON ( -- adr-of-button's-function)
( device-dependent primitive) ;
: TRANSACT
READ-BUTTON EXECUTE ;
1 BUTTON WITHDRAW
2 BUTTON DEPOSIT
: WITHDRAW
Query
request &(&le&) current balance IF DISBURSE THEN ;
: DISBURSE
disbursement &(&le&) available cash IF
vend currency
debit account
ELSE message THEN ;
: DEPOSIT
accept envelope
credit account ;
3番目のバージョンはForthの約束に最も近いものです。 最高レベルのワードは、概念的に起こっていることを正確に表現しており、主要な経路のみを示しています。 従属ワードのそれぞれは、それ自体のエラー出口を持ち、主語の読みを乱雑にしません。 あるテストで次のテストを呼び出す必要はありません。
また、 TRANSACT は、ユーザがキーパッドのボタンを押すことによって要求を出すという事実に基づいて設計されています。 条件文は必要ありません。 一つのボタンは引き出しを開始し、もう一つは預金を開始します。 このアプローチは、振込のための機能の追加など、後の設計変更に容易に対応します(そして、このアプローチはハードウェアに依存するようにはなりません。キーパッドへのインターフェースの詳細は、キーパッド用語集の READ-BUTTON と BUTTON の中に隠されるかもしれません)。
もちろん、Forthはあなたが3つのアプローチのどれでも取ることを可能にするでしょう。 あなたはどれが好きですか?
制御構造を取り除く方法¶
この節では、条件を単純化または回避するための多数の技法を学びます。 それらのほとんどは、より読みやすく、より保守しやすく、そしてより効率的なコードを生成します。 いくつかの技法はより効率的なコードを生成しますが、いつも読みやすいとは限りません。 したがって、次の点に注意してください。すべてのヒントがすべての状況に適用できるわけではありません。
辞書(dictionary)の使用¶
ヒント
各機能に独自の定義を与えて下さい。
Forth辞書を適切に使用することによって、実際には条件文を排除するわけではありません。 我々は単にそれらを我々のアプリケーションコードから除外しているだけです。 Forth辞書は巨大な文字列のcase文です。 match機能とexecute機能はForthシステム内に隠されています。
- ムーアは言います。
私の会計パッケージでは、誰かから小切手を受け取ったら、金額、小切手番号、ワード
FROM、そしてその人の名前を入力します。200.00 127 FROM ALLIED
FROMというワードがその状況を処理します。 誰かに請求したい場合は、金額、請求書番号、ワードBILL、およびその人の名前を入力します。1000.00 280 BILL TECHNITECH
…それぞれの状況に1ワード。 辞書が決定を下しています。
この概念はForth自体に広がっています。 一対の1倍長数を追加するためには、コマンド + を使います。 2倍長数のペアを追加するには、コマンド D+ を使います。 効率が悪く、より複雑なアプローチは、どのタイプの数字が追加されているかをどうにかして「知る」単一のコマンドです。
FROM と BILL と + と D+ のすべてのワードをテストや分岐の必要なしに実装できるので、Forthは効率的です。
ヒント
愚直なワードを使って下さい。
これはテレビ作家の為のアドバイスではありません。 辞書を使うのは別の例です。 「愚直な」ワードは、状態に依存しないワードですが、代わりに常に同じ動作をします(「参照透過性」)。
愚直な言葉はあいまいさがないため、より信頼できるものです。
最近、この問題に関していくつかの一般的なForthの言葉が論争の的となっています。 そのようなワードの1つは、文字列を出力する ." です。最も単純な形式では、コロン定義内でのみ使用できます。
: TEST ." THIS IS A STRING " ;
実際には、このバージョンのワードは文字列を出力しません。 実行時に出力を行う別の定義のアドレスとともに、文字列を「コンパイル」します。
これは愚直なワードです。 コロン定義の外で使用すると、文字列を無駄にコンパイルしてしまいます。初心者が期待することはまったく行いません。
この問題を解決するために、FIGモデルではシステムが現在コンパイルしているのか解釈しているのかを決定するテストを内部に追加しました。最初の場合、文字列とプリミティブのアドレスがコンパイルされます。そして2番目場合、それは TYPE` です。
." は、 IF…ELSE…THEN 構造を持ち、2つのまったく異なるワードを1つに纏めたワードになりました。Forthがコンパイル時であるか実行時であるかを示すフラグは STATE (状態)と呼ばれます。." は STATE に依存するため、文字通り「状態依存(state-dependent)」と言われます。
コマンドは、コロン定義の内側と外側で同じ動作をするように見えました。 この重複は、Forthをてきとうに学ぶ学生には役立ちましたが、真面目な学生はすぐにそれ以上のものがあることを知りました。
生徒が自分のディスプレイに明るい文字で文字列を表示するために、 B." (bright-dot-quote)という新しいワードを書きたいとします。
." INSERT DISK IN " B." LEFT " ." DRIVE "
彼女は B." を以下のように定義することを期待するかもしれません。
: B." BRIGHT ." NORMAL ;
つまり、ビデオモードを「bright」に変更し、文字列を出力してから、モードを標準にリセットします。
彼女はそれを試します。 すぐに幻想は破壊されます。 まやかしが明らかになります。定義はうまくいきません。
彼女の問題を解決するために、プログラマは自分のシステムで (.") の定義を研究しなければならないでしょう。 (.") がどのように機能するかの説明はここではしません。ポイントは、そのスマートさがそれだけではないということです。
ちなみに、私たちの生徒の問題に対する異なる構文的アプローチがあります。それは、文字列を印刷するために2つの別々のワード ." と B." を持つ必要がないというものです。 システムの (.") を変更して、ほとんどの場合はすでに通常のモードになっていても、出力後は常にモードを通常に設定するようにします。この構文では、プログラマは強調文字列の前に BRIGHT というシンプルなワードを追加するだけです。
." INSERT DISK IN " BRIGHT ." LEFT " ." DRIVE "
FORTH-83規格では、現在、愚直な ." を指定しています。そして、解釈版が必要な場合は、新しい単語を追加しています(幸せな事に、この新しい規格では、2つの別々のワードを持つ辞書を使う事ができます)。
「 ' (ティック)」というワードにも同様の歴史があります。これはfig-Forthでは STATE 依存で、現在は FORTH-83規格では愚直(dumb)です。 ' (ティック) は ." (ドット・クォート)と、プログラマがこれらのワードのどちらかをより高いレベルの定義で再利用し、それらが通常と同じように振る舞わせることを望んでいるという特性を共有します。
ヒント
より高水準の定義内からそのワードを呼び出し、そのワードが名前の通りの解釈に従って振る舞うと期待するなら、そのワードは STATE に依存すべきではありません。
ASCII は STATE 依存ワードとしてうまく機能し、 MAKE も同様に機能します( 付録C 参照)。
条件文の入れ子と結合¶
ヒント
既に除外されているものをテストしないでください。
以下の例を見てください。
: PROCESS-KEY
KEY DUP LEFT-ARROW = IF CURSOR-LEFT THEN
DUP RIGHT-ARROW = IF CURSOR-RIGHT THEN
DUP UP-ARROW = IF CURSOR-UP THEN
DOWN-ARROW = IF CURSOR-DOWN THEN ;
このバージョンでは、4つのテストすべてをテストの結果に関係なく行わなければならないため、非効率的です。 押されたキーが左矢印キーであれば、それが他のキーであるかどうかを確認する必要はありません。
代わりに、あなたは次のように条件文を入れ子にすることができます。
: PROCESS-KEY
KEY DUP LEFT-ARROW = IF CURSOR-LEFT ELSE
DUP RIGHT-ARROW = IF CURSOR-RIGHT ELSE
DUP UP-ARROW = IF CURSOR-UP ELSE
CURSOR-DOWN
THEN THEN THEN DROP ;
ヒント
同じ重みのブール値を組み合わせて下さい。
二重に入れ子になった IF…THEN 構造の多くの実例では、決定を下す前にフラグを論理演算子と組み合わせることによって単純化することができます。 以下はが二重入れ子のテストです。
: ?PLAY SATURDAY? IF WORK FINISHED? IF
GO PARTY THEN THEN ;
上のコードは入れ子になった IF を使って、土曜日(saturday)と雑用(work)の両方が確実に終了する前に行われるようにしています。 代わりに、条件を論理的に組み合わせて単一の決定をしましょう。
: ?PLAY SATURDAY? WORK FINISHED? AND IF
GO PARTY THEN ;
よりシンプルで読みやすくなっています。
論理的な「or」の状況は、 IF…THEN で実装された場合、さらに厄介です。
: ?RISE PHONE RINGS? IF UP GET THEN
ALARM-CLOCK RINGS? IF UP GET THEN ;
これはもっとエレガントになります。
: ?RISE PHONE RINGS? ALARM RINGS? OR IF UP GET THEN ;
この規則の1つの例外は、いくつかの条件をチェックするための速度的なペナルティが大きすぎる場合です。
私たちが以下のように書いたとします。
: ?CHOW-MEIN BEAN-SPROUTS? CHOW-MEIN RECIPE? AND IF
CHOW-MEIN PREPARE THEN ;
ただし、レシピファイルにそれがあるのかどうかを確認するために、レシピファイルを探すのに長い時間がかかるとします。 冷蔵庫にもやし(bean-sprouts)がなければ、検索を実行しても意味がありません。以下のように書くほうが効率的です。
: ?CHOW-MEIN BEAN-SPROUTS? IF CHOW-MEIN RECIPE? IF
CHOW-MEIN PREPARE THEN THEN ;
私たちはもやし(bean-sprouts)がなければ、レシピを探す必要はありません。
いずれかの語がtrueでない場合は、別の例外が発生します。 最初にこのような条件を排除することで、他の条件を試す必要がなくなります。
ヒント
複数の条件の重みが(ありそうな程度や計算時間で)異なる場合は、条件式を入れ子にします。条件が最も真実であるか、外側で計算するのが最も簡単であると考えます。
このようにしてパフォーマンスを向上させようとするのは、OR構文ではより困難です。
: ?RISE PHONE RINGS? ALARM RINGS? OR IF UP GET THEN ;
電話と時計のアラームをテストしていますが、起動するために呼び出し音を鳴らす必要があるのはどちらか一方だけです。 目覚まし時計が鳴っていることを判断するのがはるかに困難であったとしましょう。 以下のように<書くことができます。
: ?RISE PHONE RINGS? IF UP GET ELSE
ALARM-CLOCK RINGS? IF UP GET THEN THEN ;
最初の条件が当てはまる場合、2番目の条件を評価するのに時間を無駄にしません。 とにかく電話に出なければならない。
UP GET の繰り返しは醜いです。それは OR を使った解決策ほど読みやすくはありませんが、場合によってはその方が好ましいです。
制御構造の選択¶
ヒント
最も洗練されたコードは、問題に最も近いものです。 制御フローの問題に最も近い制御構造を選択してください。
case文¶
特定のクラスの問題は、数値引数に従っていくつかの可能な実行パスのうちの1つを選択することを含みます。 たとえば、ワード .SUIT にトランプのスートを表す数字(0から3まで)を付けて、そのスートの名前を表示させます。 以下の通り入れ子になった IF…ELSE…THEN を使ってこのワードを定義することができます。
: .SUIT ( suit -- )
DUP O= IF ." HEARTS " ELSE
DUP 1 = IF ." SPADES " ELSE
DUP 2 = IF ." DIAMONDS " ELSE
." CLUBS "
THEN THEN THEN DROP ;
「case文」を使用することで、この問題をよりエレガントに解決できます。
これは、同じ定義を「エーカーcase文(Eaker case statement)」書式を使用して書き直したもので、その名前は提案をした紳士のチャールズ・E・エーカー(Charles E. Eaker)博士にちなんで名付けられました。 [eaker]
: .SUIT ( suit -- )
CASE
O OF ." HEARTS " ENDOF
1 OF ." SPADES " ENDOF
2 OF ." DIAMONDS " ENDOF
3 OF ." CLUBS " ENDOF ENDCASE ;
case文の価値は、読みやすさと書きやすさだけにあります。 オブジェクトメモリでも実行速度でも効率の向上はありません。 事実、case文は入れ子になった IF…THEN 文とほとんど同じコードをコンパイルします。 case文はコンパイル時のファクタリング(要素分解)の好例です。
すべてのForthシステムにそのようなcase文を含めるべきでしょうか?それは現在論争中です。 問題は2つあります。 第一に、case文が実際に必要とされる事例はまれであり、その価値に疑問を投げかけるほど稀です。 ごく少数の場合分けしかない場合、入れ子になった IF…ELSE…THEN 構造も同様に動作しますが、おそらく読みやすくはありません。 多くの場合分けがある場合は、決定表の方が柔軟です。
第二に、多くのcase風な問題はcase構造には全く適切ではありません。エーカーのcase文は、スタック上の数に対して同等かどうかをテストしていると仮定しています。 .SUIT の場合、0から3までの連続した整数があります。 整数を使用してオフセットを計算し、正しいコードに直接ジャンプするほうが効率的です。
この章の後半のタイニー・エディタの場合、1つではなく2つの可能性の次元があります。 case文はその問題にも一致しません。
個人的には、case文は、見当違いの問題に対する優雅な解決策であると考えています。それは、決定表でもっと適切に記述できるものをアルゴリズムで表現することです。
case文は、有用な場合はアプリケーションの一部であるべきですが、システムの一部ではありません。
ループ構造¶
正しいループ構造により、余分な条件文を排除できます。
- ムーアは言います。
ループから抜け出すために条件文が使われることがよくあります。 複数の出口を持つループを使うことで、そういう条件文の使用を回避できます。
poly ForthにはあるがForth-83までは浸透していない複数
WHILE構造があるので、これは活きのいい話題です。 同じREPEATの中に複数WHILEを定義する簡単な方法です。また、(Forth社の)ディーン・サンダーソン(Dean Sanderson)は、2つの出口を
DO…LOOPに導入する新しい構文を発明しました。 その構造を考えると、あなたはより少ないテストで済ませる事ができるでしょう。 私はスタックに真理値を残すことが非常に多く、早い時期にループを離れた場合は、早めにループを離れたことを思い出させるように真理値を変更します。 その後に、ループを早く抜けたかどうかを確認するためのIFがありますが、それは不器用です。決断をしたら、もう一度決断する必要はありません。 適切なループ構造を使えば、あなたがどこから来たのか覚えておく必要はないでしょう。
構造化されていないため、これは完全には一般的ではありません。 ひょっとしたら、それは精巧に構造化されているかもしれません。 その価値は、あなたがより簡単なプログラムを手に入れられることです。 そしてそれは無料です。
確かに、これは活きのいい話題です。 これを書いている時点では、新しいループ構成について具体的な提案をするのは時期尚早です。 あなたのシステムのドキュメンテーションを調べて、それがエキゾチックなループ構造の仕方で何を提供しているかを確かめてください。 または、アプリケーションのニーズに応じて、独自の条件付き構成要素を追加することを検討してください。 Forthではそれほど難しいことではありません。
このような複数の出口の使用が構造化プログラミングの原則に違反しないのかどうかさえ私にはわかりません。 複数の WHILE がある BEGIN 、 WHILE 、 REPEAT ループでは、すべての出口が共通の「継続」ポイント、つまり REPEAT に移動します。 しかし、サンダーソンの構文では、 ELSE を続けて、ループの最後を飛び越えてジャンプしてループから抜け出すことができます。 考えられる「継続」ポイントは2つあります。
私たちにそう言うことが許されるならば、これは「あまり構造化されていません」です。 それでも、定義は常にそのセミコロンで終わり、それを呼び出したワードに戻ります。 その意味でそれはうまく構成されています。 モジュールには1つの入口と1つの出口があります。
あなたが途中でループを去らなかった場合だけ特別なコードを実行したいとき、このアプローチは使うべき最も自然な構造のようです(この例については、後の「構造化出口の使用」で説明します)。
ヒント
終端を示すモノよりもカウントを好んで下さい。
Forthは文字列の長さを最初のバイトに保存することで文字列を処理します。 これにより、文字列の入力、移動、など実際何でも簡単になります。 スタック上のアドレスと数で、 TYPE の定義を書くことができます。
: TYPE ( a #) OVER + SWAP DO I C@ EMIT LOOP ;
( TYPE は実際には機械語で書かれるべきですが。)
この定義は明白な条件を使用しません。 各ループはインデックスをチェックし、まだ限界に達していない場合は DO に戻るので、 LOOP は実際には条件を隠します。
区切り文字を使用した場合、それを ASCII NUL(ゼロ)としましょう。定義は次のように書く必要があります。
: TYPE ( a) BEGIN DUP C@ ?DUP WHILE EMIT 1+
REPEAT DROP ;
ループの各パスで追加のテストが必要です( WHILE は条件演算子です)。
最適化に関する注意:この解決法で ?DUP を使うことはそれ自身が特別な決定を含んでいるので時間の点では高価です。 より速い定義は次のようになります。
: TYPE ( a) BEGIN DUP C@ DUP WHILE EMIT 1+
REPEAT 2DROP ;
「FORTH-83規格」は、この原則を終端を示すモノを探すのではなくカウントを受け付ける「INTERPRET」に適用しました。
このコインの裏側は、構造を「リンク」するのが最も簡単なデータ構造です。 各レコードは次の(または前の)レコードを指しています。 チェーン内の最後(または最初)のレコードは、そのリンクフィールドにゼロを付けて示すことができます。
リンクフィールドがある場合は、とにかくそれを取得する必要があります。 あなたは同様にゼロをテストするかもしれません。 レコードがいくつあるかのカウンタを保持する必要はありません。 終了するかどうかを決定するためにカウンターをデクリメントすると、自分で余計な作業を増やすはめになります。 (これは、Forthの辞書をリンクリストとして実装するための手法です。)
計算結果¶
ヒント
決定しないで計算して下さい。
結果の違いが数の違いから生じるような状況では、条件付き制御構造が誤って適用されることがよくあります。 数値が含まれている場合は、それらを計算できます。 ( 第4章 の「計算 対 データ構造 対 ロジック」の節を参照。)
ヒント
ハイブリッド値としてブール値を使用します。
これは、ヒント「決定しないで計算してください」に対する興味深い結果です。コンピュータが数値として表すブール値は、数値的決定に効果的に使用できるということです。 以下は、多くのForthシステムに見られる1つの例です。
: S>D ( n -- d) \ sign extend s to d
DUP O< IF -1 ELSE O THEN ;
(この定義の目的は、1倍長の数値を2倍長に変換することです。2倍長の数値は、スタック上の2つの16ビット値(上位側がスタックトップ側にある)として表されます。正の整数からを2倍長に変換するには、その上位部分を表す為に単にスタックにゼロを追加することを意味します。ただし、負の整数値を倍長に変換するには「符号拡張」が必要です。つまり、高位部分はすべて1にする必要があります。)
上記の定義は、1倍長の数が負かどうかをテストします。 そうであれば、負の値をスタックにプッシュします。 それ以外の場合はゼロです。 しかし、結果は単なる算術演算であることに注意してください。 プロセスに変更はありません。 この事実を利用するには、ブール値そのものを使用します。
: S>D ( n -- d) \ sign extend s to d
DUP O< ;
このバージョンは、ちょっとした決断なしにゼロまたはマイナス1をスタックにプッシュします。
(プレ1983年版のシステムでは、以下のように定義します。
: S>D ( n -- d) \ sign extend s to d
DUP O< NEGATE ;
付録C 参照)
「ハイブリッド値」を使えば、私たちはさらに多くのことができます。
ヒント
数値で結果を決定するには、 AND を使います。
ゼロかゼロでない n を生成する決定の場合、伝統的なフレーズは以下です。
( ? ) IF n ELSE O THEN
以下のより単純な文と同等です。
( ? ) n AND
繰り返しになりますが、その秘密は、「true」がFORTH-83システムでは -1(全てのビットが1)で表されることです。 フラグと AND した n は n (全ビットがそのまま)または 0 (全ビットがクリアされた)を生成します。
言い換えると以下の通り。
( ? ) IF 200 ELSE O THEN
以下とも同じです。
( ? ) 200 AND
この例を見てください。
n a b < IF 45 + THEN
このフレーズは、 a と b の相対サイズに応じて、 n に45を加算するかしないかのどちらかです。 2つの結果の差は純粋に数値です。 私たちは決定を取り除き、単純に計算することができます。
n a b < 45 AND +
- ムーアは言います。
45 ANDはIFよりも速く、明らかに優雅で簡単です。 その値からこの値を計算している実体を探す習慣がある場合は、通常、論理演算を実行することで、同じ結果がよりきれいに得られます。私はあなたがこれを何と呼ぶのかわかりません。 専門用語はありません。 それは単に真理値で算術をしているだけです。 しかし、それは完全に有効であり、いつかブール代数と算術式はそれを収容するでしょう。
本の中では、物事をはっきりと表現するのに失敗する多くの区分的線形近似がよく見られます。 例えば、以下の式です。
x = O for t < O x = 1 for t ≧ O
これは下記と同等です。
t O< 1 AND
断片ではなく、これで完結した単一の表現です。
私はこれらのフラグを「ハイブリッド値」と呼んでいます。なぜなら、それらはデータ(数値)として適用されるブール値(真理値)だからです。 そして私は他に何と呼ぶべきかもわかりません。
2つの結果の差を考慮に入れることで、数値の ELSE 句も削除できます(両方の結果がゼロ以外の場合)。 例えば以下です。
: STEPPERS 'TESTING? @ IF 150 ELSE 151 THEN LOAD ;
これは以下のように単純化できます。
: STEPPERS 150 'TESTING? @ 1 AND + LOAD ;
概念的にはスクリーン150をロードするか、テストする場合は次のスクリーンをロードしたいので、このアプローチはここで機能します。
トリックについて¶
この種のアプローチは「トリック」と呼ばれることがよくあります。コンピューティング業界全般では、トリックの評判はよくありません。
トリックは単に操作の特定の特性を利用しています。 トリックはエンジニアリングアプリケーションで広く使われています。 煙突は熱が上がるという事実を利用して煙を排除します。自動車タイヤは重力を利用して牽引力を発揮します。
算術論理演算装置(ALU)は、数値を減算することがその2の補数を追加することと同じであるという事実を利用します。
これらのトリックは、よりシンプルで効率的なデザインを可能にします。 それらの使用を正当化するのは、仮定が真実であり続けることが確実であるということです。
トリックが変更される可能性があるものに依存している場合、またはそれが依存しているものが情報の隠蔽によって保護されていない場合、トリックの使用は危険になります。
また、トリックが基になっている前提が理解または説明されていない場合、トリックは読みにくくなります。 条件文を AND に置き換える場合、この技法がすべてのプログラマの常識になれば、コードはもっと読みやすくなるでしょう。 データがテーブルに配置される順序など、特定のアプリケーションに固有のトリックの場合、リストにはそのトリックで使用されている前提が明確に文書化されている必要があります。
ヒント
MIN と MAX を切り取る為に使って下さい。
変数 VALUE の内容を減算したいが、値がゼロ以下にならないようにしたいとします。
-1 VALUE +! VALUE @ -1 = IF O VALUE ! THEN
これはもっとシンプルに書けます。
VALUE @ 1- O MAX VALUE !
この場合、条件はワード MAX の中でファクタリング(要素分解)されます。
決定表の使用¶
ヒント
決定表を使って下さい。
私たちは、それらを 第2章 で紹介しました。 決定表は、データ(データ表))または機能のアドレス(機能表)のいずれかを任意の次元数に従って配置した構造です。 各次元は、問題の特定の側面のすべての可能な相互排他的な状態を表します。 各次元の「真(true)」の状態の交差点に、目的の要素、つまり実行されるデータまたは機能があります。
問題に複数の次元がある場合、決定表は明らかに条件付き構造よりも優れた選択です。
1次元データ表¶
これは、単純な1次元のデータ表の例です。 このアプリケーションには、 FREEWAY? というフラグがあります。これは、高速道路を参照している場合はtrue、一般道を参照している場合はfalseです。
現在の状態に応じて制限速度を返す SPEED-LIMIT というワードを作成しましょう。 IF…THEN を使って書きます。
: SPEED-LIMIT ( -- speed-limit)
'FREEWAY? @ IF 55 ELSE 25 THEN ;
私たちは AND とのハイブリッド値を使うことで IF…THEN を削除するかもしれません。
: SPEED-LIMIT 25 'FREEWAY? @ 30 AND + ;
しかし、このアプローチは問題の概念モデルと一致しないため、読みやいというわけではありません。
データ表を試してみましょう。 以下は、2つの要素しかない1次元の表です。
CREATE LIMITS 25 , 55 ,
SPEED-LIMIT? というワードは、データ表へのオフセットにブール値を適用する必要があります。
: SPEED-LIMIT ( -- speed-limit)
LIMITS 'FREEWAY? @ 2 AND + @ ;
私たちは IF…THEN アプローチを超える何かを得ましたか?たぶん無かったでしょう。この単純な問題では。
ただし、これまでに行ったことは、データ自体から意思決定プロセスを括り出すことです。 同じ決定に関連するデータが複数ある場合、これはより費用対効果が高くなります。 また、私たちは以下のように、
CREATE #LANES 4 , 10 ,
一般道および高速道路の車線数を表します。 現在の車線数を計算するために同じコードを使うことができます。
: #LANES? ( -- #lanes)
#LANES 'FREEWAY? @ 2 AND + @ ;
ファクタリング(要素分解)の手法を適用して、これを次のように単純化します。
: ROAD ( for-freeway for-city ) CREATE , ,
DOES> ( -- data ) 'FREEWAY? @ 2 AND + @ ;
55 25 ROAD SPEED-LIMIT?
10 4 ROAD #LANES?
一次元データテーブルの他の例は、「超文字列(superstring)」です( Starting Forth, Chapter Ten;邦訳 FORTH入門 第10章 P.309)。
2次元データ表¶
第2章 では、電話料金の問題を紹介しました。 リスト 17 は二次元データ構造を使った問題の解決法の一つです。
電話料金の問題に居対する解決策
0 1 2 3 4 5 6 7 8 9 10 11 | \ Telephone rates 03/30/84
CREATE FULL 30 , 20 , 12 ,
CREATE LOWER 22 , 15 , 10 ,
CREATE LOWEST 12 , 9 , 6 ,
VARIABLE RATE \ points to FULL, LOWER or LOWEST
\ depending on time of day
FULL RATE ! \ for instance
: CHARGE ( o -- ) CREATE ,
DOES> ( -- rate ) @ RATE @ + @ ;
O CHARGE 1MINUTE \ rate for first minute
2 CHARGE +MINUTES \ rate for each additional minute
4 CHARGE /MILES \ rate per each 100 miles
|
0 1 2 3 4 5 6 7 8 9 | \ Telephone rates 03/30/84
VARIABLE OPERATOR? \ 90 if operator assisted; else O
VARIABLE #MILES \ hundreds of miles
: ?ASSISTANCE ( direct-dial charge -- total charge)
OPERATOR? @ + ;
: MILEAGE ( -- charge ) #MILES @ /MILES * ;
: FIRST ( -- charge ) 1MINUTE ?ASSISTANCE MILEAGE + ;
: ADDITIONAL ( -- charge) +MINUTES MILEAGE + ;
: TOTAL ( #minutes -- total charge)
1- ADDITIONAL * FIRST + ;
|
この問題では、データ表の各次元は3つの相互に排他的な状態で構成されています。 したがって、単純なブール値(true/false)では不十分です。 この問題の各次元は、異なる方法で実装されています。
現在のレートは、時刻によって異なり、アドレスとして格納され、3つのレート構造補助表のうちの1つを表します。 私たちは以下のように言う事ができます。
FULL RATE !
または
LOWER RATE !
など。
現在の料金は、最初の1分、追加の1分、またはマイルあたりのいずれかで、テーブルへのオフセットとして表されます(0、2、または4)。
最適化に関する注意:2次元テーブルを、それぞれ RATE が指す3つの1次元テーブルの組として実装しました。 このアプローチは、そうでなければ二次元構造を実施するために必要とされるであろう乗算の必要性を排除します。 ある場合には乗算が非常に遅くなることがあるためです。
2次元決定表¶
私たちは2次元の決定表を説明するために、 第3章 のタイニー・エディタの例に戻りましょう。
リスト 19 では、さまざまなキーが押されたときに実行される機能のテーブルを作成しています。 効果はcaseステートメントの効果と似ていますが、2つのモード、通常モードと挿入モードがあります。 各キーは、現在のモードによって異なる動作をします。
最初のスクリーンはモードの変更を実行します。以下を呼び出すと、
NORMAL MODE# !
通常モードに入ります。
INSERTING MODE# !
で、挿入モードに入ります。
次のスクリーンは FUNCTIONS と呼ばれる機能テーブルを構築します。 このテーブルは、キーのASCII値と、それに続くノーマルモードのときに実行されるルーチンのアドレス、およびそのキーが押されたときに挿入モードのときに実行されるルーチンのアドレスで構成されます。 次に2番目のキーが続き、その後に次のアドレスのペアが続きます。
3つ目のスクリーンでは、 FUNCTION というワードがキー値を取り、 FUNCTIONS 表を検索して一致するものを探し、その一致を含むセルのアドレスを返します(表最終行を指すように変数 MATCHED を設定しました。任意の文字が押されたときに必要な機能です)。
ACTION というワードは、 FUNCTION を呼び出し、次に変数 MODE# の内容を追加します。 MODE# には2または4のいずれかが含まれるので、このオフセットを追加することで、実行したいルーチンのアドレスでテーブルを参照しています。 以下のようにシンプルに実行できます。
@ EXECUTE
こうしてルーチンを実行します(または、もしあれば @EXECUTE )。
fig-Forthでは、 IS の定義を次のように変更します。
: IS [COMPILE] ' CFA , ;
タイニー・エディタの実装
0 1 2 3 4 5 6 7 8 9 10 | \ Tiny Editor
2 CONSTANT NORMAL \ offset in FUNCTIONS
4 CONSTANT INSERTING \ "
6 CONSTANT /KEY \ bytes in table for each key
VARIABLE MODE# \ current offset into table
NORMAL MODE# !
: INSERT-OFF NORMAL MODE# ! ;
: INSERT-ON INSERTING MODE# ! ;
VARIABLE ESCAPE? \ t=time-to-leave-loop
: ESCAPE TRUE ESCAPE? ! ;
|
0 1 2 3 4 5 6 7 8 9 10 11 | \ Tiny Editor function table 07/29/83
: IS ' , ; \ function ( -- ) ( for '83 standard)
CREATE FUNCTIONS
\ keys normal mode insert mode
4 , ( ctrl-D) IS DELETE IS INSERT-OFF
9 , ( ctrl-I) IS INSERT-ON IS INSERT-OFF
8 , ( backspace) IS BACKWARD IS INSERT<
60 , ( left arrow) IS BACKWARD IS INSERT-OFF
62 , ( right arrow) IS FORWARD IS INSERT-OFF
27 , ( return) IS ESCAPE IS INSERT-OFF
O , ( no match) IS OVERWRITE IS INSERT
HERE /KEY - CONSTANT 'NOMATCH \ adr of no-match key
|
0 1 2 3 4 5 6 7 | \ Tiny Editor cont'd 07/29/83
VARIABLE MATCHED
: 'FUNCTION ( key -- adr-of-match ) 'NOMATCH MATCHED !
'NOMATCH FUNCTIONS DO DUP I @ = IF
I MATCHED ! LEAVE THEN /KEY +LOOP DROP
MATCHED @ ;
: ACTION ( key -- ) 'FUNCTION MODE# @ + @ EXECUTE ;
: GO FALSE ESCAPE? ! BEGIN KEY ACTION ESCAPE? @ UNTIL ;
|
FORTH-79規格では以下の定義を使います。
: IS [COMPILE] ' , ;
私たちは、機能テーブル用の定義では、コンパイル時の非冗長性も使用しました。
HERE /KEY - CONSTANT 'NOMATCH \ adr of no-match key
機能テーブルの最後の行から定数を作ります(現時点では、 HERE を呼び出すと、最後のテーブルエントリが埋められた後、次の空きセルを指しています。最後の行はその6バイト前です)。私たちは今や2つのワードを持っています。
FUNCTIONS ( adr of beginning of function table )
'NOMATCH ( adr of "no-match" row; these are the
routines for any key not in the table)
これらの名前を使って、 DO に渡されるアドレスを提供します。
'NOMATCH FUNCTION DO
表の最初の行から最後の行まで実行するループを設定します。 テーブルに何行あるかを知る必要はありません。 表を検索するコードであっても、他のコードを変更することなく、行を削除したり表に行を追加したりすることさえ可能です。
同様に、定数 /KEY は表の列数に関する情報を隠します。
ちなみに、リストの中で採用されている FUNCTION へのアプローチは、手早く簡便にやるためのものです。 スタック操作を簡単にするためにローカル変数を使用します。 ローカル変数を使用しない簡単な解決策は次のとおりです。
: 'FUNCTION ( key -- adr of match )
'NOMATCH SWAP 'NOMATCH FUNCTIONS DO DUP
I @ = IF SWAP DROP I SWAP LEAVE THEN
/KEY +LOOP DROP ;
(この章の後半の「構造化出口の使用」で、さらに別の解決策を提案します)。
スピードの為の決定表¶
表で調べるのではなく、値を計算できる場合は、それを実行する必要があると述べました。 例外は、スピードに対する要求がテーブルの複雑さをさらに正当化する場合です。
以下に、2から8ビット精度の累乗を計算する例を示します。
CREATE TWOS
1 C, 2 C, 4 C, 8 C, 16 C, 32 C,
: 2** ( n -- 2-to-the-n)
TWOS + C@ ;
2をn回掛け算して答えを計算する代わりに、答えはすべて事前に計算されて表に配置されます。 単純な加算を使用して表にオフセットし、答えを得ることができます。
一般に、加算は乗算よりもはるかに高速です。
- ムーアは別の例を示しています。
例えばグラフィックディスプレイのためにトリガ関数を計算したいのであれば、それほど解像度は必要ありません。 7ビットのトリガ関数はたぶんたくさんあります。 128の数字のテーブル検索は、あなたができるだろう他の何よりも速いです。 低頻度関数の計算には、決定表が最適です。
しかし、補間しなければならない場合は、とにかく関数を計算する必要があります。 少々複雑でも関数を計算し、表検索を避ける方がマシでしょう。
再設計¶
ヒント
一番底の1つの変更は、一番上の10の決定を節約することができます。
この章の冒頭のムーアとのインタビューの中で、彼は1つではなく2つのワードがあるように再設計された場合、多くの条件付きテストがアプリケーションから削除される可能性があると述べました。 「あなたは GO と言うか、あるいは PRETEND と言うかです。」
固定環境を維持しながら複数のアルゴリズムから選択するよりも、環境のコンテキストを変更しながら単純で一貫性のあるアルゴリズムを実行する方が簡単です。
第1章 の私たちのワード APPLES の例を思い出してください。 これはもともと変数として定義されていました。 アプリケーション全体で、出荷数が増えたときにリンゴの数を増やし、(リンゴが販売されたときに)数を減らし、在庫管理のために現在の数をチェックするというワードで、アプリケーションを通して何度も呼ばれました。
2番目のタイプのリンゴを扱う必要があるとき、「間違った」アプローチはすべての出荷・販売・在庫のワードにその複雑さを加えることでした。 「正しい」アプローチは、私たちがとったアプローチでした。 つまり、APPLES自体にその複雑さを加えることでした。
この原則はさまざまな方法で実現できます。 第7章 (「状態テーブル」)では、状態テーブルを使って、ワード WORKING と PRETENDING を実装していましたが、変数のグループの意味が変わりました。 その章の後半では、 TYPE 、 EMIT 、 SPACES 、 SPACES 、 CR の意味を変更するために、 VISIBLE と INVISIBLE の定義でベクトル実行を使用しました。それにより、それを使うすべてのフォーマットコードを簡単に変更できます。
ヒント
起こり得ないことをテストしないでください。
同年代のプログラマの多くはエラーチェックに満足しています。
システム内の他のコンポーネントによって渡された引数をチェックする機能は必要ありません。 呼び出し側プログラムは、呼び出されたコンポーネントの制限を超えないようにする責任を負うべきです。
ヒント
アルゴリズムを見直してください。
- ムーアは言います。
問題についてのあいまいな思考から、多くの条件が発生します。 サーボ制御理論では、サーボのアルゴリズムは、距離の大小によって異なるはずであると考えられてています。 はるか遠くでは、slewモードです。ターゲットに近づくと減速モードです。直近に迫るとハントモードです。どのぐらいの距離でどのアルゴリズムを適用する必要があるか知るためのテストをする必要があります。
私はフルレンジを処理する非線形サーボ制御アルゴリズムを考え出しました。 この手法は、一方のモードと他方のモードとの間の遷移点における不具合を解消する。 どのアルゴリズムを使用するかを決定するために必要なロジックを取り除きます。 経験的に遷移点を決定する必要がなくなります。 そしてもちろん、3つではなく1つのアルゴリズムを使った、はるかに単純なプログラムがあります。
条件文を取り除こうとする代わりに、条件文を導いた根底にある理論を疑問視するのが最善です。
ヒント
特別な取り扱いの必要性を避けて下さい。
この本の最初の部分で例を挙げました。ユーザがトラブルに巻き込まれないようにするには、ユーザがトラブルに陥ったかどうかを継続的にテストする必要はありません。
- ムーアは言います。
別の良い例はアセンブラを書くことです。 オペコードにはレジスタが関連付けられていない場合でも、レジスタが0のように見せかけるとコードが単純化される可能性がよくあります。 存在する必要がないビットパターンを導入することによって算術演算を実行することは、解決策を単純化する。 ゼロを代入して、ゼロをテストしてそれを行わないことで避けた可能性がある算術を続けます。
それは「どうでもいい」の別の例です。 気にしない場合は、ダミーの値を指定してとにかく使用してください。
特別なケースに遭遇したときはいつでも、特別なケースが通常のケースになるようなアルゴリズムを見つけるようにしてください。
ヒント
コンポーネントの性質を利用してください。
適切に設計されたコンポーネント(ハードウェアまたはソフトウェア)を使用すると、対応する用語集をクリーンで効率的な方法で実装できます。 古いエプソンMX-80プリンタ(現在は廃止されています)の文字グラフィックセットは、その点をよく表しています。 図 59 はASCIIコード160から223で生成されたグラフィック文字を表示します。

図 59 エプソンMX-80グラフィック文字
各グラフィック文字は、塗りつぶされているか空白のままになっている6つの小さなボックスの異なる組み合わせです。 私たちのアプリケーションで、デザインを作成するためにこれらの文字を使いたいとしましょう。 各文字について、6つの位置のそれぞれに何が必要かを知っています。プリンタに適切なASCII文字を送る必要があります。
少し見てみると、非常に賢明なパターンであることがわかります。 各バイトがパターン内のピクセルを表す6バイトのテーブルがあるとします。
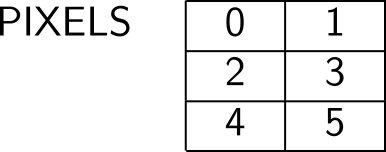
ピクセルが「オン」の場合、各バイトに16進数のFFが含まれ、「オフ」の場合はゼロになり、文字を計算するのに必要なコードは以下のようになります。
CREATE PIXELS 6 ALLOT
: PIXEL ( i -- a ) PIXELS + ;
: CHARACTER ( -- graphics character)
160 6 O DO I PIXEL C@ I 2** AND + LOOP ;
(私たちは 2** をちょっと前に紹介しました。)
CHARACTER の定義に決定は必要ありません。 グラフィック文字は単純に計算されます。
注:同じグリッドを使用して大きなグリッド内の6つの隣接ピクセルのセットを変換するには、単にPIXELを再定義するだけです。 これは、間接参照を逆方向に追加し、優れた分解をした例です。
残念ながら、外付け部品は必ずしもうまく設計されていません。 たとえば、IBMパーソナルコンピュータは、ビデオディスプレイ上のグラフィックス文字に同様の仕組みを使用していますが、ASCII値とピクセルのパターンとの間に明確な対応はありません。 ASCII値を生成する唯一の方法は、ルックアップ表のパターンを照合することです。
- ムーアは言います。
- 68000アセンブラは、最小限の演算子でこれらの命令コードを表現するための優れた方法を探して、あなたをひどく失望させるもう1つの例です。 すべての証拠は良い解決策がないことを示唆しています。 68000を設計した人々は、アセンブラを念頭に置いていませんでした。 そしてそれら自身にコストをかけずに、物事をはるかに簡単にすることができました。
このようにコンポーネントの性質を使用することで、コードはそれらの性質、つまりコンポーネント自体に依存するようになります。 ただし、すべての依存コードは1つの用語集に限定されているため、必要に応じて簡単に変更できます。
構造化出口の使用¶
ヒント
構造化された出口を使って下さい。
ファクタリング(要素分解)の章で、以下の手法を使って制御構造をファクタリング(要素分解)することの可能性を示しました。
: CONDITIONALLY A B OR C AND IF NOT R> DROP THEN ;
: ACTIVE CONDITIONALLY TUMBLE JUGGLE JUMP ;
: LAZY CONDITIONALLY SIT EAT SLEEP ;
Forthでは、リターンスタックを直接操作することで制御フローを変更することができます(疑問がある場合は、Starting Forth, Chapter Nine;邦訳 FORTH入門 第9章 を参照してください)。このトリックを不当に適用すると、厄介な副作用を伴う構造化されていないコードが生成される可能性があります。 しかし、構造化出口の規則正しい使用は実際にコードを単純化し、それによって読みやすさと保守性を向上させることができます。
- ムーアは言います。
私は制御の流れを変えるために
R> DROPをますます支持するようになりました。 それはIF…THENが組み込まれているABORT"の効果に似ています。しかしそれはシステム内のただ一つのIF…THENであり、全てのエラーではありません。アボートするかアボートしないかのどちらかです。 アボートしない場合は続行します。 中止しても、残りの経路を通る必要はありません。 全体を短絡します。
別の方法は、エラーが発生したかどうかをチェックすることで、アプリケーションの残りの部分に負担をかけることです。それは不便です。
「アボート・ルート」は、特別な条件下での制御フローの通常の経路を回避します。 Forthはこの機能を ABORT" と QUIT というワードで提供しています。
「構造化出口」は、アプリケーション全体を終了させることなく、単一のワードを即座に終了させることによって概念を拡張します。
この手法をGOTOの使用と混同しないでください。GOTOは極端には構造化されていません。 GOTOを使用すると、現在のモジュールの内側または外側のどこにでも移動できます。 このテクニックを使用すると、モジュールの最後の終了点(セミコロン)に直接ジャンプして呼び出し元のワードの実行を再開できます。 EXIT というワードは、そのワードを記述した定義を終了させます。 R> DROP というフレーズは、そのフレーズが現れる定義を呼び出した定義を終了させます。 したがって、同じ効果がありますが、1つ下のレベルで使用できます。 以下に両方のアプローチのいくつかの例があります。
以下のように、コードが THEN に続かない IF…ELSE…THEN フレーズがあるとします。
... HUNGRY? IF EAT-IT ELSE FREEZE-IT THEN ;
EXIT を使うことで ELSE を消すことができます。
... HUNGRY? IF EAT-IT EXIT THEN FREEZE-IT ;
(条件が真であれば、EAT-IT して EXIT します。 EXIT はセミコロンのように振る舞います。条件が偽であれば、 THEN FREEZE-IT に遷移します。)
ここでの EXIT の使用はより効率的で、実行するために2バイトと余分なコードを節約しますが、読みやすくはありません。
- ムーアはこのテクニックの価値と危険性についてコメントしています。
特にあなたの条件文が精巧になっているならば、最後にすべてのあなたの
THENにマッチする必要なしに真ん中から飛び出すのは便利です。 あるアプリケーションでは、私はこのようなワードを書いていました。: TESTING SIMPLE 1CONDITION IF ... EXIT THEN 2CONDITION IF ... EXIT THEN 3CONDITION IF ... EXIT THEN ;
SIMPLE「単純」は単純なcaseを扱います。SIMPLEはR> DROPで終わります。 これらの他の条件はより複雑なものでした。すべての
IF、ELSE、THENに完璧に一致させることなく、どれもが同じ時点で終了しました。 どの条件にも一致しない場合、最終結果はエラー条件でした。コードが悪く、デバッグが困難でした。 しかし、それは問題の本質を反映していました。 それを処理するためのより良い方式はありませんでした。
EXITとR> DROPは少なくとも物事を扱いやすくしています。
プログラマは時々複雑な BEGIN ループから抜け出すために EXIT を使うこともあります。 あるいは、この章の前半で、私たちのタイニー・エディタで FUNCTION のために書いた DO…LOOP の中で関連テクニックを使うかもしれません。 このワードでは、私たちは一致する箇所を見つける一連の場所を探索しています。一致が見つかった場合は、見つかった場所のアドレスを返します。 一致するものが見つからない場合は、機能テーブルの最後の行のアドレスが必要です。
私たちは LEAP というワードを導入することができます( 付録C 参照)、これは EXIT のように動作します(セミコロンをシミュレートします)。 今や私たちは以下の通り書くことができます。
: 'FUNCTION ( key -- adr-of-match )
'NOMATCH FUNCTIONS DO DUP I @ = IF DROP I LEAP
THEN /KEY +LOOP DROP 'NOMATCH ;
一致が見つかった場合は、 +LOOP ではなく LEAP になりますが、定義からはみ出して I (見つかったアドレス)がスタックに残ります。 一致が見つからない場合は、ループを抜けて実行します。
DROP 'NOMATCH
これにより、検索されている key# (キー・ナンバー) スタックから捨てられ、最後の行のアドレスが残ります。
これまで見てきたように、複数の出口ポイントや複数の「継続(continue)」ポイントであっても、早まった出口が適切な場合があります。
ただし、この EXIT および R> DROP の使用は、最も厳密な意味での構造化プログラミングとは一貫していないので注意が必要です。
たとえば、定義の最初にスタックの値があり、それが最後に消費されることがあります。 早まった EXIT は、スタックに不要な値を残します。
リターンスタックでふざけるのは火遊びするようなものです。 やけどをする可能性があります。 しかし、火はとても便利です。
良いタイミングの採用¶
ヒント
後でではなく、必要があるとわかったときに行動を起こしてください。
フラグを立てるときはいつでも、なぜフラグを立てるのかを自問してください。 答えが「そういうことを後でやることを知っている」と答えたら、あなたがそのようなことができるようになったかどうか自問してみましょう。 少し構造を変更するだけで、設計を大幅に簡素化できます。
ヒント
今日コンパイルできるものを実行時まで延期しないでください。
アプリケーションをコンパイルする前にあなたはいつでも決定を下すことができます。
2つのバージョンの配列があるとします。1つは開発中に境界チェックの保護を行ったもの、もう1つは実行速度が速いけど、実際のアプリケーションでは保護されていないものです。
2つのバージョンを別々のスクリーンに入れてください。 アプリケーションをコンパイルするときは、必要なバージョンだけをロードしてください。
ちなみに、この提案に従えば、毎回ロードされるバージョンを変更するためにロードブロックの内外に括弧 ( …) を編集することになるかもしれません。 代わりに、あなたに代わって決定を下すための使い捨ての定義を書いてください。 例えば(既に別の文脈でプレビューされているように)以下の通り。
: STEPPERS 150 'TESTING? @ 1 AND + LOAD ;
ヒント
DUP はフラグです。再作成しないでください。
前のコードが呼び出されたかどうかを示すフラグが必要な場合があります。 次の定義は DO-IT が行われたことを示すフラグを残します。
: DID-I? ( -- t=I-did)
SHOULD-I? IF DO-IT TRUE ELSE FALSE THEN ;
これは次のように単純化できます。
: DID-I? ( -- t=I-did)
SHOULD-I? DUP IF DO-IT THEN ;
ヒント
フラグを設定せずにデータを設定してください。
フラグを設定する唯一の目的が、後で、ある数か別の数かを決定できるようにすることである場合は、その数自体を保存することをお勧めします。
第6章 の「ファクタリング(要素分解)基準」節の「色の例」はこの点を示しています。
LIGHT というワードの目的は、輝度ビットを設定するかどうかを示すフラグを設定することです。 私たちは以下のように書きます。
: LIGHT TRUE 'LIGHT? ! ;
フラグをセットするために、そして
'LIGHT? @ IF 8 OR THEN ...
このフラグを使用するために、このアプローチは輝度ビットマスク自体を変数に入れるほど単純ではありません。
: LIGHT 8 'LIGHT? ! ;
それから単純にします。
'LIGHT? @ OR ...
それを使用する。
ヒント
フラグを設定しないで、機能(ベクトル)を設定してください。
このヒントは前のものと似ており、同じ制限の下にあります。 フラグを設定する唯一の目的が、後であるコードが、ある機能か別の機能かを決定できるようにすることである場合は、関数自体のアドレスを保存した方がよいでしょう。
たとえば、文字をプリンタに送信するためのコードは、文字をビデオディスプレイに表示するためのコードとは異なります。 不適切な実装では、次のように定義されます。
VARIABLE DEVICE ( O=video | 1=printer)
: VIDEO FALSE DEVICE ! ;
: PRINTER TRUE DEVICE ! ;
: TYPE ( a # -- ) DEVICE @ IF
( ...code for printer...) ELSE
( ...code for video...) THEN ;
文字列を入力するたびにどの機能を実行するかを決めているので、これは良くありません。
好ましい実装は、ベクトル実行を使用します。 たとえば以下の通りです。
DOER TYPE ( a # -- )
: VIDEO MAKE TYPE ( ...code for video...) ;
: PRINTER MAKE TYPE ( ...code for printer...) ;
TYPE はどのコードを使用するかを決定する必要がないので、これはより優れています、それはすでにどうするか知っているわけです。
(マルチタスクシステムでは、プリンタータスクとモニタータスクはそれぞれ、ユーザー変数に格納されている TYPE の実行ベクトルの独自のコピーを持ちます。)
上記の例もこのヒントの制限を示しています。 2番目のバージョンでは、現在のデバイスがプリンタなのかビデオスクリーンなのかを知る簡単な方法はありません。 たとえば、画面をクリアするか改ページを発行するかを判断する必要があるかもしれません。 それから私たちは状態(state)をさらに利用しており、私たちの規則はもはや適用されません。
フラグは、実際には、追加の状態依存操作の最も簡単な実装を可能にします。 しかし、 TYPE の場合、スピードが心配です。 文字列は頻繁に入力するので、時間を無駄にする余裕はありません。 ここでの最善の解決策は、 TYPE の機能を設定し、さらにフラグを設定することです。
DOER TYPE
: VIDEO O DEVICE ! MAKE TYPE
( ...code for video...) ;
: PRINTER 1 DEVICE ! MAKE TYPE
( ...code for printer...) ;
これにより、 TYPE は実行するコードを既に知っていますが、他の定義はフラグを参照します。
他の可能性は、 DOER のワード TYPE のパラメータ(現在のコードへのポインタ)を取得し、それを PRINTER のアドレスと比較するワードを書くことです。 もしそれが PRINTER のアドレスより小さければ、 VIDEO ルーチンを使っています。 そうでなければ、 PRINTER ルーチンを使っています。
状態を変えることが少数の機能を変えることを含むなら、あなたはまだ DOER/MAKE を使うことができます。 以下は、一緒に遮断できる3つのメモリ移動演算子の定義です。
DOER !' ( vectorable ! )
DOER CMOVE' ( vectorable CMOVE )
DOER FILL' ( vectorable FILL )
: STORING MAKE !' ! ;AND
MAKE CMOVE' CMOVE ;AND
MAKE FILL' FILL ;
: -STORING MAKE !' 2DROP ;AND
MAKE CMOVE' 2DROP DROP ;AND
MAKE FILL' 2DROP DROP ;
しかし、多数の関数をベクトル化する必要がある場合は、状態表を使用することをお勧めします。
この規則の当然の結果として、構造化終了を実行するようにベクトル化された「構造化終了フック( DOER )」が導入されています。
DOER HESITATE ( the exit hook)
: DISSOLVE HESITATE FILE-DIVORCE ;
(…それを MAKE する部分はリストのかなり後の方にあります。)
: RELENT MAKE HESITATE SEND-FLOWERS R> DROP ;
デフォルトでは、 HESITATE は何もしません。 私たちが DISSOLVE を呼び出すと、法廷で終わることになります。 しかし、DISSOLVE の前に RELENT を入力した場合は、花を送信してからセミコロンに移動し、パートナーがこれを見つける前にその裁判所の命令を取り消します。
このアプローチは、リストの最後の方で定義されている機能によって取り消しを実行する必要がある場合に特に適しています(順次複雑度による分解)。 以前のコードの複雑さが増すのは、フックを定義して適切な場所で呼び出すことだけに限られていました。
単純化¶
このヒントは、簡潔さを選択したことによる見返りを示しているので、最後にしました。他のヒントは保守性、パフォーマンス、コンパクトさなどに関係しますが、このヒントは思想家のソーローがウォールデン池に求めたある種の満足度に関連しています。
ヒント
フラグをメモリに完全に保存するのを避けることを試みて下さい。
スタック上のフラグは、メモリ内のフラグとはまったく異なります。 スタック上のフラグは(ハードウェアの読み取り、計算などによって)簡単に決定され、スタックにプッシュされてから、制御構造によって消費されます。曲折のない短い人生です。
しかし、フラグをメモリに保存して何が起こるのか見てください。 フラグ自体を持っていることに加えて、あなたは今フラグのための場所の複雑さを持っています。 場所では以下のようにしなければなりません。
- 生成
- 初期化(実際に何かが変更されるじゅうぶん前に)
- リセット(それ以外の場合、コマンドにフラグを渡すと、そのフラグは現在の状態のままになります)
メモリ内のフラグは変数なので、再入可能ではありません。
フラグの必要性を再考する可能性がある場合の例としては、すでに数回見たことがあります。 「色」の例では、私たちは最良の構文は次のようになると仮定しました。
LIGHT BLUE
つまり、色の前にある形容詞の LIGHT です。 いいですね。 しかし、そのバージョンを実装するためのコードを覚えていますか? 以下のアプローチの単純さと比較してください。
O CONSTANT BLACK 1 CONSTANT BLUE 2 CONSTANT GREEN
3 CONSTANT CYAN 4 CONSTANT RED 5 CONSTANT MAGENTA
6 CONSTANT BROWN 7 CONSTANT GRAY
: LIGHT ( color -- color ) 8 OR ;
このバージョンでは、構文を逆にしたので、以下のようになります。
BLUE LIGHT
私たちは色を設定してから色を変更します。
完了したら、変数からコードを取得し、変数をリセットするためのコードを追加する必要がなくなりました。 そしてコードはとても単純なので理解できないでいるのは不可能です。
これらのコマンドを最初に書いたとき、私は英語として自然に見えるようなアプローチを取った。 BLUE LIGHT は後ろ向きに聞こえ、まったく受け入れられませんでした。それは私がチャック・ムーアと会話する前の話です。
- ムーアの哲学は説得力があります。
私は「英語で素敵に読めること」と「素敵に読めること」を区別します。 スペイン語などの他の言語では、形容詞は名詞に従います。 私たちは自分が考えている言語のような詳細からは独立しているべきです。
それはあなたの意図によります。単純さ、または英語のエミュレーション。 英語は私たちが卑屈な態度で従うべきであるほど素晴らしい言語ではありません。
グラフィックアーティスト向けのパッケージで私の「色」のワードを売っているのであれば、フラグを立てるのに手間を掛けてください。しかし、これらの言葉を自分のために書いて、もう一度やり直さなければならないのであれば、ムーア風に BLUE LIGHT を使ってください。
要約¶
プログラミングにおいて重要な構造要素として論理と条件を使用すると、過度に複雑で保守が困難で効率の悪いコードになります。 この章では、不要な条件付き構造を最小化、最適化、または削除するためのいくつかの方法について説明しました。
最後の注意として、Forthの条件文の軽視は現代のほとんどの言語で共有されていません。 実際、日本人は第5世代のコンピュータプロジェクトを、ロジックでのプログラミングのためのPROLOGと呼ばれる言語に基づいています。 私たちが質問を熟考する間に共同戦線が張られるのを見るのは面白そうです。
ToIFor not toIF
この本では、ソフトウェア開発サイクルの最初の6つのステップを取り上げ、ソフトウェア設計の哲学的問題と、堅牢で効率的で読み取り可能なソフトウェアを実装する際の実際的な考慮事項の両方について説明しました。
最適化、検証、デバッグ、文書化、プロジェクト管理、Forth開発ツール、アセンブラ定義、再帰の使用と悪用、マルチプログラムアプリケーションの開発、またはターゲットコンパイルについては説明していません。
しかし、それはまた別の物語です。
さらなる思考のために¶
入力引数がゼロ以外の正数、負数、またはゼロであるかどうかに応じて、それぞれ1または-1または0を返すワード DIRECTION を定義してみましょう。